电影搭子来了!贾佳亚团队用2token让大模型津津有味地看GTA6预告片
家人们谁懂,连大模型都学会看好莱坞大片了,播放过亿的GTA6预告片大模型还看得津津有味,实在太卷了!
而让LLM卷出新境界的办法简单到只有2token——将每一帧编码成2个词即可搞定。等等!这种大道至简的方法有种莫名的熟悉感。不错,又是出自香港中文大学贾佳亚团队。
这是贾佳亚团队自8月提出主攻推理分割的LISA多模态大模型、10月发布的70B参数长文本开源大语言模型LongAlpaca和超长文本扩展术LongLoRA后的又一次重磅技术更新。而LongLoRA只需两行代码便可将7B模型的文本长度拓展到100k tokens,70B模型的文本长度拓展到32k tokens的成绩收获了无数好评。
这次,贾佳亚团队的新作多模态大模型LLaMA-VID,可支持单图、短视频甚至长达3小时电影的输入处理。须知当前,包括GPT-4V在内的多模态模型 [1,2,3]基本只能支持图像输入,面对实际场景中对多图像长视频的处理需求支持十分有限,面对几十分钟甚至几个小时的长视频更显无能为力。
可以说,LLaMA-VID的出现填补了大语言模型在长视频领域的空白。

电影搭子LLaMA-VID的一手体验
先拿最近爆火的GTA6预告片试试手感。

LLaMA-VID能够准确理解预告片里出现的场景,并能分析预告片中 游戏 吸引人的地方在于广泛的活动场景和惊艳的视觉效果。
而根据游戏中的场景和特征,LLaMA-VID还能推测出预告片是Rockstar公司游戏GTA6的推广,并说出游戏的背景城市为迈阿密。
针对网络上流行的短视频和图片,LLaMA-VID也不在话下。

LLaMA-VID能够分析短视频中知名表情包的笑点,因为视频中人物夸张的表情以及对周围人物的情绪感染不断加深并强化。

也能扮演“福尔摩斯”,像侦探来根据室内的环境分析人物性格。
接下来,LLaMA-VID将通过看经典电影来展示自己的看家本领。首先是励志、温情的《阿甘正传》:

可以看出,LLaMA-VID对角色的理解与分析十分准确。
如珍妮对于阿甘的意义(孩童时期的朋友,后来成为阿甘的妻子,是阿甘生活和心灵的慰藉);阿甘在战争及退伍后的事件分析(丹中尉责怪阿甘救了自己,无法战死沙场),并对接见阿甘的美国总统如数家珍(肯尼迪、约翰逊、尼克松分别因为全美橄榄球运动员、越战荣誉勋章、和全美乒乓球队接见阿甘)。
这一次直接挑战超长视频,让LLaMA-VID看一部近3小时的、刺激的科幻大片《星际穿越》,并与其进行对话。
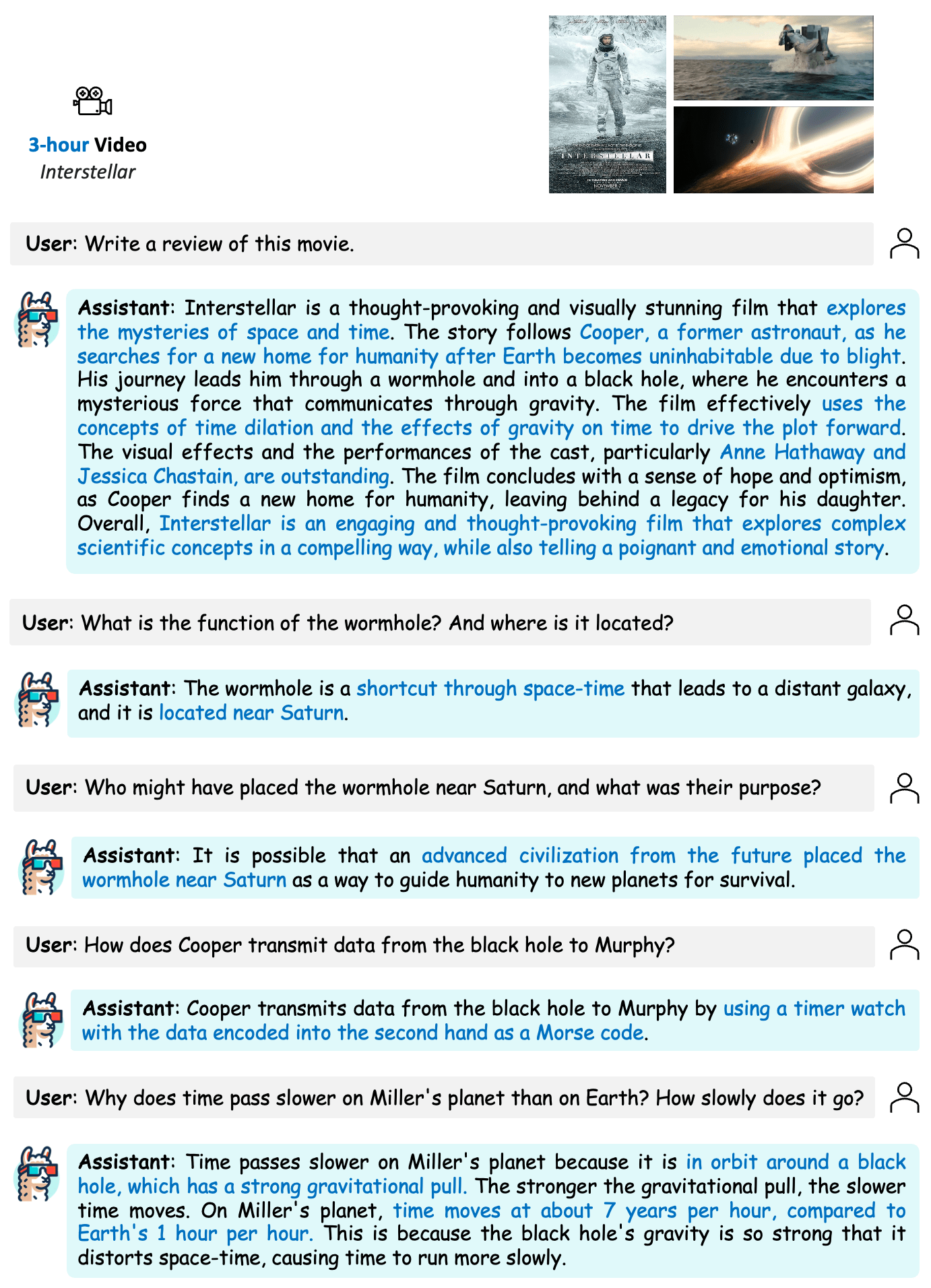
可以看出,LLaMA-VID不仅能结合电影情节和人物轻松对电影进行点评,而且能很精准地回答出剧中所涉的细节。
例如,虫洞的作用和创造者是谁(未来的智慧生物放置在土星附近,用于帮助人类进行远距离星际穿越),男主库珀是如何将黑洞中的信息传递给女儿墨菲(通过手表以摩斯密码的方式传递数据),以及米勒星球上相对地球时间的快慢及原因(米勒星球由于在黑洞附近,导致1小时相当于地球7年)。
不得不说,这个电影搭子实在太强大了,又狠话又多那种!
16个图片视频量化指标直接Promax
见识过电影搭子的超能力后,不妨来看看贾佳亚团队是如何开发LLaMA-VID的。
要知道,当前的多模态模型无法处理长视频的主要原因在于传统多模态大模型对单张图片的编码token数量过多,导致在视频时间加长后所需要的token数急剧增加,使模型难以承受。
以当前多模态大模型的技术标杆GPT-4V为例。由于每张图像都需要过多的Token进行编码,GPT-4V很难将所有的视频帧全部送入大模型。例如对于GTA6预告片(1分30秒)的输入,GPT-4V采用抽取5帧的策略进行逐帧分析:


这不仅会使用户对视频内容无法获得直观的理解,并难以处理更长的视频输入。
如果让GPT-4V对视频进行统一分析,则会出现报错并无法处理:
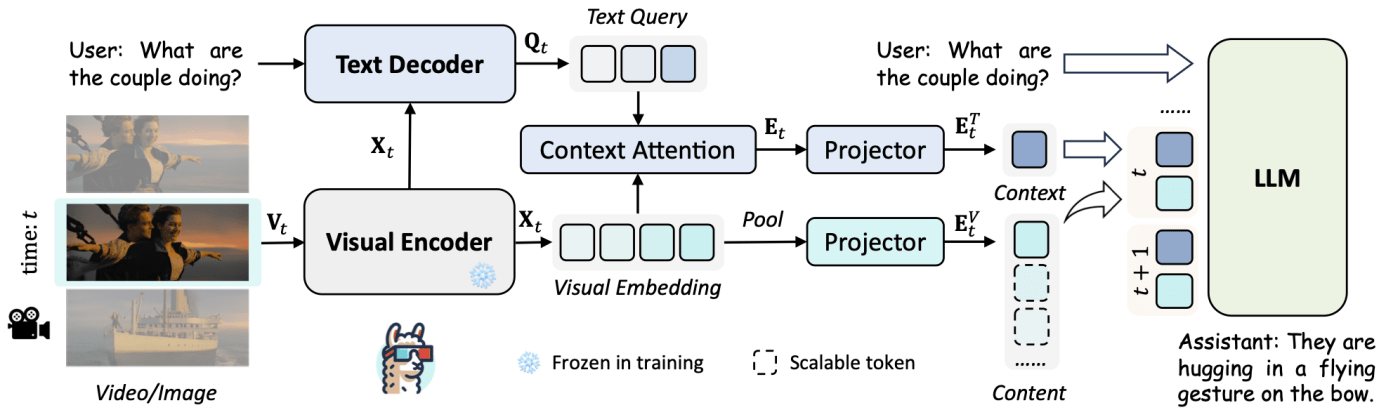
为解决这个问题,贾佳亚团队重新设计了图像的编码方式,采用上下文编码 (Context Token) 和图像内容编码 (Content Token) 来对视频中的单帧进行编码,从而将视频中的每一帧用2个Token来表示。
其中,上下文编码根据用户输入的问题生成,从而保证了在极限压缩视频消耗的同时,能尽可能保留和用户问题相关的视觉特征。而图像内容编码则更加关注图像本身的内容信息,来对上下文编码未关注到的环境进行补充。
简单来说,对于上下文编码 (Context Token),LLaMA-VID利用文本解码器(Text Decoder)根据用户的输入和图像编码器(Visual Encoder)提取的特征来生成输入指令相关的跨模态索引(Text Query),并使用所生成的索引对图像编码器生成的特征利用注意力机制(Context Attention)进行特征采样和组合,从而生成高质量的指令相关特征。
而对于图像内容编码 (Content Token) ,LLaMA-VID直接根据用户需求对图像特征进行池化采样。这对于单张图片或短视频,可保留绝大多数的图像特征从而提升细节理解,而面对几个小时的长视频时,则可将每帧的图像特征压缩成2个Token。
用这种方式,LLaMA-VID可以将3个小时的电影或视频精简为数个Token,直接使用大语言模型进行理解和交互。
这种Token生成方法非常简洁,仅需几行代码即可实现高效的生成。

此外,LLaMA-VID还收集了400部电影并生成9K条长视频问答语料,包含电影影评、人物成长及情节推理等。结合之前贾佳亚团队所发布的长文本数据集LongAlpaca-12k(9k条长文本问答语料对、3k短文本问答语料对), 可轻松将现有多模态模型拓展来支持长视频输入。
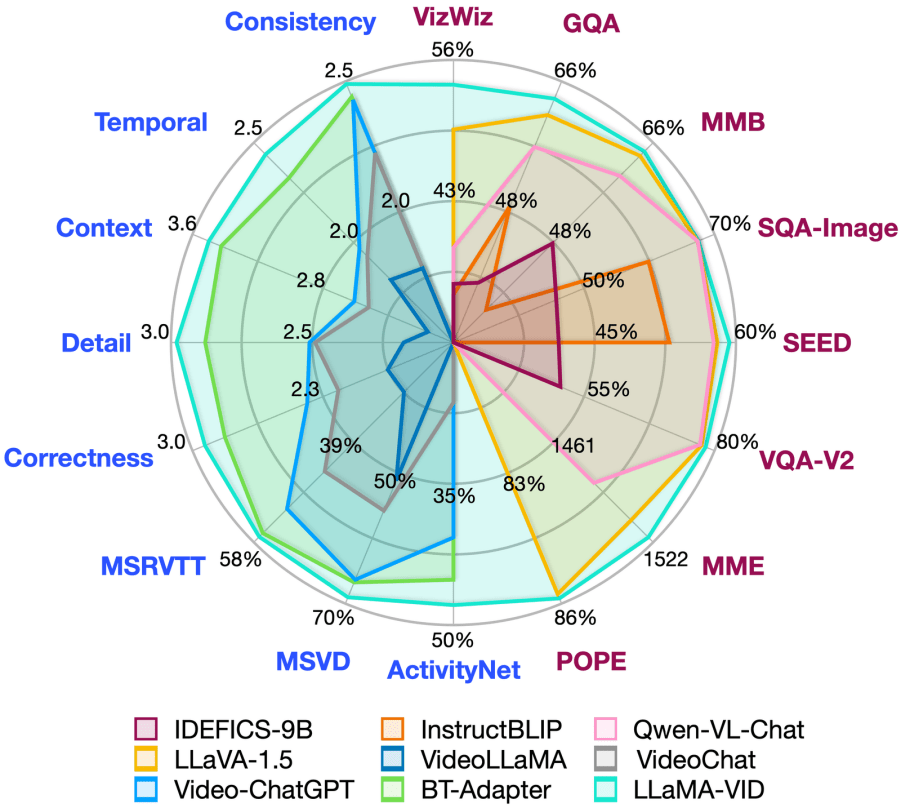
在16个视频、图片理解及推理数据集上实现了promax的效果
与现有方法相比,LLaMA-VID所提出的创新之处在于,仅用2个Token来处理视频中的图片即已大幅超越以往的模型,在MSVD-QA,MSRVTT-QA,ActivityNet-QA等多个视频问答和推理的榜单上实现了SOTA。而随着语言模型的增大,效果还能进一步增强。
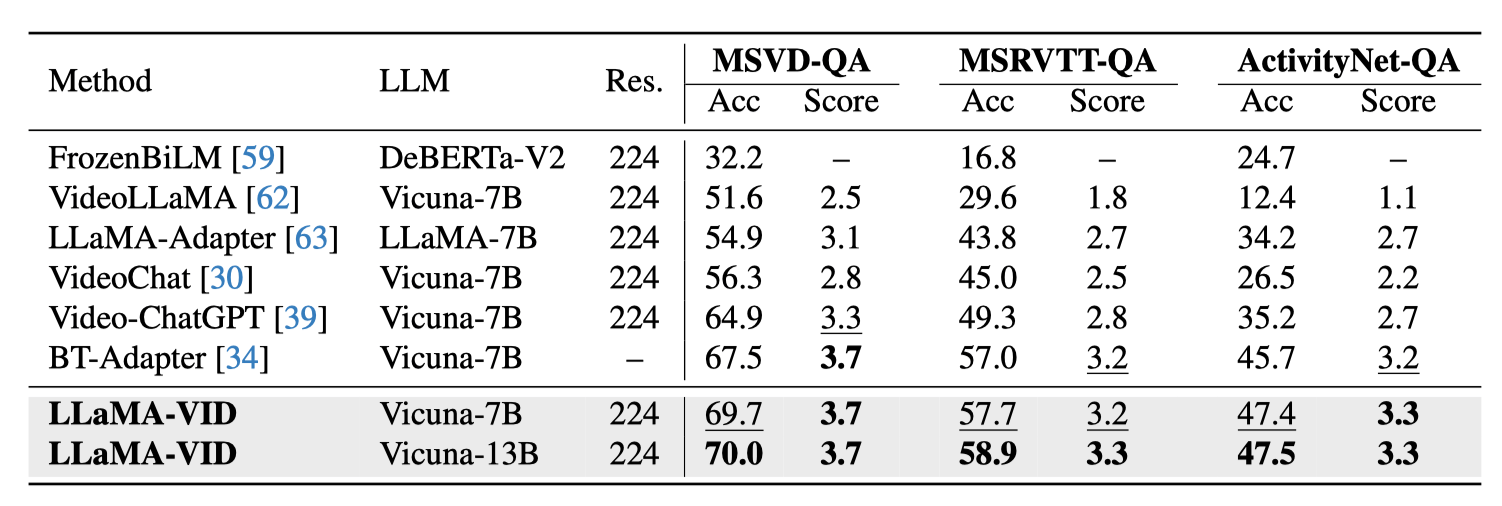
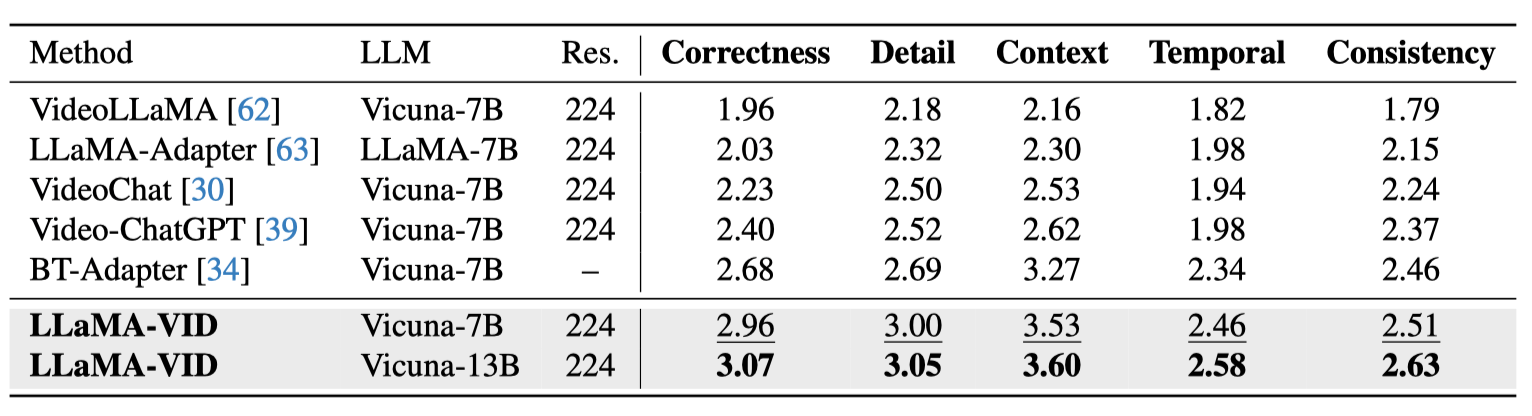
而面对现有的多模态模型如LLaVA-1.5,LLaMA-VID仅需加入1个所提出的上下文编码 (Context Token)拓展,能在GQA、MMBench、MME、SEED等8个图片问答指标上获得显著的提升:

值得一提的是,LLaMA-VID的视频理解和推理能力已经出了Demo,可以在线跟电影对话的那种。
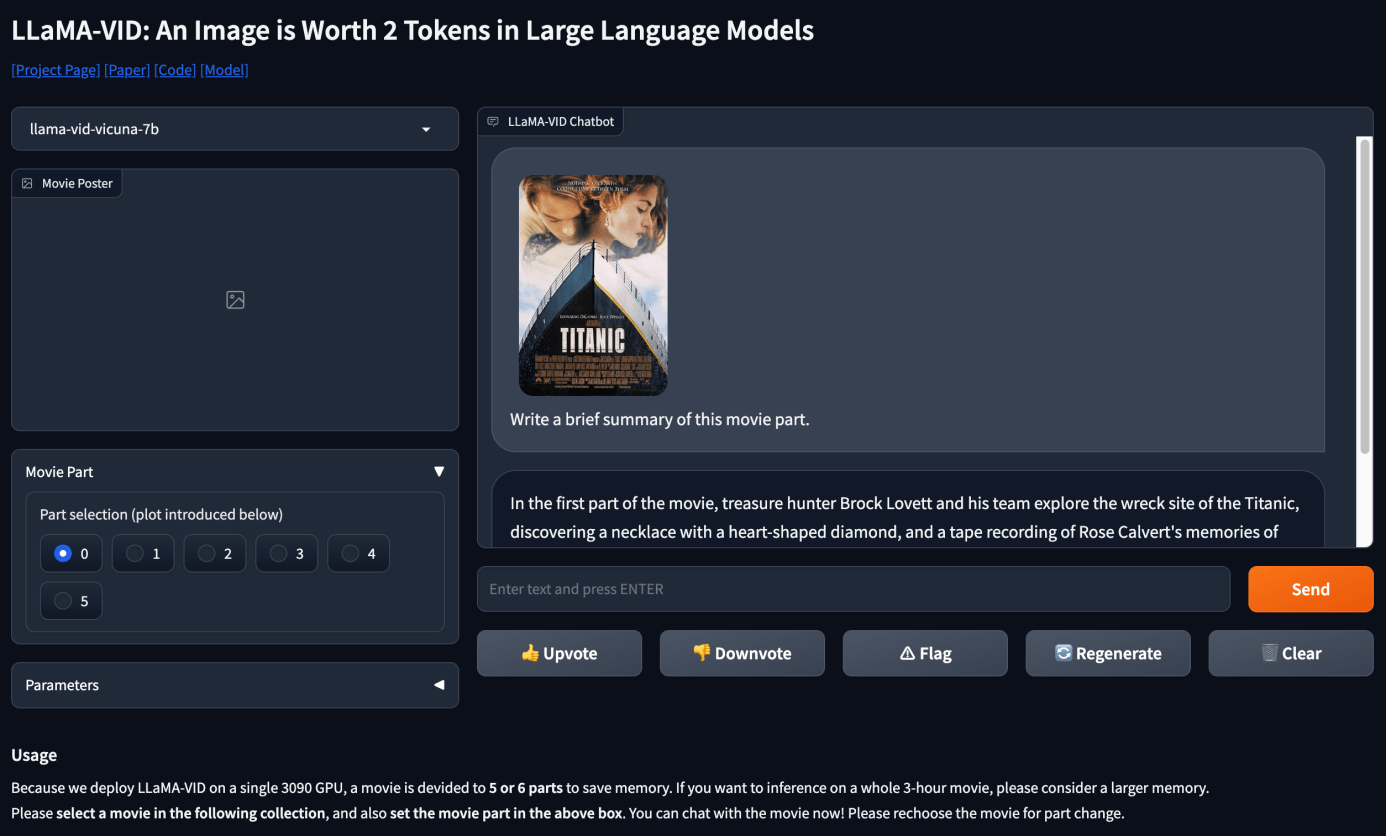
操作也极其简单,只需选择电影海报和对应的电影段,即可直接和电影交流(部署在单块3090,需要的小伙伴可以参考code用更大的显存部署,直接和整个电影对话)。
同时也支持用户上传短视频进行互动。
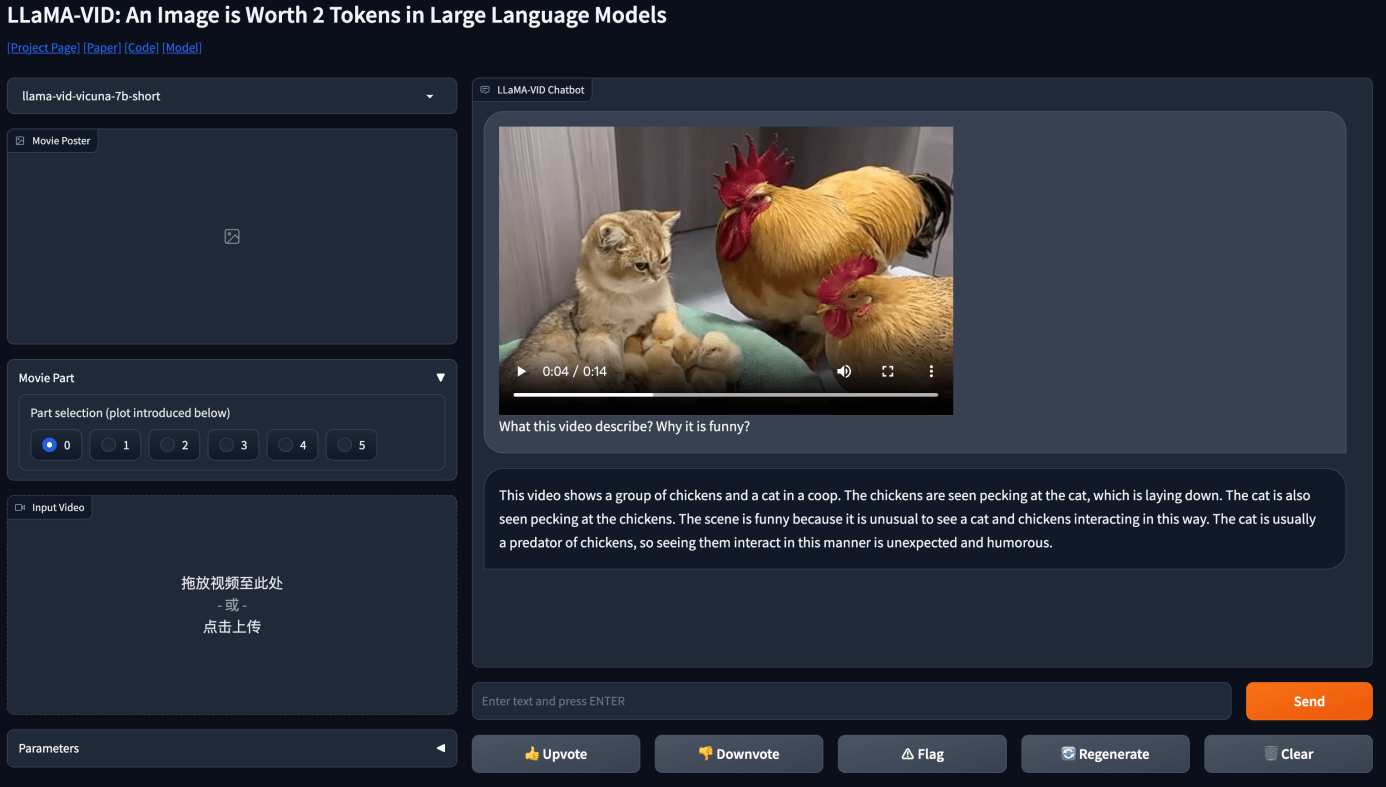
如果对描述指令有疑惑的,Demo也给出了一些示例,感兴趣的小伙伴们不妨来pick一下这个电影搭子。

参考文献
[1] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv:2306.02858, 2023.
[2] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv:2305.06355, 2023.
[3] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv:2306.05424, 2023.