达观OCR图像文字抽取算法平台满足业务场景快速定制
人工智能在当下已经不再是新潮的概念,在下一代技术跃进出现之前,业务场景的落地比让人眼花缭乱的技术名词更具备现实价值。对于大部分企业客户,业务部和技术部之间的相互依赖关系共同促进了技术在内部的使用,业务需求和技术能力相辅相成。OCR技术能够把光学文字转变为计算机字符,但对于文本和数据处理工作,将纸质文档上的数据通过人工智能技术变成计算机结构化数据,则能更有效地搭建知识桥梁,将人力从重复的人工录入转移到非重复的数据分析,产生更深层次的业务价值。


抽取模块

- 内置模型抽取;集成自研的标准化识别产品,包括多种小语种识别和数十种常见卡证抽取。
- 模版抽取-简单易用的模版标注;采用多种标注方式,支持锚点和无锚点标注,快速准确抓取目标信息。
- 模型抽取;应用最新多模态和集成算法,表现出高鲁棒性和良好的泛化性。
- 分类器识别;分类器作为一个平台功能的技术定义,在实际使用中对应我们的业务流场景,实现的功能是对打包或批量上传的单据数据完成自动分类抽取,并进一步定义审核校验等业务属性。通过定义分类规则或训练专研的分类器模型,关联对应抽取文档,构成一个分类器识别单元。常见的业务流诸如银行开户业务流、企业资质审查业务流等。
抽取结果展示
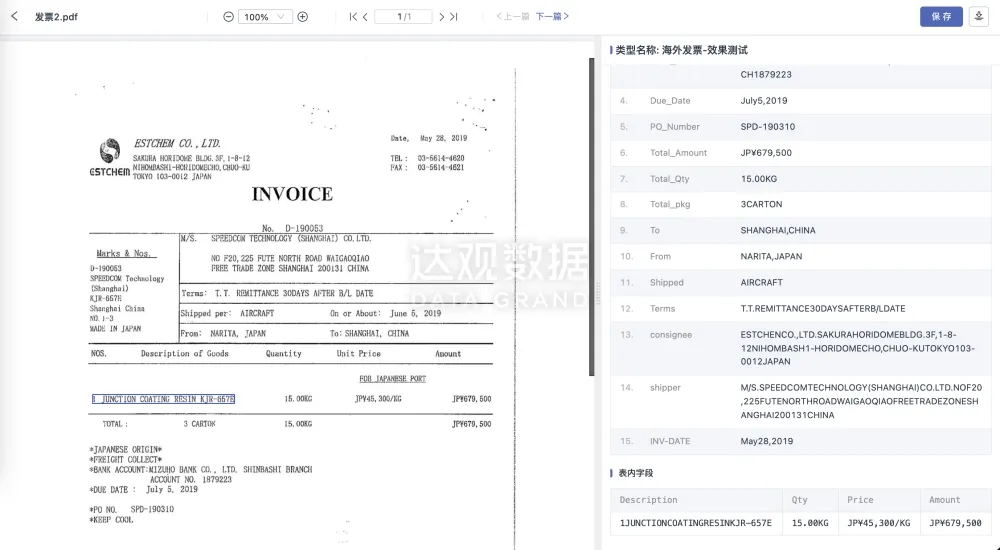
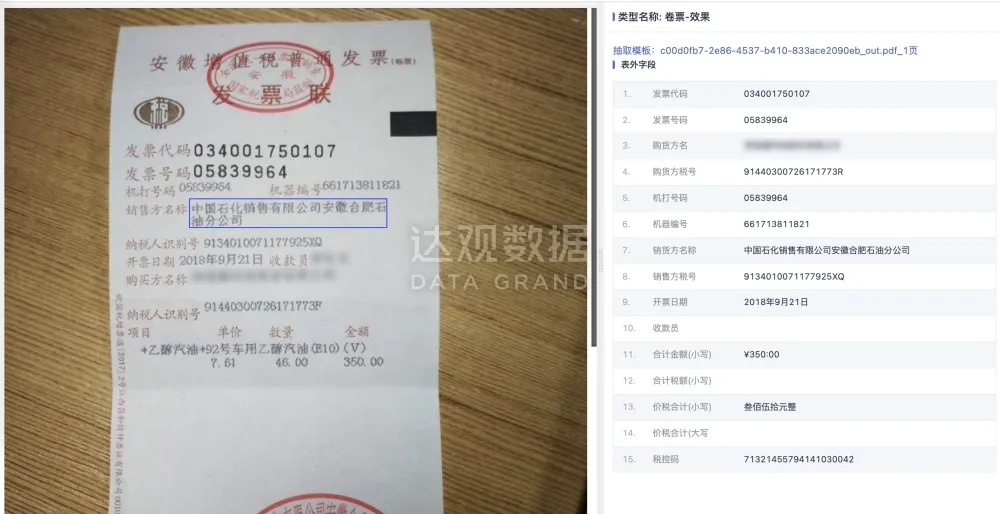
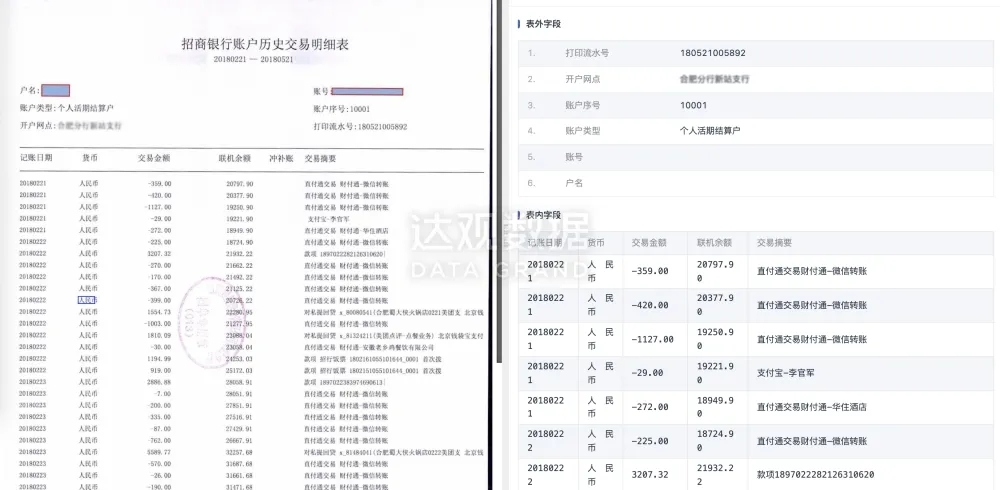
基础模型模块
基础模型模块包括功能丰富的标注模块和底层OCR模型训练评估模块,满足底层模型的标注和训练需求。
- 数据标注模块:支持文字标注和版面标签标注,通过机器预标注-人工修改的方式极大提高了标注效率,满足定制化场景的真实数据快速迭代。
- 数据生成模块:能够通过灵活定义版式、字符、内容等来实现生成数据扩展,以满足模型训练的数据需求。
- OCR基础模型训练:支持检测、识别、版面分析等类型的模型训练功能,能够从标注或生成数据灵活切分,自由编排训练策略。底层基于达观自研算法调优,通过流程化配置完成底层模型的训练。
权限模块
权限模块设计了一套角色、用户、组结构的权限系统,满足灵活的权限配置和数据管理需求。
目前达观OCR平台已经赋能银行、券商、报关、制造业、电商等多个行业的头部客户,为其降低大规模抽取任务的定制门槛和抽取成本,节约企业人力资源,提高工作流效率,提升用户体验。
市场上的人工智能产品琳琅满目,我们希望产品的使用价值高于技术噱头,达观OCR平台从积累的无数客户场景和需求中孵化而出,以产生使用价值为驱动,助力企业搭建繁重纸质数据的数字化桥梁,走上降本增效的高速路。