OpenAI 发布新模型,Sam Altman:耐心时刻结束了!
北京时间凌晨一点,OpenAI 突然进行了重大更新。
已经预热了接近一年的 Q*/草莓项目,传说中能够进行高级推理的大语言模型,今晚终于露出了真面目。
OpenAI 发推表示,刚刚推出了 OpenAI o1-preview 模型——名字的含义之前外媒已经爆料过,o1 应该代表着 OpenAI 下一代大模型的 Orion(猎户座)一代。
OpenAI 在发布文档中写道,新模型在推理能力上代表了人工智能能力的新水平,因此,计数器将重置为 1 —— 这意味着未来很可能不会有 GPT-5 了,o1 将代表未来 OpenAI 的最强水平。
且从今天开始, ChatGPTPlus 和 Team 用户就能够直接访问模型。
用户可以手动选择使用 o1 模型的预览版——o1-preview,或者使用 o1 模型的小尺寸版——o1-mini。o1-preview 的每周限制为 30 条消息,o1-mini 的每周限制为 50 条。
在 OpenAI 的模型介绍网页上,可以看到 o1 模型的训练数据截止时间为去年十月份,而最早的 Q*项目的爆料,正好大概出现在去年十一月份。
OpenAI 憋了一年的大招究竟如何?OpenAI 能否再一次引领大模型的潮流,甚至让人们看到通用人工智能之路不再遥远?很快,每个人都能检验这一点了。
Sam Altman 凌晨一点在 X 上发帖:「需要耐心等待的时刻结束了!」

o1 模型:解决博士级别的科学问题超越人类
截止发稿时,笔者还不能使用 o1 模型。
不过 OpenAI 已经放出了大量相关的 o1 模型表现展示。
最引人关注的当然是新模型的推理能力。Sam Altman 直接在 X 上贴出了 o1 与 GPT-4o 在数学、编程和解决博士级别科学题目上的能力对比。

最左边的柱形代表目前 OpenAI 的主力模型 GPT-4o。今天放出来的 o1 预览版为中间的橙色柱形。
可以看到,在 2024 年美国数学邀请赛的竞赛题和 Codeforces 算法竞赛题上, o1 预览版解决数学和编程问题的能力,比起 GPT-4o,提升了 5-6 倍。而可怕的是,深橙色的柱形,代表真正的 o1,相比于 GPT-4o,提升了 8-9 倍!
最后一个图中,OpenAI 还列出了人类专家在解决博士级别科学题目的时的成功率,大约在 69.7%,而 o1 预览版和 o1,都已经超过了人类专家的水平。
OpenAI 的技术博客提到了更具体的数字, 目前 o1 模型的成绩,在美国数学邀请赛上,可以排名进入美国前 500 名。而物理、生物和化学问题上的准确度,超过了人类博士的水平。
在大模型技术进入公众视野的两年内,一个经常为人们所使用的比喻是,大模型像一个什么都懂一点的大学生,在知识专精方面远远不行,但是从天文到地理,最基础的知识都能懂一点点。OpenAI 的新模型,很有可能要刷新人们的这一认知了。
在官方博客中,OpenAI 简单解释了这一进步背后的原理。
类似于人类在回答难题之前可能会思考很长时间,o1 在尝试解决问题时会使用一系列思维。通过 强化学习 ,o1 学会了磨练其思维链并完善其使用的策略。它学会了认识并纠正错误,将棘手的步骤分解为更简单的步骤。当当前方法不起作用时,它会尝试另一种方法。这个过程极大地提高了模型的推理能力。


在 OpenAI 给的案例中。GPT-4o 和 o1 模型同时回答同一个问题——读一段长文,然后做阅读理解。在 o1 模型中,会多一个选项叫做展开思维链。
如果不展开思维链,我们可以看到两个模型本身给出的答案是不同的。而打开思维链后,则会看到一段非常长的模型和自己的思维对话,解释为什么做出了不同的选择。
选 A 吗?emm,好像不是很好。选 B 吗?好像没有关联。模型完全在自己和自己提问和回答,最后判断出了哪个答案更好。


而在另一个例子中,解决化学问题时,我们可以看到 o1 模型甚至自己在选择多种方案对比。
标准的计算方式是这样。但是我们也可以这么计算,但这样或许没有必要?
在多次纠正自己之后,它得出了正确的答案。
之前,也已经有很多报道透露过 o1 模型能够有高推理能力的原理——这一训练方法,最早来自于斯坦福大学 2022 年开发的一种「自学推理」(Self-Taught Reasoner,STaR)。
后来研究人员进一步开发了一种名为"Quiet-STaR"的新技术,翻译过来大概为"安静的自学推理"。核心为在每个输入 token 之后插入一个"思考"步骤,让 AI 生成内部推理。然后,系统会评估这些推理是否有助于预测后续文本,并相应地调整模型参数。这也是人们推测 OpenAI 最早的模型项目为什么叫 Q*(读作 Q Star)的原因。
在 o1 模型出现之前,用户通常也可以自己通过和模型对话的方式,让模型进行一步一步的思考,也就是所谓的慢思考,进行更准确的回答。但是很明显,o1 模型此次将思维链放大到了完全不同的量级上。
而且,在之前的用户 prompt 引导中,模型能够回答出什么答案,最终也还要被模型能力限制。而通过不同的训练方式训练出来的 o1 模型,很有可能能够通过自己的推理,超越自身训练材料的限制,产出更高级和准确的答案。
在复杂推理任务上的进步,可能对编程和科学研究两个方向产生直接的推动。
OpenAI 提到,在未来,医疗保健研究人员可以使用 o1 来注释细胞测序数据,物理学家可以使用 o1 生成量子光学所需的复杂数学公式,所有领域的开发人员可以使用 o1 来构建和执行多步骤工作流程。
OpenAI提供了一个例子,真正做到了只使用提示词,就完成了一个游戏的编程。
而推理能力的进步,如果能够进一步消除模型的幻觉,还可能对 AI 应用的建构产生间接的影响。对未来的AI安全也有积极的影响——之前的一些通过提示词工程误导模型进行错误输出的手段,可能会直接被模型通过更强的思考能力解决。
OpenAI o1-preview 将在今天开始能够在 ChatGPT 上使用,并提供给受信任的 API 用户。
价格没涨,OpenAI 用 o1-mini 解决推理成本问题
在 OpenAI 此次发布之前,曾有不少媒体爆料,新模型因为内部推理链条较长,对于推理的算力成本的需求进一步增高,OpenAI 很有可能将提高使用模型的费用,甚至最离谱的猜测数字达到每月 2000 美金。
而此次 OpenAI 的发布,却令人惊讶,新模型的使用价格并没有上涨,虽然因为推理成本的原因,使用次数受到了大大的限制。 o1-preview 的每周限制使用条数为 30 条消息。
除了限制使用条数,OpenAI管控推理成本的另一个重要举措,是随着 o1 模型的推出,同时推出了 o1-mini 版。

OpenAI 没有具体说明 o1-mini 的参数量有多大,但通过技术文档可以看出,o1mini 版,和 o1 版上下文长度没有区别,甚至最大输出 token 数更高。
OpenAI 表示 o1-mini 尤其擅长准确生成和调试复杂代码,对于开发人员尤其有用。作为较小的模型,o1-mini 比 o1-preview 便宜 80%,这使其成为需要推理但不需要广泛的世界知识的应用程序的强大且经济高效的模型。
OpenAI 甚至还计划之后为所有 ChatGPT 免费用户提供 o1-mini 访问权限。
不过,作为新模型,o1 系列模型,目前仍然不能浏览网页以获取信息以及上传文件和图像。OpenAI 也提示道,GPT-4o 在短期内,在某些任务上会更强一些。
Scaling Law 后最重要的进展?
事实上,此次发布了新的模型,甚至不是 OpenAI 的发布中唯一重要的事情。
OpenAI 还提及了自己训练中发现的一个现象: 随着更多的 强化学习 (训练时计算)和更多的思考时间(测试时计算),o1 的性能能持续提高。 扩展这种方法的限制与 LLM 预训练的限制有很大不同。
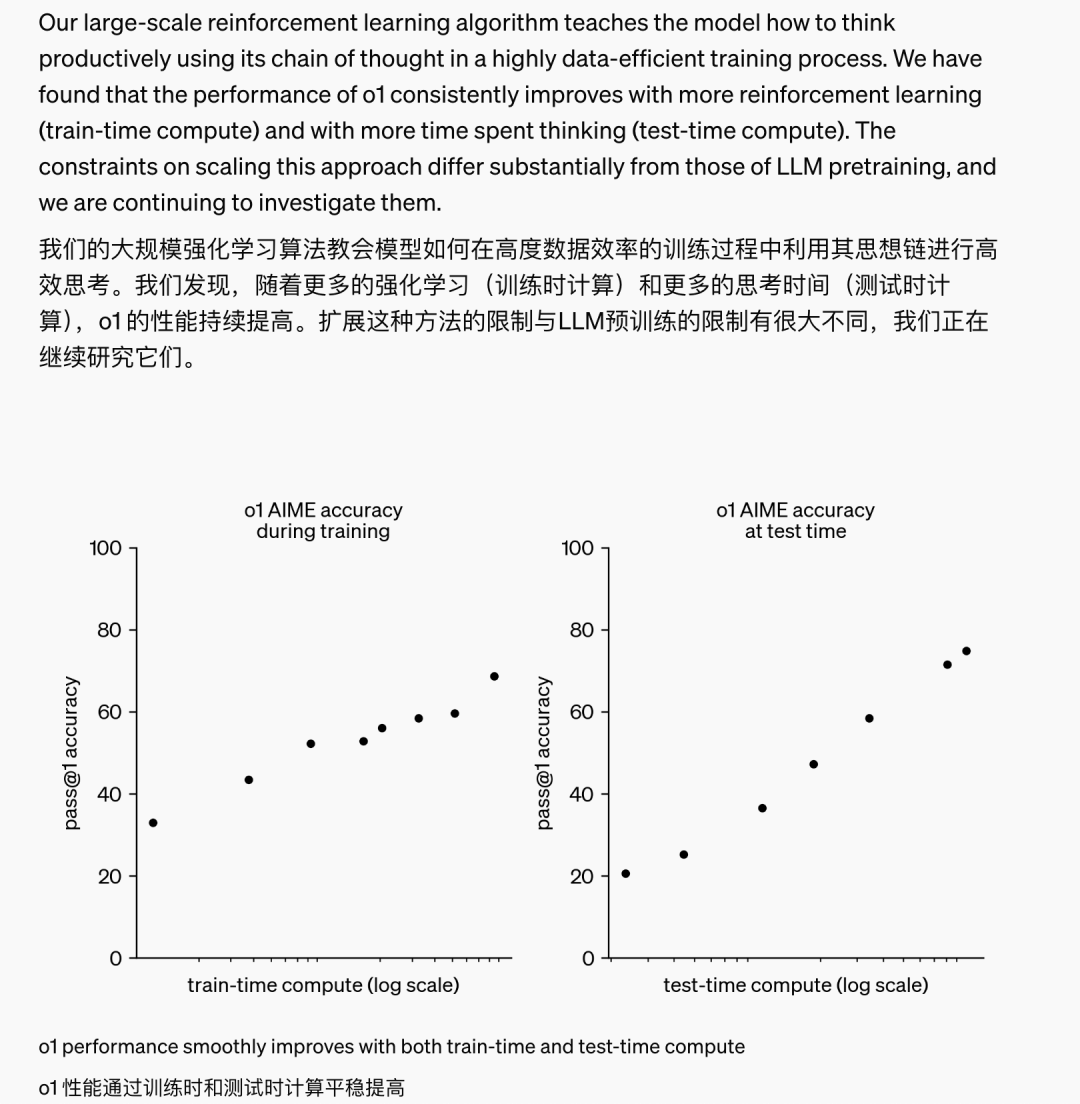
事实上,英伟达的具身团队领导者 Jim Fan 直接在 X 上点评了这一事件的历史意义—— 模型不仅仅拥有训练时的 scaling law ,还拥有推理层面的 scaling law,双曲线的共同增长,将突破之前大模型能力的提升瓶颈。
Jim Fan 表示,2022 年,人们提出了原始的 scaling law(尺度定律),大概意为随着模型的参数量、数据量和计算量的增加,模型的性能能够不断提高。
这指的是在模型的训练过程中。而 scaling law 在今年看起来,似乎已经有停滞的意味——他提到在 self-rewarding language 文章中,感受到 3 轮自我提升似乎是大语言模型的饱和极限了。
而此次 OpenAI 新模型 ,除了在训练时,通过增大参数量和数据量,得到了性能上的提升,同时通过增加推理时间——也就是前面所说的模型在自我内部思考的时间——得到了能力上的提升。
也就是说, 如果模型未来自己和自己思考的时间越长,得到的答案可能会越准确。这很接近于我们对 AI 的终极想象了——像最早在 AlphaGo 中所展现出来的,AI 通过自己和自己下棋,提升自己的棋艺。
OpenAI 的新模型,展现出的,是一条新的大模型的提升路径。
Jim Fan 在 X 上的一句话令人耸动:「之前,没人能将 AlphaGo 的成功复制到大模型上,使用更多的计算让模型走向超人的能力。目前,我们已经翻过这一页了。」
回看 2023 年,许多人在问,Ilya 看到了什么?
大家都怀疑是一个超级强有力的模型——是的,此次发布的 o1 模型确实很强。
但或许,更有可能是这个——推理层面的 scaling law 的发现,再一次让人们意识到,超人的 AI ,或许不再遥远。
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO