技术解析| 仙途智能BEV感知技术在实际场景的深度实践
当前,中国自动驾驶渗透率和 商业 化步伐正在加速,感知系统作为实现高阶自动驾驶关键技术之一,吸引行业广泛关注,成为衡量自动驾驶企业技术竞争力的核心战场。
作为无人驾驶商业化领先企业,仙途智能深耕自动驾驶领域,凭借其全栈自研的无人驾驶技术栈和在乘用车、商用车以及垂直场景的深厚积累与场景拓展,在感知方面形成了完整、成熟的技术体系,自主研发了业内领先的兼具多任务、多模态、跨时序等特点的BEV多任务感知模块以及支撑BEV快速迭代的数据闭环系统。
垂直场景下仙途智能BEV感知技术突破
在传统的无人感知技术栈中,2D图像输入到感知模块以生成 2D感知结果,然后利用传感器融合技术对来自多个相机的2D结果、激光雷达的结果进行推理后传给下游。在这个过程中需要大量手工制定的规则,同时面临着遮挡、观测不全、信息损失等问题。为了克服以上问题,BEV技术将多传感器特征统一在同一个3D空间内,减少信息损失,以一种更简洁高效的、端到端的方式直接在3D空间内进行感知。基于BEV技术,仙途智能构建了一个面向环卫场景特色和作业需求的BEV多任务感知系统,具有以下特点:

图1:BEV多任务处理
多任务处理,应对复杂场景下感知挑战: 为满足复杂多变的环卫作业需求,仙途感知模块不仅支持传统交通场景中的常见检测任务(如车辆、行人、交通标志等),还针对环卫场景新增低矮障碍物检测、路沿检测、垃圾检测、扬尘水雾识别过滤、可碰撞检测等任务。同时,相比于每个任务单独1个小模型的方案,BEV多任务感知模块使用共享骨干网络的网络结构,计算负担降低30%以上,确保了自动驾驶车辆的实时环境感知能力。
多模态融合,提供精准、实时的感知支持: BEV感知推理以环视图像、多激光雷达点云作为输入,具备跨多模态、跨多传感器的信息聚合能力,能够补齐单模态感知的短板。仙途智能BEV感知精度相较于纯视觉算法提升32.6%以上,单激光点云感知算法提升18.9%以上。同时具备可拓展性,能进一步接入更多传感器数据。
跨时序感知,实现精准目标速度预测: BEV感知具备多帧点云输入和多帧特征聚合的跨时序感知能力,能够在长时间范围内补全当前帧中的信息缺失,提升感知精度,并具备更精确的目标运动速度预测能力。
可以通过以下场景实例,深入了解仙途智能的BEV多任务感知技术是如何高效解决复杂交通场景中的挑战以及处理长尾问题。
场景实例:BEV多任务感知模块在复杂场景下的应用实践
场景1:提升低矮障碍物检测精度,确保自动驾驶车辆高效作业
低矮障碍物是无人环卫极具挑战的场景之一:1.相比常见的车辆、行人等交通参与者,低矮障碍物呈现出种类繁多、数量稀少的长尾分布特点,如水管、石块、倒地的铁铲、坑洞、保温杯等;2.由于部分低矮障碍物形状大小各异,激光雷达往往无法稳定扫描到;3.对于无人驾驶车辆而言,必须精准判断哪些障碍物需要绕行以避免碰撞,哪些又可以安全地进行清扫作业;4.即便是相同类型的障碍物,其大小、状态及内容物的不同也会显著影响决策结果,例如,细小的枝条可以直接清扫而不必绕行;然而,粗壮的大枝条则可能因堵塞清扫设备的吸口而需要车辆采取绕行策略。
针对上述挑战,仙途智能设计了一套以视觉为主、激光为辅的、结合2D+3D的多传感器检测方案,同时通过引入对障碍物的属性预测+occupancy预测,并结合垃圾检测技术,能够准确预估障碍物的尺寸、高度等关键参数,从而有效辅助决策系统判断是否需要绕行或进行清洁作业。

图2:玫红色色块为低矮障碍物识别结果:黑色细水管

图3:玫红色色块为低矮障碍物识别结果:黑色垃圾袋

图4:玫红色色块为低矮障碍物识别结果:
黑色垃圾堆与展开的塑料布袋

图5:玫红色色块为低矮障碍物识别结果:
不可以清扫的白色垃圾堆
上述4张图片分别显示了自动驾驶车辆在遇到低矮障碍物的情形,从图2到图5,其作业场景地面上分别有黑色细水管、黑色袋子、黑色垃圾堆与展开的塑料布、不可清扫的白色垃圾堆。
可以看到,当自动驾驶车辆行驶在上述四个场景中,仙途智能BEV感知模块输出的occ占据栅格有不同的颜色色块,低矮障碍物识别的位置精度和朝向都非常准确,为自动驾驶车辆在复杂的路面环境下安全作业、顺畅地行驶提供了强有力的保障。
场景2:复杂路况的3D目标检测,提供更全面的环境感知
在复杂道路状况下,感知系统面临挑战诸多:交通拥堵中人车混行,目标密集与遮挡、不规则路面的感知与适应、动态变化的环境与突发情况等。

图6:仙途智能BEV感知在繁忙路口的3D检测综合能力对狭窄道路上众多擦肩而过的交通参与者稳定检出及动态预测
如图6,在繁忙的交通路口中,车辆来自各个方向,包括同向行驶的车辆、反向行驶的车辆、准备转弯的车辆,以及大量占用车道或人行横道的行人、自行车等,仙途智能BEV感知系统在这样环境下检测出车辆周围的障碍物、行人、自行车的位置、速度、方向和尺寸等信息,为自动驾驶车辆在行驶作业中提供了周围环境全方位、360度精准感知。
场景3:BEV路沿检测,位置与形状的高精度识别与追踪
在环卫作业场景中,无人驾驶车辆需要实现贴边清扫,这就要求车辆能够准确识别并追踪路沿的精确位置和形状,以确保清扫作业的准确性和安全性。但现实道路环境复杂多变,路沿的不同形态(直线、曲线、折线),以及路沿上覆盖的不同物体(植被、低矮),都对路沿识别的准确度和鲁棒性形成了挑战。
为此,仙途智能在BEV网络中引入BEV路沿检测任务,将路沿划分成不同网格,利用深度学习网络提取图像与激光雷达对应的特征,拟合出各个网络内部的路沿,再结合几何特征与地图先验进行拼接,以实现对不同形状路沿准确识别;同时,路沿检测任务引入时序信息,结合多帧结果进行滤波,进一步提升了结果的稳定性。

图7: BEV路沿检测,精确检测路沿弯度与位置(红色曲线为路沿检测结果)
如图7显示,仙途智能BEV感知系统精确显示了弯道中路沿的弯曲程度,使车辆根据路沿信息选择合适的速度,确保高贴边率。
场景4:3D语义分割,有效识别环境中的水雾、灰尘
由于环卫场景的特性,无人驾驶车在洒水作业或行驶时扬起的水雾和灰尘,经激光雷达检测容易形成障碍物,影响正常通行。为此,仙途智能BEV感知系统通过结合图像、激光雷达预测每个激光点的语义信息,实现对自车扬尘、水雾和他车溅水的识别和过滤。

图8:水雾处理前

图9:水雾处理后
如图8无人驾驶车辆洒水作业场景中,车辆周围被密集的水雾所笼罩,单从点云模态来看会误检成障碍物。BEV感知系统通过多模态的点云语义分割技术,精确识别并剔除这些由水雾产生的噪点有效降低了恶劣天气和洒水作业对自动驾驶车辆感知精度的影响(图9)。
仙途智能构建高效数据闭环,加速研发迭代,实现降本增效

图10:数据闭环方案
数据闭环已经成为自动驾驶解决长尾问题的核心策略与关键路径,如何对数据进行大规模高效处理并快速优化算法模型,成为自动驾驶技术迭代的关键。仙途智能的无人驾驶车辆已在全球累计行驶超过1300万公里,基于这些海量数据,通过构建高效的数据挖掘-标注-仿真-模型迭代的数据闭环(图10),实现自动驾驶技术的快速迭代和降本增效。
数据挖掘,丰富长尾数据库

图11:特定场景数据挖掘
如图11展示了仙途智能通过大模型进行长尾场景数据挖掘的示例。仙途智能构建了基于文字到图像的多模态模型,当需要获取特定类型的场景数据,只需通过自然语言文字描述,比如“非站立行人”,即可从海量历史数据中自动挖掘符合条件的场景数据,提高了挖掘长尾场景的效率,基于挖掘出的场景数据则会进入自动/半自动标注处理,用于模型训练。
数据自动标注,实现成本节约与效率提升

图12: 3DBox自动标注:蓝色黄色box为自自动标注的车、人,其中箭头标注了其朝向
针对海量未标注的数据,仙途智能一方面通过半监督、数据增强等方式提高未标注数据的利用率(相关工作发表于CVPR2022、ECCV2022和ICRA2024);另一方面研发基于BEV多模态的自动标注系统,成倍提升了标注效率,大大缩短了模型迭代周期,显著降低标注成本。
2D数据仿真+3D数据仿真,提升BEV感知模型泛化能力
在数据仿真层面,仙途智能通过2D和3D数据仿真相结合,模拟出高保真的长尾场景,丰富了自动驾驶算法的训练数据,为自动驾驶感知算法模型提供更全面的训练和测试环境。
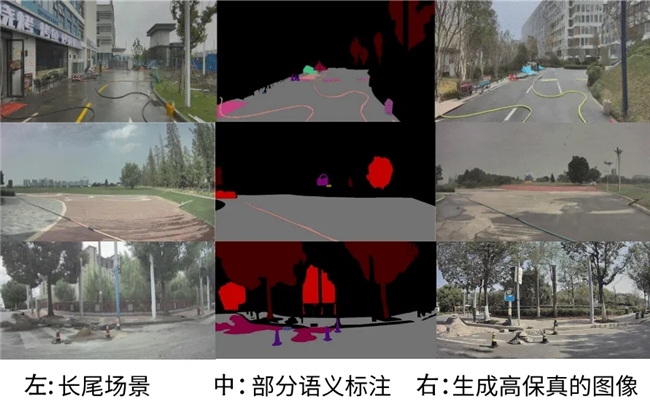
图13:2D数据仿真实例
如图13展示了2D数据仿真的实例。针对在实际运营中遇到的长尾场景(如图13左),仙途智能通过大模型或者人工对该类场景进行部分语义标注(如图13中),再由Diffusion Model生成高保真的图像,其中水管、桶、交通锥等经过标注的障碍物与原图具有较高的语义一致性,背景等未经过标注的障碍物也接近真实场景(如图13右)。通过这种多场景的生成与训练,仙途智能的自动驾驶车辆能够更好地适应各种复杂和不可预测的道路环境,从而提高整体的安全性和可靠性。
在3D数据仿真技术的应用实践中,仙途智能通过3D Gaussian Splatting技术对长尾场景进行重建,从而生成Corner Case高保真的新视角视图,显著丰富了长尾场景库,更好支持感知模型的训练和新场景测试。

图14: 车辆正常经过的场景

图15:场景建模后,生成的新视角数据
如图14呈现了车辆在正常行驶途中记录的场景,图中左侧悬空的细长警戒线属于驾驶过程中较为罕见的元素,对自动驾驶感知系统构成了极大挑战。仙途智能采用3D仿真技术生成了包含警戒线等这些障碍物在内的高保真的全新视角视图(见图15),尤其是悬空警戒线出现在前进道路这一关键视角,从而支持了“前进道路上出现悬空警戒线”这一新场景的测试,有效提升自动驾驶系统面对复杂环境时的泛化能力与鲁棒性。
以上,系统展示了仙途智能在自动感知系统领域所取得的技术革新与应用实例。未来,仙途智能将继续坚持“软硬结合”的技术路径,积极探索感知技术应用场景,分享最新研究成果,聚焦自动驾驶商业化落地,推动自动驾驶技术革新。