英特尔傲腾数据中心级持久内存(AEP)在Redis上的应用实践
什么是英特尔傲腾技术?
无晶体管设计数据按位级别写入,因此每个单元的状态可以独立于其他单元被改变为0或1

英特尔傲腾Pmem和SSD填补数据中心计算和存储间的差距

测试背景
由于Redis实例规模比较大45000+,使用服务器数量多2000+,而且使用内存存储成本相比磁盘要高很多,基于Redis集群进行现状分析,针对以下集群决定使用傲腾AEP存储进行成本优化。
1.请求量低的小集群非常多,部署比较分散,服务器资源成本高。
2.大容量集群每次申请200G到2T容量不等,使用服务器数量多。
傲腾AEP上线需要做什么

傲腾AEP性能如何
首先性能测试,整体来讲跟纯内存相比有10%左右的损耗,测试数据如下。目前我们在该机型仅支持小集群、大容量的业务,目前不存在性能问题。
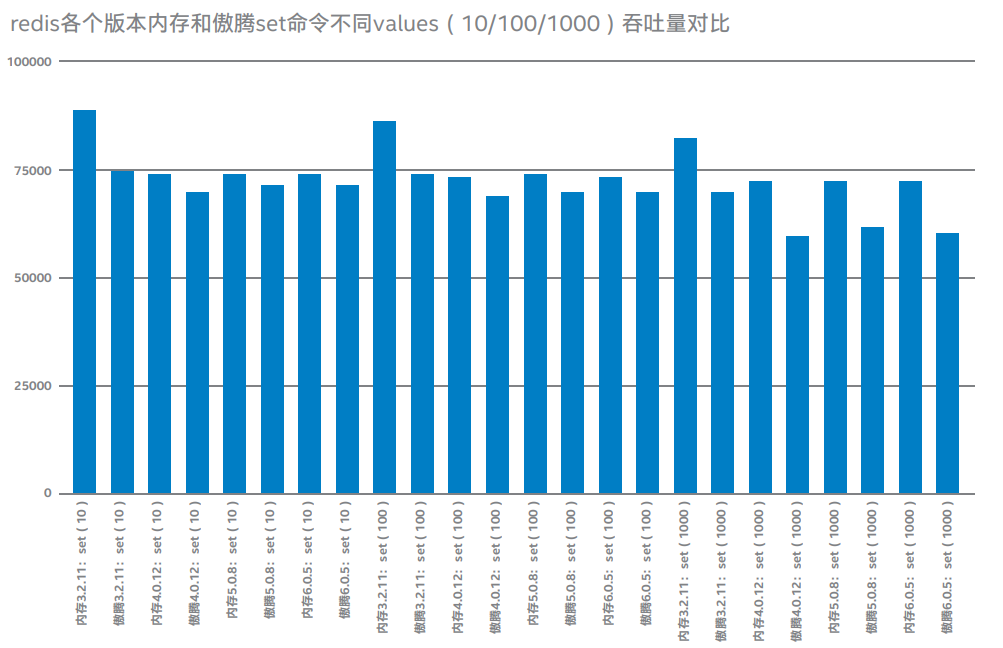
说明:上图为当Redis单进程cpu负载80%左右的情况下,在内存和傲腾不同存储上分别运行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,当set命令value为10、100、1000字节每秒处理请求个数压测结果对比。
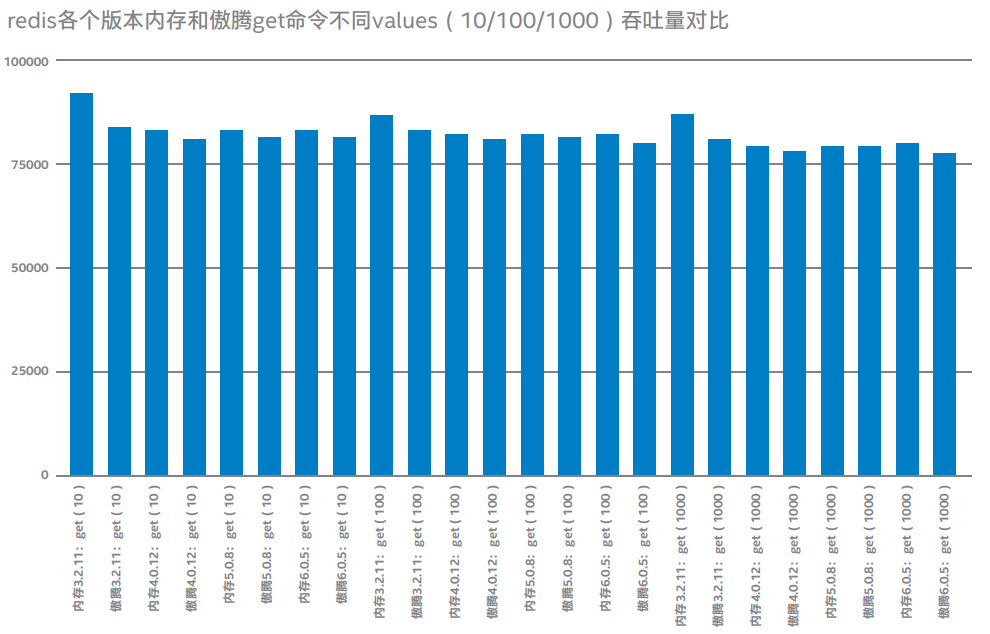
说明:上图为当Redis单进程cpu负载80%左右的情况下,在内存和傲腾不同存储上分别运行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,当get命令value为10、100、1000字节每秒处理请求个数压测结果对比。
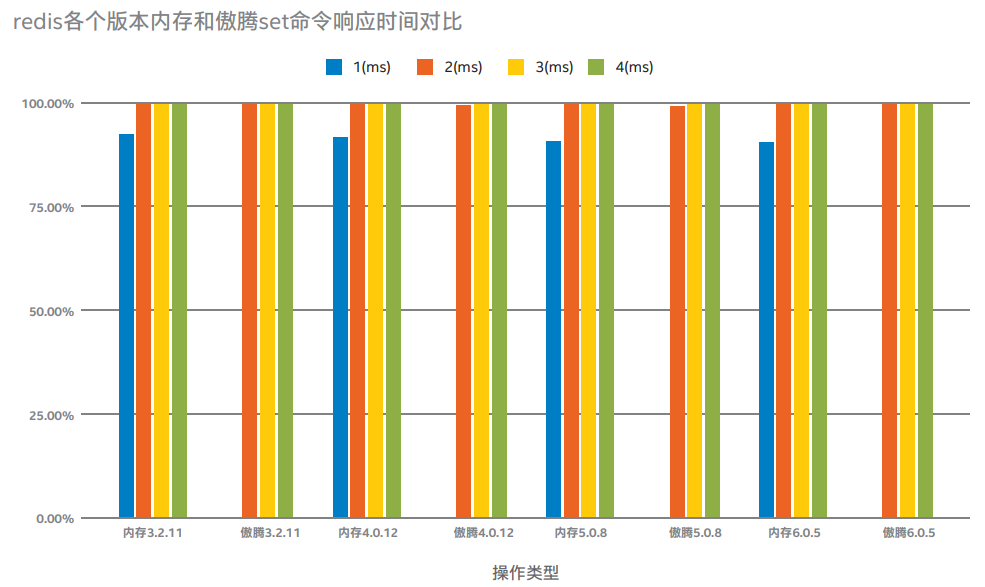
说明:上图为当Redis单进程cpu负载80%左右的情况下,在内存和傲腾不同存储上分别运行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,当set命令value为10、100、1000字节响应时间分别为1、2、3、4毫秒的百分比压测结果对比。
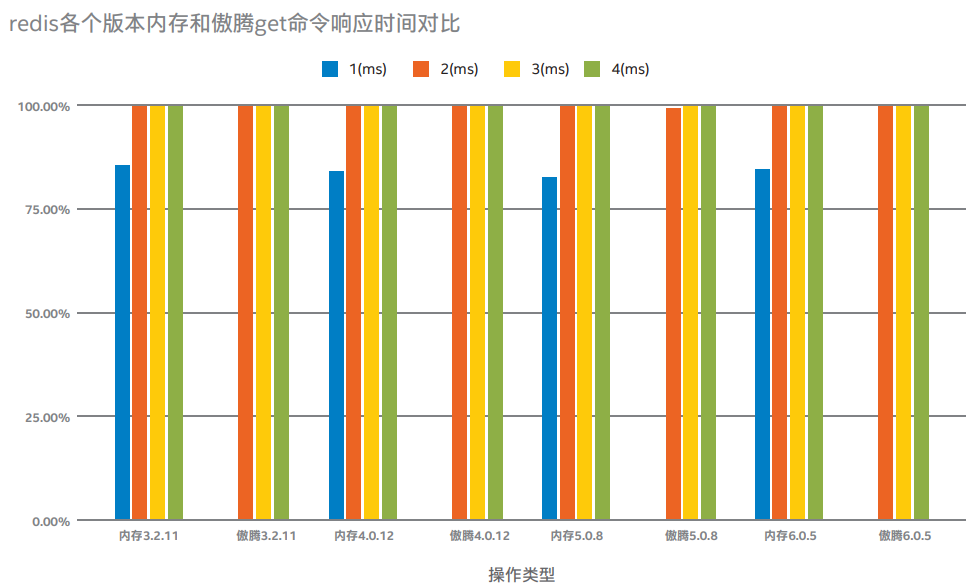
说明:上图为当Redis单进程cpu负载80%左右的情况下,在内存和傲腾不同存储上分别运行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,当get命令value为10、100、1000字节响应时间分别为1、2、3、4毫秒的百分比压测结果对比。
密集部署调度是否能打散
1.redis集群1个节点下主从不在同一个机柜组。
2.redis内存利用率大于50%不再调度新实例
3.一个机柜组承载每个集群不超过25%的实例数。
4.扩容k8s集群中node后新增实例的打散依然符合以上规则。
密集部署宕机业务影响范围
1.业务恢复时间从实例不可用到域名切换完成耗时20~40s之间。
2.拓扑恢复时间完全自动化,DBA关注进度就好,宕机服务器500+G内存恢复需要30min左右。
密集部署遇到的问题
1>.整点cpu高,慢日志数量增多,业务出现规律性超时。
原因:
1.每个docker容器整点执行收集Redis客户端连接,遇到客户端连接多的情况尤为严重。
2.每个docker容器整点执行收集Redis元信息的任务。
3.每个docker容器整点执行anacron任务。
解决方案:
1.降低定时任务收集客户端连接的频率。
2.随机打散定时任务的执行时间。
3.去掉不必要的定时任务。
2>.sentinel高可用服务自动切换部分失败。
原因:
1.sentinel服务线程数不够,丢弃部分待处理任务。
2.sentinel元信息更新失败问题。
解决方案:
1.优化sentinel服务线程数。
2.优化更新sentinel元信息的版本控制。
3>.sentinel高可用服务异常切换慢。
原因:
1.异常检测周期长。
2.域名切换耗时高。
解决方案:
1.异常检测周期由原来30s降低到10s。
2.优化域名切换接口索引缺失问题由原来平均30s降低到3s。
4>.Redis负载高,操作系统卡顿。
原因:
1.docker容器管理Redis进程,sentinel-agent组件沿用物理机部署版本,线程数过高导致操作系统卡。
2.每个docker容器部署了repl-agent组件。
3.每个docker容器的cadvisor监控项过多。
解决方案:
1.优化sentinel-agent组件降低线程数。
2.下线repl-agent弃用组件。
3.优化cadvisor监控项数量
5>./var目录容量满出现Redis所在容器被驱逐。
解决方案:
1.将coredump日志记录到较大分区。
2.优化各个分区容量的使用的报警等级。
6>.Redis宿主机重启后二次调度,导致数据异常。
解决方案:
1.任务原因导致的宿主机宕机,自动进行调度隔离。
管理方式变更
1>.Redis资源申请 1.目前可以做到Redis资源分钟级别交付。
2>.增加异常诊断
1.基于Redis、操作系统,中间件层快速聚合分析到历史时间段的异常指标。生成集群诊断报告。
2.通过获取Redis实时monitor日志,分析出热点数据,输出热点报表信息。
3>.异常处理预案
1.增加了sentinel服务异常后宕机批量切换工具。
2.增加了主从同时宕机批量从异地备份机恢复数据的工具。
4>.增加集群画像
1.集群列表页关联业务组,划分权限,只显示各自归属集群,方便业务方查看。
2.业务方更详细了解集群基础信息(架构、分片、机房等)和性能信息(访问量、容量等指标的实时统计和天级统计)。
3.基础数据完整和准确,有效实施后续自动化功能建设。
4.实时统计、天级统计信息可定时产出报表,分析低访问量、慢查询多等集群。
5.集群信息完整,出问题时可以快速定位业务方、访问源服务、关联申请原工单、操作类型统计等维度方便排查。
阶段工作成本对比

总结
1.非核心业务可以先上AEP,如果性能不够再迁移到纯内存服务器上。
2.目前存量小实例继续进行迁移。
3.性能和TCO优势分析: 英特尔® 傲腾™ 数据中心级持久内存在新的推荐异构存储系统和升级后 的Redis 服务中,不仅有着与 DRAM 内存相近的性能表现,其大容量 和非易失性还可帮助实现更优的可用性;通过不同的硬件组合,为不 同应用场景下的存储需求提供高性能,高可扩展、安全可靠以及低 TCO的解决方案;在满足应用性能需求的同时,内存的采购成本还得 到显著降低,并减少了集群所需的节点数量,进而降低了TCO。















