手握 Andorid 和搜索,谷歌 AI 更看重如何落地
一连串烟雾弹后,昨天 OpenAI 用一个可以看到、听到真实世界,并可以实时无延迟对话的 AI 智能助手「GPT-4o」震撼了世界。而把发布 4o 的时间点特别选在谷歌 I/O 大会开幕前一天,当时就有媒体预测,OpenAI 这是在狙击谷歌。
果不其然,美国当地时间 14 日上午 10 点举行的谷歌 I/O 大会主题演讲上,虽然谷歌发布了一系列基于 Gemini 的「AI 全家桶」——包括升级 200 万 tokens 上下文的 Gemini 1.5 Pro、新模型 Gemini 1.5 flash、类 Sora 的新视频大模型 Veo,以及包括 AI 搜索、AI + Gmail 在内的多个 AI 应用。
但最受关注的,还是谷歌 DeepMind 负责人兼谷歌 AI 领导者 Demis Hassabis 口中,真正通向 AGI 的万能助手项目——「Project Astra」,这也是下一阶段谷歌发力 AI 的重点。以及面向 Gemini Advanced 订阅者新推出的语音聊天功能 Live,后者预计还将在年内加入相机功能,让 AI 可以基于用户所处的真实环境展开对话。
这两个产品都有点像「GPT-4o」,但先不论三者的真实效果到底如何,从产品进展来看 OpenAI 已经领先一筹。不过这也不意味着 OpenAI 注定成为最后的赢家,目前来看手机依然是这些超级智能助手最重要的硬件载体,掌握安卓系统的谷歌有着天然的优势。从这个角度看,前段时间苹果与 OpenAI 的合作传闻,可能正是来源于二者对抗谷歌因而各取所需。
不论如何,具备「真实世界感知 Input」+「低延迟语音 Output」的超级智能助手,已经成为下一阶段 AI 公司军备竞赛的关键。接下来更多大模型公司、云计算平台,甚至手机公司、AI 应用开发者都会卷入其中。
Project Astra——通往 AGI 的超级智能助手
I/O 大会上,谷歌发了一段非常惊艳的 AI 助手演示视频,这次还了发誓,没有以任何方式伪造或篡改。
Demis Hassabis 说,Project Astra 是自己期待了几十年的 AI 助手的雏形,是 AI 助手的未来。
Project Astra 是一个实时、多模式的人工智能助手,通过接收信息、记住它所看到的内容、处理该信息和理解上下文细节来与周围的世界进行交互,它的语音交互比当前形式的 Google Assistant 更自然,没有延迟或延迟,可以回答问题或帮助你做几乎任何事情。
演示视频中,用户要求 Project Astra 在看到发出声音的东西时告诉她,助手回答说,它可以看到一个发出声音的扬声器。
交互是实时语音进行的,且并没有「嘿,Google、Gemini」等唤起词,用户还向问 Project Astra 视频中显示器上的代码有什么作用,Project Astra 没有一丝延迟地进行了解释。

Project Astra 记住了一闪而过的眼镜|图片来源:谷歌
Project Astra 关于视觉的处理甚至算整场发布会最大的亮点。「你记得我把眼睛放哪了吗?」「你的眼镜在桌子上的红苹果旁边。」Project Astra 甚至通过镜头记住了一闪而过的眼镜,并准确回答出在苹果旁。这里可能夹带了一点「私货」,这副眼镜上或许也有 Project Astra。
从演示看,Project Astra 可以很快处理收到的信息,可以通过连续编码视频帧并将视频和语音组合成事件时间线来做到这一点,然后缓存信息以供回忆。谷歌表示,其中一些功能将在今年晚些时候添加到 Gemini 应用程序和其他产品中。

Project Astra 给这个乐队起名为金色条纹|图片来源:谷歌
谷歌称 DeepMind 团队还在研究如何最好地将多模态模型整合在一起,以及如何平衡超大型通用模型与更小、更集中的模型。
昨天刚发布 GPT-4o 的 OpenAI 最重大的突破也在多模态上,看下来似乎昨日重现。最大的一个区别在视觉处理上,是目前 GPT-4o 只能处理静态图像,Astra 已经可以处理视频。
Project Astra 背后的 Gemini 系列大模型能力也有更新。上个月举办的 Google Cloud Next 2024 大会上发布,发布的 Gemini 1.5 Pro,具有原生音频理解、系统指令、JSON 模式等,可提供 100 万长文本能力,宣布已经向全球开发者开放。
这次宣布推出的 Gemini 1.5 Flash 模型,解决了关键的成本问题。Gemini 1.5 Flash 介于 Gemini 1.5 Pro 和 Gemini 1.5 Nano 之间,主要面向开发者。会上详细介绍了 Gemini 1.5 Pro 和 Flash 的定价。Gemini 1.5 Flash 的价格定为每 100 万个 token 35 美分,这比 GPT-4o 的每 100 万个 token 5 美元的价格要便宜得多。

Gemini 1.5 Flash|图片来源:极客公园
谷歌还预告了接下来的动作,宣布今年晚些时候将模型的现有上下文窗口增加一倍,达到 200 万个 token。这将使其能够同时处理 2 小时的视频、22 小时的音频、超过 60,000 行代码或超过 140 万个单词。

Gemini 1.5 Pro |图片来源:极客公园
谷歌去年 12 月发布的一个预录演示遭到「造假」质疑,通过剪辑误导人们高估 Gemini 的视频处理能力,不过现在,这些能力都是真的了。
基于大模型的 AI 应用生态方面的进展
在这次 I/O 大会上,谷歌基于大模型的 AI 应用生态也有所升级,涵盖搜索、照片、创作、工具以及工作应用等方方面面。
搜索是谷歌 25 年前的创世产品。在一年前,谷歌表示,搜索的未来是 AI。现在,谷歌搜索中的 AI 真的来了,主打一个——「让谷歌帮你谷歌。」
谷歌首席执行官桑达尔·皮查伊(Sundar Pichai)在 I/O 大会上宣布,人工智能生成的搜索摘要,现在被称为「人工智能概述」,将在「本周」向美国的所有人推出,更多国家/地区即将推出。
相比从前,AI 搜索可以处理更复杂的问题。谷歌提供了一个例子,也许用户在寻找一个新的瑜伽工作室,要求这个工作室既要在当地很受欢迎,也要方便通勤,还要有折扣,那么,这只需一次搜索就能实现,结果将出现在搜索页面顶部。
另外,用户还可以调整已经生成的 AI 摘要,或者选择简化版本,或者选择查看更多细节。
这一切是谷歌通过定制的 Gemini 模型来实现的,其将多步推理、规划和多模态与搜索系统结合,总结网络内容并展示答案,据称还是 AI 来设计和填充结果页面。
但一个问题是,如果是 AI 为用户捕获搜索结果,谷歌的竞价广告业务往哪放?
据谷歌高管称,与传统查询出的网页列表相比,AI 摘要中包含的链接会获得更多点击。「与以往一样,广告将继续出现在页面的专用位置上,并通过清晰的标签区分有机结果和赞助结果。」
除了提问,谷歌 AI 搜索还能制定计划,从饮食到旅行计划,比如搜索「创建一个容易准备的团体 3 天饮食计划」,AI 就会定制计划,然后用户可以将某份晚餐调整成素食,随后导出到文档或者谷歌邮箱里。
搜索还不仅仅是文本框中的文字,谷歌的视觉搜索也进化了,可以用视频提问。比如,用户有台二手唱片机,上面带针的金属部件漂移了,不知道怎么回事,可以直接用视频搜索,即能得到有解决步骤的 AI 摘要和相关链接,省去描述问题所需要的正确术语的时间和麻烦。
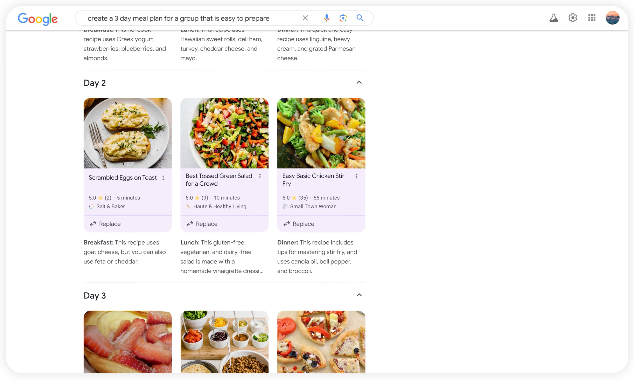
图:使用谷歌 AI 搜索,直接制定饮食计划 |谷歌
谷歌照片应用也将进化。桑达尔·皮查伊在演示中称,9 年前他们推出了这个应用,现在每天有超过 60 亿张照片和视频被上传到这里。
该应用在未来几个月将推出「询问照片(Ask Photos)」功能,也是基于 Gemini 模型,可以让用户以自然语言搜索照片和视频中的人物、宠物、地点等,它能理解照片的上下文和主题,找到特定的回忆信息,无需滑动屏幕。
例如,「向我展示我参观过的每个国家公园的最好看的照片」「我的车牌是什么?」「去年我在哪里露营?」「我的优惠券什么时候到期?」「露西娅什么时候学会游泳的?」「显示露西娅的游泳进步情况」「莉娜的生日派对是什么主题?」最后,它还能撰写旅行亮点或者个性化的标题,供用户在社交媒体上分享。
谷歌还称,「除非在极少数情况下是为了解决虐待或伤害问题,我们不会使用这些个人数据训练 Google Photos 之外的任何生成式 AI 产品,包括其他 Gemini 模型和产品。」
图:使用询问照片功能,询问生日派对细节|谷歌
在创作工具方面,谷歌在 I/O 大会上还推出了 AI 生成视频的工具 VideoFX,并更新了 AI 图像和 AI 音乐创作工具 ImageFX 和 MusicFX。
VideoFX 可以让电影制作人编写提示来构建电影镜头,ImageFX 添加了图像编辑控件,而 MusicFX 出了一个新的 DJ 模式。
其中,新工具 VideoFX 由 Veo 提供动力,Veo 是谷歌 DeepMind 最强的生成式视频模型。这个新工具配备了一个故事板模式,可以逐个场景地进行迭代,并向最终视频添加音乐。
据谷歌高管称,Veo 能理解「延时拍摄」等电影术语,可以生成各种电影和视觉风格的 1080p 分辨率视频,时间还可以超过一分钟。Veo 将通过候补名单提供预览版。
另外值得注意的是,VideoFX、ImageFX 和 MusicFX 生成的所有内容,都会被隐形的数字水印 SynthID 标记,主要是为了防止 AI 内容滥用和虚假信息传播问题。

图:使用谷歌 AI 生成视频工具 VideoFX |谷歌
除了创作工具,谷歌日常工作应用的进化也值得关注。包括 Gmail 邮箱、日历、文档、表格、幻灯片、云端硬盘等在内谷歌 Workspace 应用,将引入最新的 AI 模型 Gemini 1.5 Pro,位于侧边栏,作为一个虚拟助手。
当用户点击侧边栏的 Gemini 图标时,Gmail 中的 Gemini 将提供「总结此电子邮件」「列出下一步操作」「建议回复」等选项。用户可以让它总结小孩学校的邮件,获得需要行动的信息,起草回复。
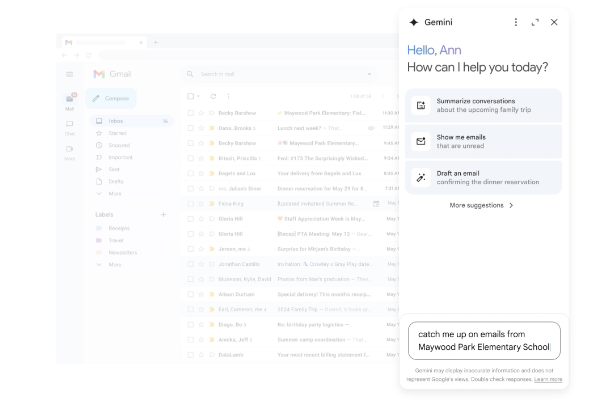
图:Gmail 侧面板中的 Gemini 总结电子邮件 |谷歌
另外,在昨天 OpenAI 发布的 GPT-4o 演示中,其中有个教育场景,GPT-4o 直接化身家教,逐步教一个青少年解决几何数学问题。
谷歌也宣布推出 LearnLM,这是一组基于 Gemini 的微调模型,专为学习教育而设计,同时演示了一些在搜索、YouTube 应用上的 AI 教育学习场景。
比如,在 YouTube 上,用户可以在观看视频时提问,也可以针对视频提后续问题。在 Android 上,可以用画圈搜索(Circle to Search)尝试解决数学和物理题目里的特定困难。
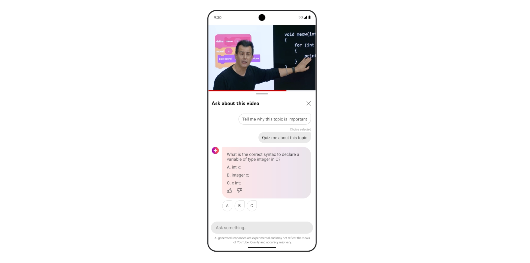
图:针对 YouTube 学习视频进行提问 |谷歌
在这场 AI 公司的军备竞赛中,谷歌追赶 OpenAI 的其中一大优势「老本」,在于其掌握手机安卓系统,以及庞大的应用生态。安卓还即将推出基于 AI 的诈骗电话检测功能。
但当生成式 AI 真的全方位进入谷歌的生态应用,直接接管搜索,帮人回忆过去,制定出行计划,解释机器故障,取代真人家教等等,在让渡用户的数据后,其是否真的可靠?这将是这场军备竞赛的另一个关键,我们拭目以待。









