用全球最快 AI 超算秀肌肉后,黄仁勋要用 AI 抓住元宇宙命门
采写 | 鱼三隹
编辑 | 靖宇
「下一个时代的 AI」,在北京时间 3 月 22 日的英伟达 GTC 大会上,长达 1 小时 40 分钟的主题演讲中,创始人黄仁勋多次说起这个词。
黑色的虚拟场景中,黄仁勋有条不紊地介绍了一系列服务于 AI 运算的硬件、软件、AI 和机器人的应用框架,并介绍了英伟达过去一段时间借助 AI 在自动驾驶、虚拟世界、医疗等领域的成就。
去年 11 月秋季的 GTC2021 上,黄仁勋曾高调宣布「进军元宇宙」,相比之下,此次的 GTC2022 聚焦的问题则接地气的多。
诞生至今,「元宇宙」从被行业热捧,到成为「不切实际」的代名词,可谓大起大落。冷静之后还未离场的元宇宙玩家们,不得不思考一个严肃的问题:要到达如此之远的未来,该从哪些事情做起。
「AI」,是英伟达抓住的元宇宙命门。
对于元宇宙而言,图像处理、生成能力面临千万级别的提升,而 AI 恰能进行更为复杂、更为精细的图像处理,无论是在复制模拟,还是在创新构建等方面,AI 都是不可或缺的基础。
「AI」背后更为基础、更为关键的是「算力」。
历经十几年的发展,越来越多的数据被汇集,越来越多的大型算法模型诞生,随之而来的是有待处理的数据与参数的急剧上升。
有专业人士认为,要想实现《雪崩》中所描绘的元宇宙景象,起码需要 1000 倍的算力增长,苹果、特斯拉、Meta 等行业巨头也正逐渐转向芯片自研与定制。
行业呼唤更高效的计算硬件基础,面对突如其来杀到门口的「野蛮人」,英伟达选择主动出击。
此次英伟达无论是发布基于全新架构 Hopper 的 H100 GPU、Grace CPU,还是展现自身在 AI 软件方面的进展,无不透露出其对于抢立下一代 AI 潮头的布局与野心。
算力:重中之重
NVIDIA H100
主题演讲中,首先发布的是 H100,这是首款基于全新 Hopper 架构的 GPU。
NVIDIA H100 采用的是 TSMC 4N(台积电 4 纳米)工艺,集成 800 亿个晶体管,显著提升了 AI、HPC、显存带宽、互连和通信的速度,并能够实现近 5TB/s 的外部互联带宽。
「 20 块 H100 GPU 可以承担起全球互联网的流量 !」黄仁勋在会上豪迈宣布。
H100 实现了数量级的性能飞跃,是英伟达有史以来最大的图形处理器之一。其 FP8 算力是 4PetaFLOPS,FP16 则为 2PetaFLOPS,TF32 算力为 1PetaFLOPS,FP64 和 FP32 算力为 60TeraFLOPS。

NVIDIA H100 | 英伟达
H100 的大规模训练性能是「前辈」A100 的 9 倍,大型语言模型推理的吞吐量是 A100 的 30 倍,
与此同时,Hopper 还专门为 Transformer 打造了专有引擎,这将使得原本耗时几周的训练缩短到几天之内。在模型训练精度不变的情况下,性能提升 6 倍。
此外,H100 还是全球首款具有机密计算功能的加速器,无论是 AI 模型还是客户数据都将受到保护。
Grace CPU 超级芯片
在 H100 之外,被黄仁勋称为「全球 AI 基础架构的理想 CPU」的 Grace CPU 同样毫不逊色。
Grace CPU 是英伟达首款面向 AI 基础设施和高性能计算的专属 CPU,基于最新的数据中心架构 Arm v9,由两个 CPU 芯片组成,拥有 144 核 CPU,功耗 500W,性能较之前提升了两到三倍。

Grace CPU | 英伟达
两块 CPU 通过 NVLink 连接,该技术可以实现芯片之间的互联,具有高速率、低时延的特点。Grace CPU 与 Hopper 也可以通过 NVLink 进行各种定制化配置。
NVLink 技术未来将会被广泛应用与 NVIDIA 的芯片中,包括 CPU、GPU、DPU 以及 SoC,凭借此技术,英伟达的用户们将能够利用英伟达的平台实现芯片的半定制化构建。
EoS 全球最快的 AI 超算
算力不够,数量来凑。
通过黄仁勋的讲解我们可以得知,8 个 H100 和 4 个 NVLink 可以组合成 DGX H100,这个巨型 GPU 拥有 6400 亿晶体管,AI 算力 32 petaFLOPS;32 台 DGX H100 又能组成一台具有 256 块 GPU 的 DGX POD;而将 18 个 DGX POD,共 4608 个 GPU 搭建在一起,则是英伟达此次宣布的 EoS 超算。

DGX H100 | 英伟达
最终 EoS 能达到的算力,以传统超算标准看是 275petaFLOPS,将是此前基于 A100 的美国最大超算 Summit 的 1.4 倍;以 AI 计算的角度看,EoS 输出 18.4 Exaflops,将是当今全球第一超算富岳的四倍。
届时,EoS 将是世界上最快的 AI 超级计算机。
软件:稳步更新
在软件系统方面,英伟达依旧稳步更新。
此次英伟达发布了 60 几项针对 CUDA-X 的一系列库、工具和技术的更新,并介绍了自己在气候预测、对话式 AI 服务 Riva 以及推荐系统 Merlin 框架方面的进展。
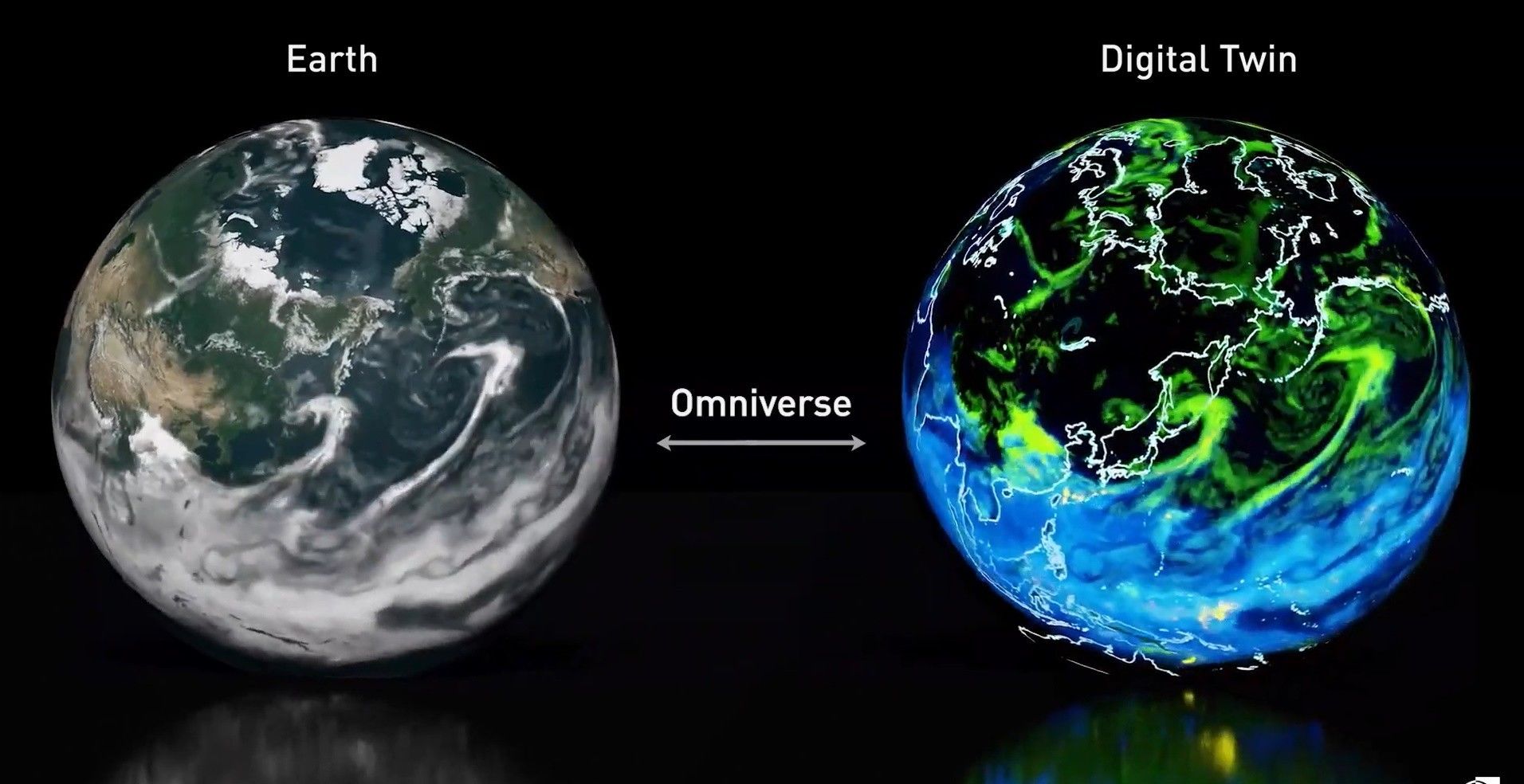
Earth-2 | 英伟达
去年的 GTC2021 上,英伟达发布了首台 AI 数字孪生超级计算机 Earth-2,几个月过去,英伟达基于此开发了一个天气预报 AI 模型 FourCastNet。
这一模型由英伟达与来自加州理工学院、伯克利实验室等高校及科研机构的研究员们共同开发,通过对高达 10TB 的地球系统数据进行训练,预测降水概率的准确率比以往的模型更高。
随后,黄仁勋又介绍了英伟达的对话式 AI 服务 Riva。
Riva 2.0 版本支持识别 7 种语言,可将神经文本转换为不同性别发声的语音,用户可通过其 TAO 迁移学习工具包进行自定义调优。
Maxine 是一个包含 30 个 AI 模型的工具包,可以实时优化视频通信的视听效果。

Maxine | 英伟达
当远程视频会议召开时,即便你在读稿或者浏览其他网页,Maxine 可以帮助说话者与参会的其他人员保持视线上的交流。如果参会人员包含不同国籍、使用不同语言,Maxine 能够通过 AI 模型实时切换成另一国语言。
Merlin 框架面向的则是推荐系统。
它可以使企业快速构建、部署和扩展先进的 AI 推荐系统。黄仁勋在直播中以微信举例,使用 Merlin 后微信的短视频推荐延迟被缩短为原来的四分之一,吞吐量提升了 10 倍,从 CPU 迁移至 GPU,腾讯在该业务上的成本减少了二分之一。
元宇宙与新一轮 AI 浪潮
在提升算力、补齐 CPU 短板的同时,英伟达也没忘记自己最终追求的元宇宙的「星辰大海」。
黄仁勋的虚拟形象 Toy Jensen 又一次上场与本尊进行对话,而值得注意的是,这一次的 Toy Jensen 能够做到完全实时地与黄仁勋进行眼神交流与对话。
面对「什么是合成生物学」、「你是如何制作出来的」等刁钻问题,Toy Jensen 都给出了流畅的回答。
Toy Jensen 的背后是英伟达的 Omniverse Avatar 框架,该框架能使企业快速构建出类似的虚拟形象,无论是外表、动作还是声音能都模仿得惟妙惟肖。
而实时对话这一点则是由上文提到的 Riva 以及超大语言模型 Megatron 530B NLP 提供的技术支撑,虚拟形象由此可以听懂问题并实时回复。

Toy Jensen与黄仁勋对话 | 英伟达
构建虚拟形象、进行实时交互无疑是未来元宇宙世界中的常态,在短短几分钟的展示里,英伟达告诉我们这似乎并非毫无可能。
此外,在黄仁勋看来,新的芯片、软件和模拟功能将掀起「新一轮 AI 浪潮」,第一波 AI 学习是感知与推理,而下一波 AI 发展的方向则是机器人。
目前,英伟达围绕真实数据生成、AI 模型训练、机器人堆栈和 Omniverse 数字孪生这四大支柱,逐步搭建起了应用于虚拟形象的 NVIDIA Avatar、用于自动驾驶的 DRIVE、用于操纵和控制系统的 Metropolis、用于自主式基础架构的 Isaac 和 用于医疗设备的 Holoscan 等端到端全栈机器人平台。
主题演讲最后,黄仁勋用大概 8 分钟的时间,带领观众们从头梳理了一遍新发布的技术、产品以及平台,并总结出了影响行业发展的 5 个趋势:million-X 百万倍计算速度飞跃,大幅加快 AI 速度的 Transformers,成为 AI 工厂的数据中心,对机器人系统的需求呈指数级增长以及下一个 AI 时代的数字孪生。
而「算力」提升仍将是一切突破的基础。
「我们将在未来十年以数据中心规模加速整个堆栈,再次实现 million-X 百万倍性能飞跃。我已经迫不及待地想看到下一次百万倍性能飞跃将带来什么。」