加速CPU设计,Arm再出新招
在服务器领域获得新的计算引擎需要很长时间,而且每个人都在抱怨。客户很不耐烦,因为他们想要新一代芯片带来的更高性能和更高性价比。那些制造 CPU、GPU 和其他计算引擎的人也很不耐烦。他们想要压垮竞争对手并赚更多的钱。
在本周的 Hot Chips 2023 上,Arm Ltd 在宣布(再次)上市后展示了其“Demeter”V2 内核,该公司还推出了“Genesis”N2 计算子系统,简称 CSS 智能包。(我们将单独深入探讨 V2 核心。)Genesis 的这一努力有可能比过去更快地让 Arm CPU 进入该领域。
多年来,Arm 一直在朝着将成熟的 CPU 组装在一起以供客户修改并直接推向市场的目标迈进。早在 2000 年代末,当 Arm 接管智能 手机 时,服务器制造商正在考虑 Arm 架构如何改进基本上处于垄断地位的 X86 架构,服务器芯片设计人员从 Arm 架构许可开始,并开始使用它。这是一种非常昂贵且耗时的创建服务器芯片的方法,尽管比从定制 ISA 开始要好,但由于大量的软件移植工作,世界无法容忍定制 ISA。
在 Broadcom、高通、AMD 和三星等老牌半导体巨头以及 Calxeda 和 Applied Micro 等初创公司多次尝试 Arm 服务器芯片失败后,以及 Cavium 凭借其 ThunderX 和 ThunderX2 CPU 取得了一些有限的成功后,Arm 决定将其推出。Neoverse 的工作于 2018 年 10 月推出,它不仅提供了服务器芯片核心的路线图,还提供了参考架构,用于将这些核心转变为适当的 CPU,并混合了其他 Arm 知识产权(例如片上芯片)网状互连和第三方内存、PCI-Express 控制器和以太网控制器。这些 Neoverse 设计是针对台积电的特定工艺节点量身定制的,这使得服务器芯片制造商更容易更快地采取行动。
我们从来不确定 Neoverse 是否比架构许可证更便宜或更贵。你可以用多种不同的方式来论证它。Neoverse 完成了更多的工作,但与 Arm 架构许可证相比,自由度有限。也许更重要的是,正如我们所说,如果 Arm 不能比开源的 RISC-V ISA 和设计更便宜,那么它可以更快。由于客户不耐烦,Arm 无论如何都必须更快。
以下是2022 年 9 月公布的最新 Neoverse 路线图:

最初,只有一个内核系列 - N 系列 - 但 Arm 将其分为三个内核系列和三个相应的平台,每个平台都针对系统市场的不同部分。N 系列核心和平台针对主流服务器工作负载,其中每瓦性能驱动设计,而 V 系列具有更重的矢量处理,针对计算密集型工作负载,例如 AI 训练和推理以及 HPC 模拟和建模。E 系列旨在实现吞吐量计算,并且不仅针对更高的每瓦性能进行了优化,而且还以比 N 系列更低的热封装实现了最大吞吐量。现在不仅有三个系列的内核和平台,还有两种方法:DIY 和 CSS。
所以现在新的 Neoverse 路线图看起来像是硬塞进去了 CSS 选项:

我们已经为我们所知的每个核心和平台添加了代号。
Neoverse 的努力让芯片公司在设计上取得了优势,而且许多公司已经做到了。富士通的 A64FX 芯片比当前任何供应商都早得多(比 Neoverse 的努力早了很多年),并且在许多方面都可以被视为“Kronos”V0 实现,因为它发明了可扩展矢量扩展并将其带入了-Intel AVX-512 的位向量极限。亚马逊在其 Graviton1 芯片中使用了原始 Neoverse 堆栈中的“Maya”Cortex A72,在其 Graviton2 芯片中使用了“Ares”N1,在其Graviton3 芯片中使用了“Zeus”V1。
十多年前,Nvidia 最初使用其 Arm 架构许可来创建“Denver”服务器处理器,但已改用“Grace”CPU 芯片的 V2 内核现在即将上市。AmpereComputing 的 Altra 和 Altra Max Arm CPU 中使用 N1 内核,但现在正在开发定制内核。显然,阿里巴巴已经为其倚天 710 处理器定制了 Arm v9 核心,如果这是真的,那么 Nvidia 的 Grace 并没有市场上第一个 Arm v9 核心。印度政府正在其“Aum”A48Z 处理器中使用 V1 内核。
还有其他的,但这些是最重要的。他们都花费了大量资金来创建 Arm 服务器芯片。但这既关乎时间,也关乎金钱。众所周知,爱因斯坦证明了时间就是疯狂的金钱,也证明了能量就是疯狂的物质。

正如 Arm 产品管理高级总监 Jeff Defilippi 在 Hot Chips 上的 Arm 演讲之前解释的那样,随着摩尔定律的耗尽,对专用芯片的需求不断增长,芯片设计人员面临的压力也在不断增加。正如上图所示,随着晶体管尺寸的缩小,设计芯片的成本也在上升,而在 7 纳米节点之后,每个晶体管的制造成本也在上升,但该图没有显示这一点。
Arm 的 CSS 知识产权包旨在加快设计速度,从时间就是金钱的意义上来说,至少可以将金钱转化为节省的时间,正如爱因斯坦所证明的那样,这既是节省的金钱,也是通过早期销售获得的金钱。(我们假设 CSS 的成本比常规 IP 许可更高,因为它包含更多内容,但风险要低得多,而且成本和风险的乘积(不是总和,而是乘积,因为这些是乘法效应而不是累积效应)因此较低.)
从概念上讲,CSS 包如下所示:
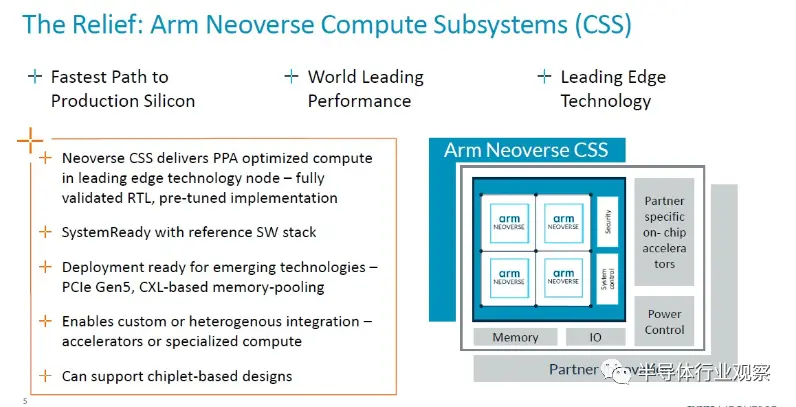
以下是它与 SoC 许可、IP 许可和架构许可的比较:
“本质上,该产品是 Arm 拼接在一起的多核设计,”Defilippi 解释道。“这就是互连、CPU、虚拟化 IP 要求 - 我们将它们缝合在一起,进行验证,并将其作为生产就绪的 RTL 可交付成果交付给我们的客户。除了 RTL 之外,我们还提供与之相关的额外好处:我们提供实现包、平面图、实现脚本以及达到该性能所需的物理 IP 库以及设计所需的功耗范围。领先的技术。我们提供完整的软件参考堆栈。因此,这包括从固件、电源管理、系统管理、系统所需的运行时安全性等一切内容。我们提供参考堆栈,以确保软件开发从第一天开始,并且我们的客户有一个良好的起点。最后但并非最不重要的一点是,我们不仅包括工艺节点,还包括我们的领先技术。每年都会有一些新的、令人兴奋的事情出现。当然,现在的一个例子就是 CXL 内存扩展池。”
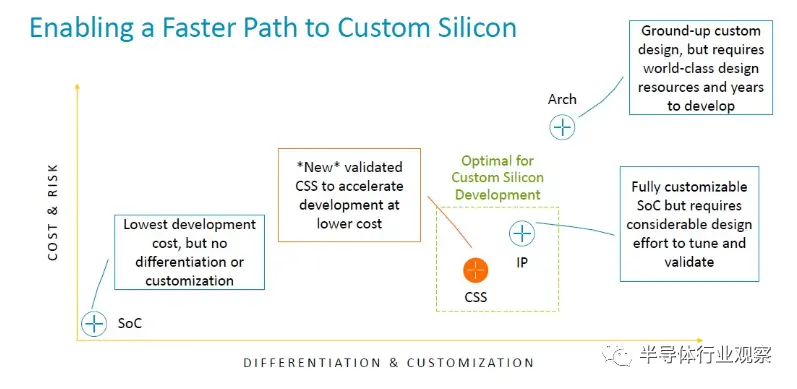
现在想象一下,特别是如果您位于中国、印度、非洲,甚至位于美国或欧洲的具有成本意识的超大规模企业、云构建商或 HPC 中心,并且您没有大量熟悉高级服务器 CPU 的熟练工程师设计或正确设计和测试它们的工具,以便快速推出下一代芯片。那么 CSS 方法不仅可以大大加快速度,而且可以从一开始就制造出芯片。
但时间很重要,以下是 Arm 如何计算通过 CSS 包与使用普通 IP 许可证相比节省的时间:
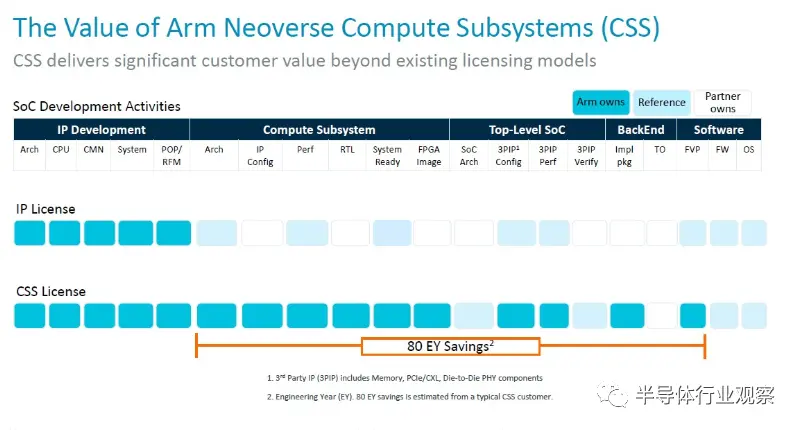
节省 80 个工程师一年的时间是相当可观的,特别是在定制自由度仍然存在的情况下。
问题是:与芯片制造商所做的大量工作相比,CSS 设计的价值有多大?将芯片从概念变为服务器、网络设备或存储阵列需要多少成本?这比使用 Intel 或 AMD 的 X86 服务器或 AmpereComputing 的 Arm 芯片便宜多少?这些麻烦值得吗?
嗯,随着 AWS 和阿里巴巴制造自己的 Arm 芯片,而且有传言称谷歌也将这样做,微软、腾讯和百度(以及阿里巴巴、谷歌和甲骨文)也使用 AmpereComputing 的 Altra Arm 芯片,看来这是值得的。Arm CPU 为他们节省了资金,并且在他们的服务器群中所占的比例越来越大。而且,他们通过自己的努力拥有更直接的控制权,并通过与安培计算的紧密合作获得更间接的控制权。
当然,超大规模厂商和云构建商仍会购买大量英特尔和 AMD CPU。但正如我们多次说过的那样,这将是为了支持旧版 Windows Server,有时甚至是 Linux 应用程序,他们会故意对基于它们的实例收取额外费用,英特尔和 AMD 也会对底层芯片收取额外费用。没有人在我们看到的分层上串通一气,但英特尔和 AMD 没有动力与 Graviton 和其他公司竞争。他们只是将 15%、20%、25% 的超大规模和云机群让给 Arm,他们对无需打价格战就能获得 85%、80%、75% 的更大机群感到满意。
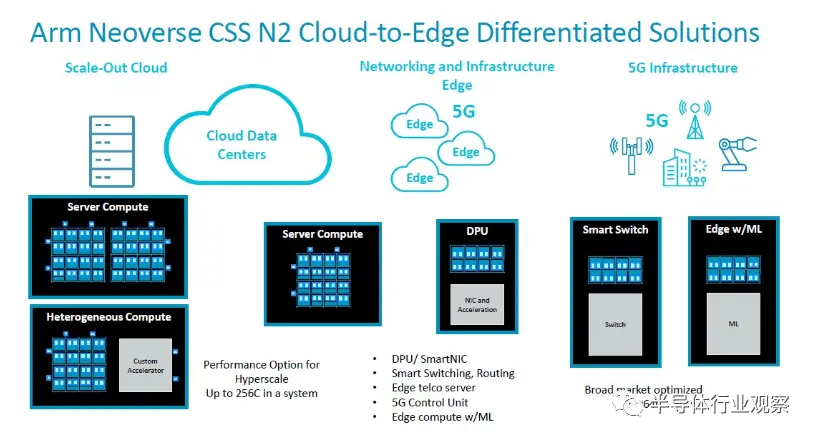
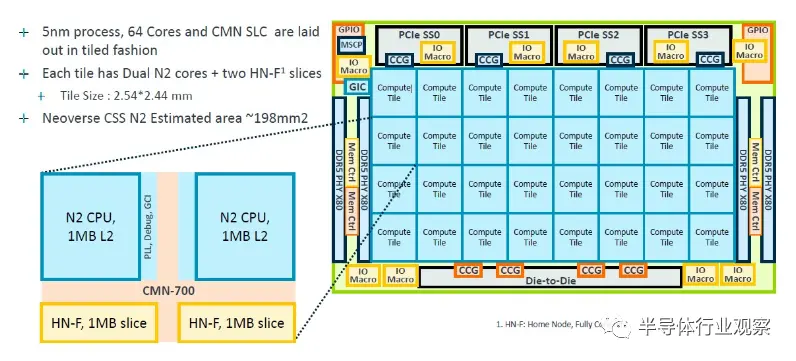
“Perseus”N2 核心网格的 CSS 实现可从 24 个核心扩展到 64 个核心,并且可以使用 UCI-Express(而非 CCIX)或专有互连将其中四个核心组合在一个封装中,以扩展到插槽中的 256 个核心。根据客户的需求提供小芯片。
考虑到许多现代处理器将执行预期的 HPC 和 AI 矢量数学,遗憾的是 V2 设计没有 CSS。也许这会发生——我们强烈鼓励这样做,当然也鼓励几年后的未来 V3 设计。目前,Arm 仅在 N2 设计中开始 CSS 工作,就在路线图的中间。
现在,请做好准备,欣赏 Genesis CSS N2 封装上的一些精美原理图和框图,这些原理图和框图由 Arm 院士兼芯片 IP 设计师的首席系统架构师 Anitha Kona 提供。
这是台积电 5 纳米 Genesis 封装中的 64 核基础模块:
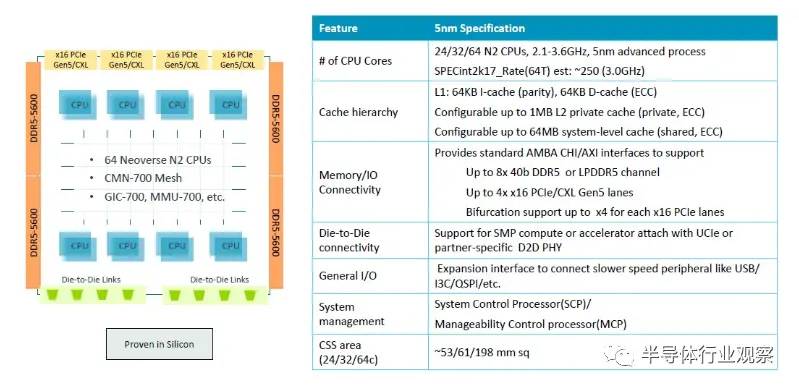
框图如下所示:
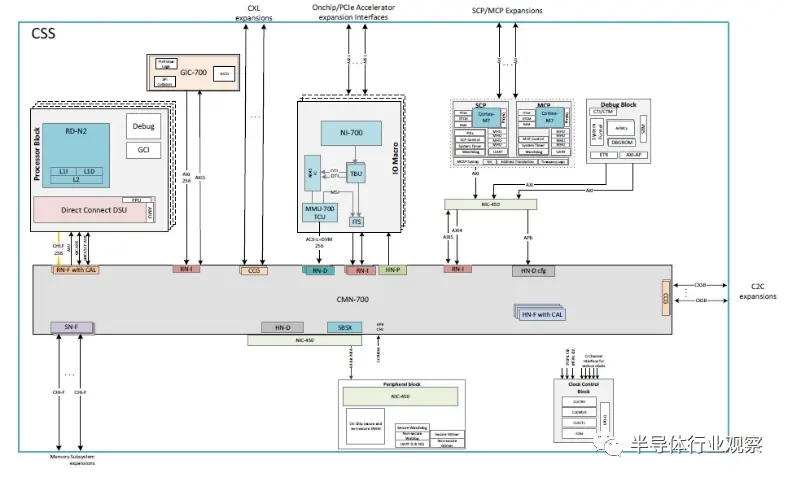
CSS N2 软件包符合 SystemReady 标准,符合 Arm 基础系统架构 1.0、Arm 服务器基础系统架构 6.1 和 Arm 服务器基础启动要求 1.2。
N2 核心是 Arm 的第一个 Armv9 实现,但 V2 核心不可能落后于 Grace 目前的水平,据我们所知,Nvidia 从 Arm 获得了 V2 核心。Nvidia 和 Arm 有可能在 V2 核心设计上进行合作,就像富士通和 Arm 在我们所说的 V0 核心上所做的那样。N2 核心的处理器模块如下所示:
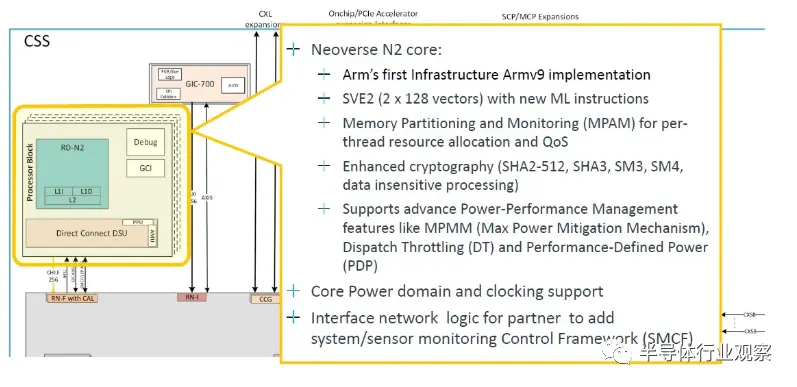
两个 SVE2 128 位向量还不错,但 V2 有四个。这就是需要 CSS V2 产品的地方,希望很快不会出现代号为“Exodus”的情况。就像,呃,现在。无论如何,这是系统控制和管理的深入内容:
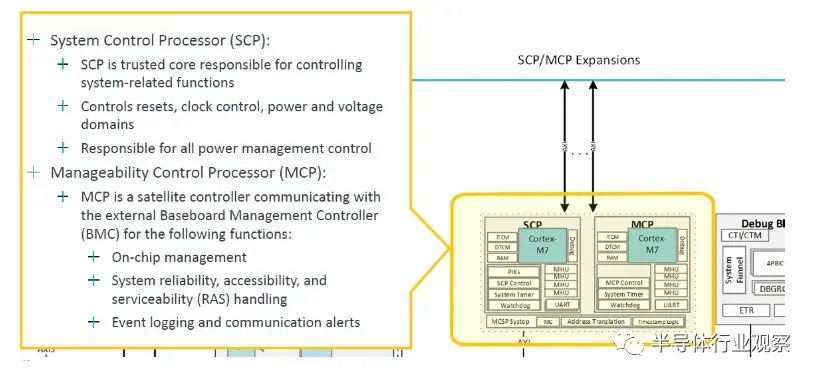
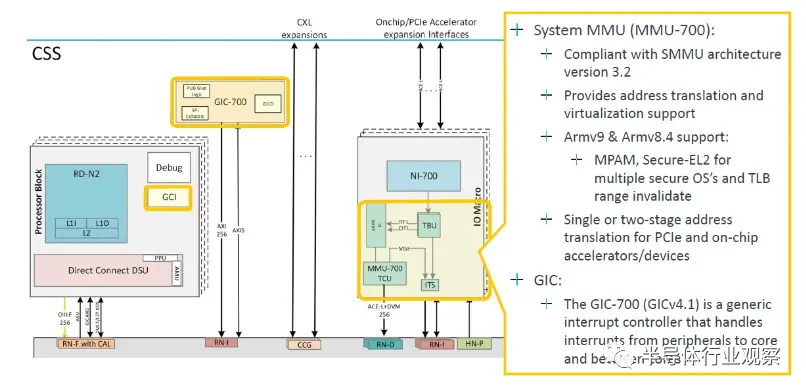
系统内存管理单元和中断控制器的放大是:
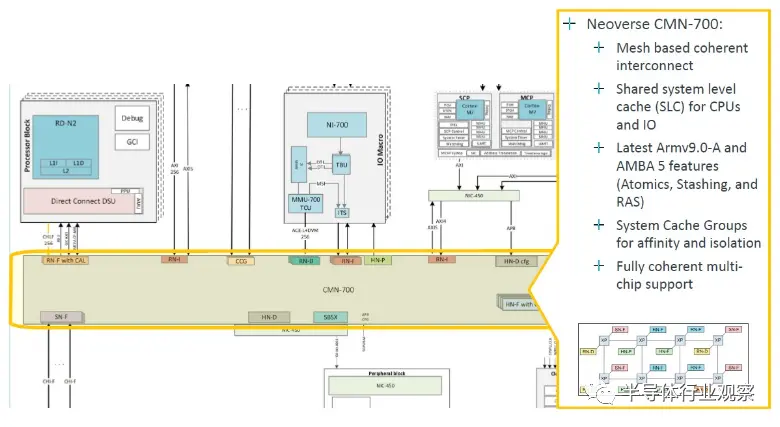
核心块使用 CMN-700 网格相互绑定,该网格已经存在了几年,并针对 Armv9 设计进行了调整,运行频率为 2 GHz:
Genesis 软件包包括 N2 CPU 的平面图,可以从 24 核扩展到 64 核,64 核平面图如下所示:
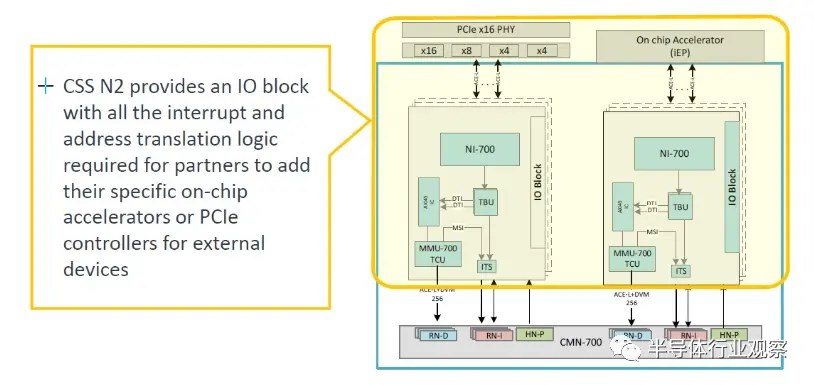
CSS N2 软件包还包括一个加速器连接块,允许卡入 PCI-Express 以及 CXL 控制器:
互连允许四个 64 核 N2 块中的两个相互链接。一对芯片利用芯片到芯片 PHY 实现直接对称多处理 (SMP) 链路,CXL PHY 用于交叉耦合其中一对,以创建具有 256 个内核的四路封装,例如这:
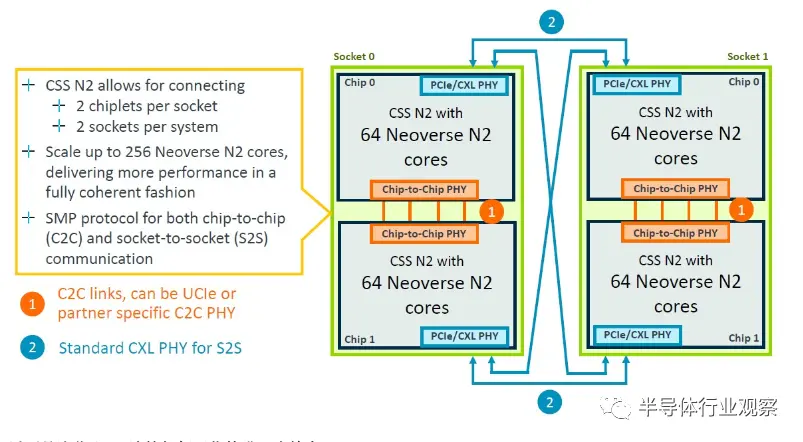
以下是这些 SMP 连接如何工作的进一步放大:
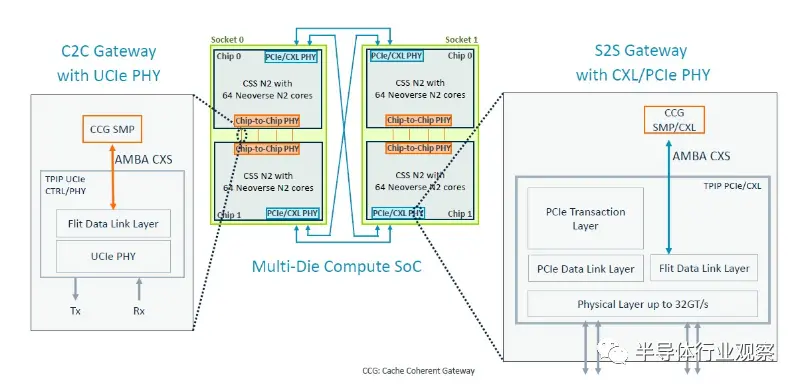
PCI-Express/CXL 块显然允许 CXL Type 3 内存扩展,超出嵌入在网格互连上的任何内存控制器。(如果内存控制器和以太网控制器是 Genesis 包的一部分,那将会非常有帮助。)
最后,这是 Generis 软件包中的软件:
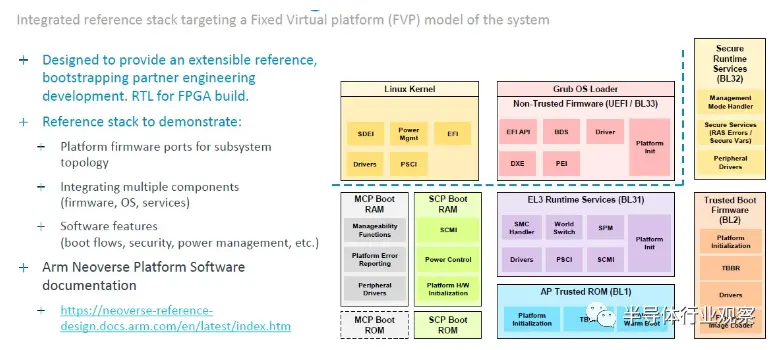
将所有这些加起来,Kona 表示 Genesis IP 包被许可方可以获取 CSS N2 堆栈,在内存、I/O、加速器和物理拓扑上进行差异化,并在令人惊叹的 13 个月内从启动到工作芯片,并节省80个工程师的开发努力。这些是来自两个不同的 Arm 合作伙伴的两项统计数据,他们是 Genesis 的早期采用者,因此在将这些数据位混合到一个承诺中时要小心。但显然,Arm CPU 芯片设计既可以节省时间,又可以节省金钱——这也是时间。
我们期待看到与 CSS N2 包相当的 V 系列和 E 系列。
【来源: 半导体行业观察】
























