备受期待的「草莓大模型」最终以 o1 为名正式发布,预示着今年下半年的大模型竞争将再度升温。尽管 OpenAI 这次没有提及 o1 在多模态的相关进展,但在同一天,隔壁视频生成赛道的「卷王」可灵 AI 又要出招了,对于大多数普通用户来说,比起怎么解奥数题,轻松生成高质量图片或者视频的需求可能更加迫切。
在 9 月 13 日的快手投资者日上,快手高级副总裁、主站业务与社区科学线负责人盖坤透露,可灵正在内测 1.5 版本的基础模型。这一新模型预计在图像质量、美学表现、运动合理性以及语义理解方面有显著提升。与此同时,还将引入「运动笔刷」功能,进一步提升可灵 AI 的视频编辑能力。
自可灵 AI 今年 6 月正式发布以来,视频生成领域掀起了一场「军备竞赛」。简单数了数,这已经是可灵 AI 的第九次迭代和升级,这一切就发生在短短三个月里。
我们第一时间申请加入到内测中,一窥究竟。
01 只有 1.5 能打败 1.0 离真实世界更近一步
三个月前,可灵 AI 刚出现的时候,复刻了 Sora 视频生成的的一些经典作品(比如东京女人逛街以及吃泡面),外界已然惊呼「这已经不像是 AI 生成的了」。彼时,视频生成赛道正值第一批最卷的玩家交出作业,可灵 AI 异军突起,率先能把复杂场景理解清楚并且生成出来,引发了全球范围的极大关注。
如果说,三个月前,刚出场的可灵 AI 还在和市场上其他产品比拼,那三个月后,「它的参考对象好像只有自己」。
上面这句话是我看到可灵 1.5 模型如何击败 1.0 时的第一印象。
仍然是这个最初让可灵惊艳众人的「东京女人逛街」场景。这里我们把完整的 Prompt 放在这里:
一个时髦的女人走在东京的街道上,到处都是温暖的霓虹灯和生动的城市标志。她穿着黑色皮夹克、红色长裙、黑色靴子,拿着一个黑色钱包。她戴着太阳镜,涂着红色的口红。她走起路来自信而随意。街道是潮湿和反光的,创造了一个彩色灯光的镜子效果。许多行人走来走去。

最明显的区别是可灵 1.5 版本在清晰度上比可灵 1.0 版本又提升了一档。在高表现模式下,前者生成视频的分辨率已经可以达到 1080p,相比之下可灵 1.0 版本只有 720p。
因此这组视频中可灵 1.5 版本生成的那个版本里,可以清晰的看到女人衣服上经过光反射出来的细腻质地,手包上的纹路刻画也比之前精细很多。
并且与可灵 1.0 版本相比,可灵 1.5 版本生成的女性服装上加入了拉链的设计,这表明视频的分辨率达到了较高的要求。
但画面体感上的区别只是第一层。两个视频中更大的差异其实还藏在画质背后,在她周遭的环境中所展现出来的变化——同样的 Prompt,可灵 1.0 版本时的行人都是往远处走的背影,可灵 1.5 版本中则更真实的出现了大量同方向的人群。
同方向走来的人多了,这意味着更多的人脸画面生成,更复杂的人物细节(一个人物的正面不管从表情到服装,刻画复杂度大概率要比背影更高),以及让这一切动态的流动在画面中,对整个物理世界的理解难度。
或许可以换个理解,绘画时画群像偷懒的方法之一就是把不重要的人物设置成背影,AI 生成亦如是。而视频生成分辨率的增加有助于远景的推理。也就是说,画质的提升不只是某种「雕花」,而是真实拉高了可灵的视频生成能力。
当你的眼睛随便去捕捉画面中的一个陌生人,看到 TA 行走时真实的脸部轮廓,挎包随着向前行走的身体姿态有规律的和身体发生碰撞,眼睛则照顾着自己和女主角的物理位置并朝她看——真的很难不感到惊讶。
上面是群像,下面我们来看看怼脸的人物特写。
这是一张可灵 1.0 版本生成的个人特写,Prompt 是这样的:
女主角缓慢看向镜头,背景是模糊的城市夜景,主角被正前方的人工光源照亮,强调出面部轮廓,镜头缓慢的移动到主角的面部上

下面则是同样的 Prompt 以可灵 1.5 版本生成的:

可灵 1.0 版本的视频效果已经足够优秀,但不得不说,从脸部轮廓的塑造、对光影的理解上来看,对比之下可灵 1.5 版本在生成能力上的提升是非常具象的。
并且这里还有一个关于 Prompt 的理解提升。在可灵 1.0 版本中,特写的女性眼神从头到尾都盯着镜头,而在新生成的画面中,它开始真正理解 Prompt 中「女主角缓慢看向镜头」的意思,更符合描述。可灵基础模型在语义理解能力上的进步,显然也映射到了视频生成效果上。
除了分辨率和理解能力,这次可灵 1.5 版本在运动表现的合理性上也有了不小的进化。
再比如我尝试了一个更复杂的「杯中帆船」场景,这其中有船的运动,水面的运动以及对两者相对状态的考察。Prompt 是这样的:
生成一个特写镜头动画,展现一艘微型帆船在一杯水中航行。杯子里的水清澈透明,可以清晰地看到帆船的倒影和水波的涟漪。帆船的帆布是鲜红色的,上面印着白色的条纹,随着微风轻轻摇摆。水面上漂浮着几片微小的绿色叶子,仿佛是帆船航行途中的小岛。画面整体充满童话色彩,光线柔和温暖。
可灵 1.0 版本尚无法很好的理解「杯子」这个限制条件,给出了一个几乎无限的湖面。「叶片像岛屿」的比喻在呈现细节上也显得太过用力还是有些怪异:

但在可灵 1.5 版本的能力下,这个 Prompt 被充分实现了:

这艘帆船简直就像漂浮在一杯马天尼中那么优雅。
这三组对比视频已经大概能看出,可灵 1.5 目前在文生视频能力上的水准。但这只是可灵能力的一部分。在图生视频能力上的进化,可灵 1.5 有点超出我的想象力了。
看到下面这段视频的时候我并没有在意,但当我知道这段孩子凑到碗边,从碗中舀勺的画面是单纯从一张食物特写照片里「无中生有」的,还是有不小的震撼。
可灵 1.5 版本生成的视频:

这个视频所有的素材来源——一张没有人物的食物照片和一段仅仅 21 个字的 Prompt:
镜头拉远,一个小男孩走到桌前拿起勺子开始吃饭。
镜头的微微晃动,一个黑色勺子「入场」,然后画面聚焦到握着勺子的小男孩,眼看着他将一勺饭菜送到嘴里。甚至勺子在碗里拨开饭粒的细节都被刻画出来了。
运动合理性以及图生视频理解能力的同步提升,对于一些实用场景已经有点降维打击的意思了。
比如做一份手机的 360 度环拍视频素材。

在之前你可能需要一个环绕旋转拍摄台(至少需要一个能自转的托盘),一台相机以及一套灯光设备。现在,你有一张光线良好的产品照片可能真的足够了。
02 运动笔刷加持让视频生成更易掌控
做最靠近用户的那款 AI 产品,这是可灵 AI 从问世一开始就给外界的印象。这次升级,快手还带来了全新功能「运动笔刷」功能,大幅提升了对视频生成的控制能力。
运动笔刷使用起来很简单,你只需要将图片中需要控制运动方向的部分勾勒出来,然后给他画一个示意运动方向的箭头。可灵 1.0 模型在图生视频时,现在支持上传图片后最多为图中的 6 个元素(人或物体等)指定运动轨迹,并且还可以为某些元素额外指定静止区域,来让视频内容有更好的运动控制及运动表现。
我们拿一张帆船航行的照片来做例子。

选定帆船主体向左移动,湖面向右移动:
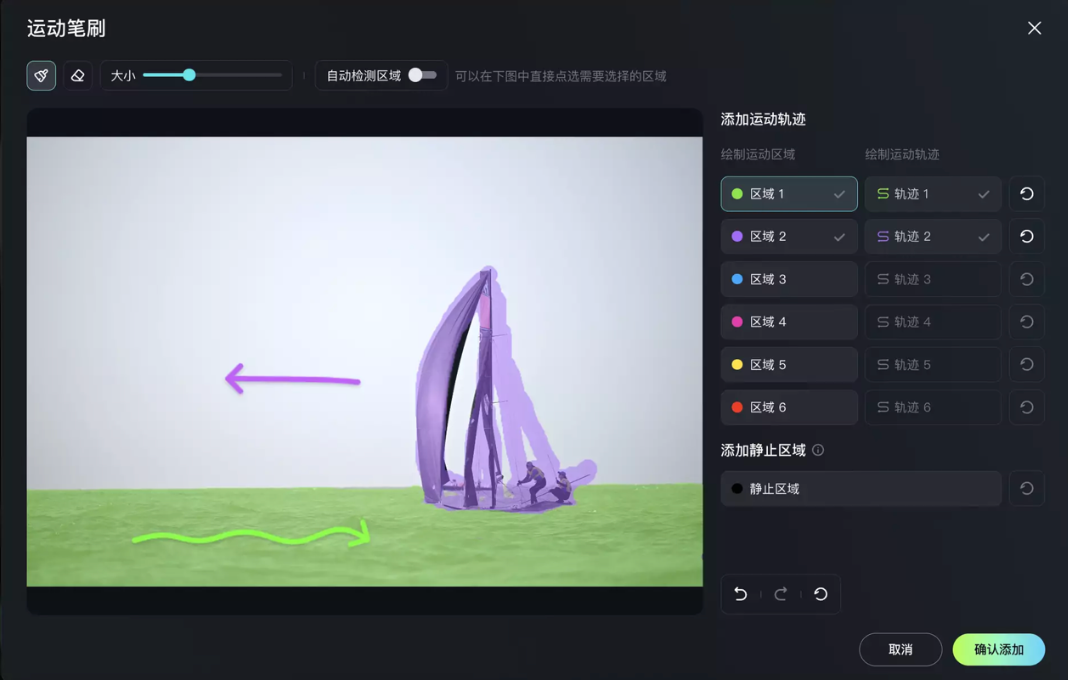
然后一个非常写实的帆船航行视频就生成了:

简单来说,有了运动笔刷之后,可灵 AI 图生视频的能力比之前变得更加可掌控,创作者可以更完整的把真实世界的规则尽可能的兑现到想要生成的视频里——比如两只小狗同框,他们大概率不会以同一个频率和方向摇头晃脑。
现在可以通过在生成阶段「微调」,让两只小狗向两个不同方向摆头,与此同时,给几株植物一个随风摆动的动作命令:
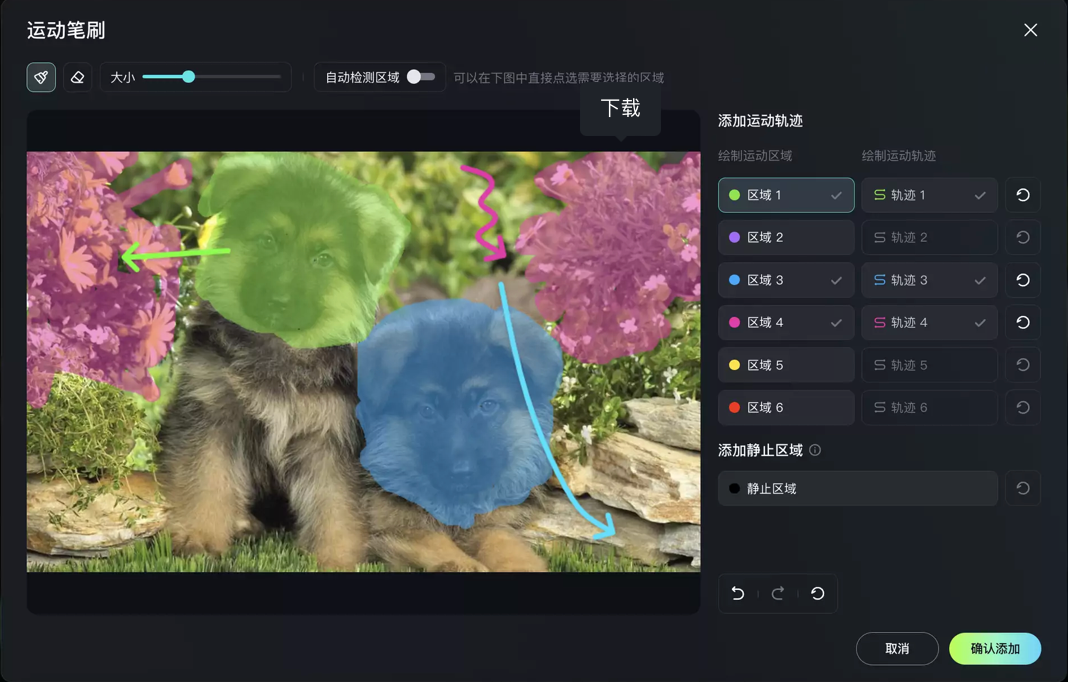

这次运动笔刷也覆盖了横屏(16:9、4:3)、竖屏(9:16、3:4)以及方屏(1:1)等多种尺寸的图片,充分满足了不同场景下的创作需求。
感觉的出,可灵此次的产品迭代完全围绕着用户的创作来进行,因为除了模型生成能力本身的提升外,另外一些变化完全打在创作者此前的使用痛点上。
比如生成视频的效率,以及视频长度。
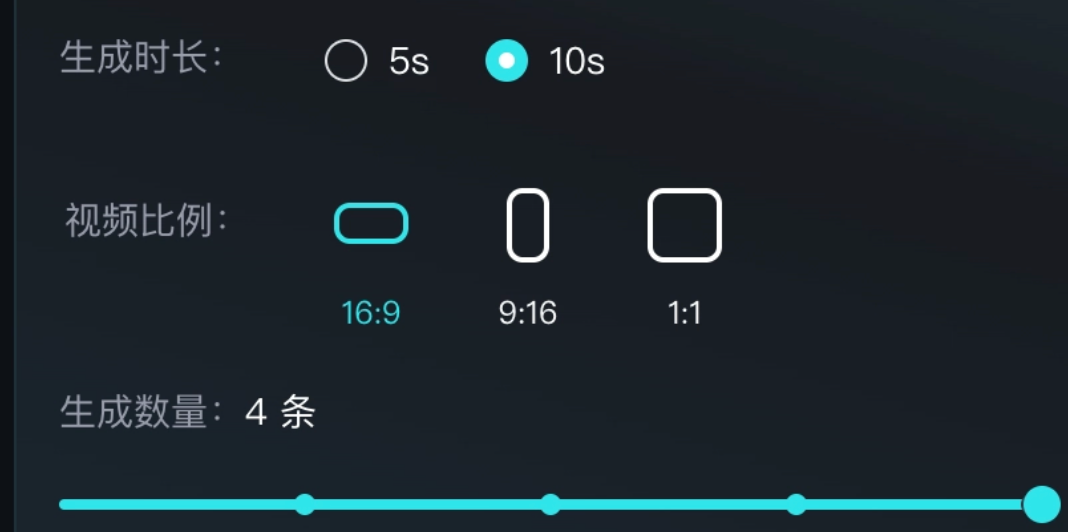
此次迭代后,可灵开始支持一次性生成最多 4 条视频,这为创作者提供了更多选择空间。此外,新版本还扩展了视频时长支持,从原本的 5s 扩充到了 10 秒。高性能模式下可灵也第一次支持增加尾帧,进一步丰富了创作可能性。
这是一个上限更高,同时比之前更加好用的可灵 AI。先享受上的创作者们已经给出了积极反馈。
这是一个上限更高,同时比之前更加好用的可灵 AI。先享受上的创作者们已经给出了积极反馈。
有创作者用可灵尝试生成了一台跑车的展示视频:

「试用了最新的可灵 1.5 版本模型,宽容度高了很多。」
社交平台 X 上,有创作者在试用可灵 1.5 版本来创作一个故宫红为主题的赛博中国短片后有这样的体感。
03 260 万可灵 AI 用户,一切刚刚开始
现阶段所有文生视频产品里,可灵 AI 是最重视「可用」的那个。
可灵 1.0 模型刚发布时,收到的最集中反馈是「即使遇到各种各样的问题,可灵 AI 仍然是目前普通人能用到的,最好的 AI 视频产品」。此时的可灵 AI 团队可能自己都没有想过未来三个月会拿到这样一张夸张的成绩单。
9 月 13 日,盖坤在投资者日上披露,截至目前已有超过 260 万人使用过快手的视频生成大模型可灵 AI,并累计生成超 2700 万个视频。

快手高级副总裁、主站业务与社区科学线负责人盖坤|图片来源:快手
回过头看,「可用」是可灵 AI 能够边打仗边学习的基础。某种程度上,在目前这个文生视频产品形态未定的时期,尽可能的靠近用户比自我臆测性能的迭代方向重要的多。
对用户来说,可灵 1.5 模型是一个更好的可灵 AI;对快手来说,可灵 1.5 模型是对所选择的这条以「可用」卷起数据飞轮的迭代路线的一次初步验证。
三个月,对于大模型的发展来说,是多长的一段路?
如果我们回到 ChatGPT,暂且把 2022 年 11 月 ChatGPT 上线作为一个起点的话,三个月后,ChatGPT 的用户完成了从零到 1 亿的积累,同月中月订 20 美元的 ChatGPT Plus 推出,OpenAI 在一片几乎是概念上的无人区里迅速完成了产品的迭代。
可灵 AI 正在经历一个有些相似的过程。
发布半个月后,可灵 AI 推出图生视频功能,支持用任意静态图像生成 5 秒钟视频。并且为了延长 5 秒的视频长度,推出了最高可到 3 分钟长度的视频续写功能。
这些使用经验在 7 月转换成了可灵 AI 在基础模型能力上的提升,以及新增的首尾帧控制和镜头控制。可灵 AI 网页端也在 7 月同时上线。
直到最近向可灵 1.5 模型跨的这一大步。
回头来看,可灵 AI 从最初的移动端文生视频工具演化到如今相对全面的产品形态,用户的使用需求决定了可灵 AI 的产品塑造,这进一步反推基础模型的性能迭代方向。一切的基础都建立在可灵 AI 的「可用」上。
而在可灵 AI 的实际体验能够达到某一个阈值后,背后快手巨大的内容和创作者生态会进一步推动这个数据飞轮的转动。2023 年首次在快手发布短视频的创作者就有接近 1.4 亿,整个 2023 年快手平台上发布的视频在平台内获得超过 1 万亿次点赞。
另一组数据或许可以说明快手生态内对于一个好用的 AIGC 工具的热情。在可灵 AI 推出之前,快手自研的文生图大模型能力已接入平台,内测阶段用户在评论区月均生成超过 5 亿张 AI 图片。
现在,一个全新的可灵 AI 即将摆在所有人面前了。
*头图来源:可灵 AI
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO