首次在实验室合成由 AI 预测的蛋白质,蛋白质语言模型 ProGen - IT思维
公众号/ ScienceAI(ID:Philosophyai)
编辑 | 绿萝
人工智能已经将蛋白质工程研究的时间缩短了数年。深度学习语言模型在各种生物技术应用中显示出前景,包括蛋白质设计和工程。
现在,来自 Salesforce Research、Tierra Biosciences 和加州大学的研究团队首次在实验室中合成了由 AI 模型预测的蛋白质,并发现它们与天然对应物一样有效。他们开发出一种名为 ProGen 的蛋白质工程深度学习语言模型。ProGen 接受了来自公开的已测序天然蛋白质数据库中的 2.8 亿个原始蛋白质序列的训练,从头开始生成人工蛋白质序列。最新方法有望用于研制新药。
科学家表示,这项新技术可能比获得诺贝尔奖的蛋白质设计技术定向进化更强大,它将通过加速可用于几乎任何事物的新蛋白质的开发,这些新蛋白质几乎可以用于从治疗到降解塑料的任何领域。从而为已有 50 年历史的蛋白质工程领域注入活力。
该研究以「Large language models generate functional protein sequences across diverse families」为题,于 2023 年 1 月 26 日发布在《Nature Biotechnology》上。

论文链接:https://www.nature.com/articles/s41587-022-01618-2
蛋白质工程的传统方法是对天然蛋白质序列进行迭代诱变和选择,以鉴定具有所需功能和结构特性的蛋白质。相比之下,合理或从头设计蛋白质的方法旨在提高创造具有所需特性的新蛋白质的效率和精度。
基于结构的从头设计方法采用基于生物物理原理的模拟,而协同进化方法则从进化序列数据中建立统计模型,以指定具有所需功能或稳定性的新序列。结构和共同进化的方法都有一定的局限性。
最近,深度神经网络已显示出作为蛋白质科学和工程的生成和判别模型的前景。它们学习复杂表示的能力对于有效地利用指数级增长的多样化和相对未注释的蛋白质数据来源可能是至关重要的——公共数据库包含数百万个未对齐的原始蛋白质序列
ProGen:蛋白质语言模型
受到基于深度学习的自然语言模型的成功启发,该研究团队开发了 ProGen,这是一种蛋白质语言模型,在数百万个原始蛋白质序列上训练,可生成跨多个家族和功能的人造蛋白质。

图 1:使用条件语言建模的人工蛋白质生成。(来源:论文)
ProGen 通过学习在给定原始序列中过去的氨基酸的情况下,预测下一个氨基酸的概率来迭代优化,没有明确的结构信息或成对协同进化假设。ProGen 以这种无监督的方式从一个大型、多样的蛋白质序列数据库中进行训练,学习了一种通用的、域独立的蛋白质表示,它包含局部和全局结构基序,类似于学习语义和语法规则的自然语言模型。训练后,ProGen 可以提示从头开始为任何蛋白质家族生成全长蛋白质序列,与天然蛋白质具有不同程度的相似性。
ProGen 是一个 12 亿参数的神经网络,使用包含 2.8 亿个蛋白质序列的公开数据集进行训练。ProGen 的一个关键组成部分是条件生成,即由属性标签控制的序列生成作为语言模型的输入提供。在自然语言的情况下,这些控制标签可能是风格、主题、日期和其他实体。对于蛋白质,控制标签是蛋白质家族、生物过程和分子功能等属性,可用于公共蛋白质数据库中的大部分序列。
为了创建模型,科学家们只需将 2.8 亿种不同蛋白质的氨基酸序列输入机器学习模型,让它「消化」信息几周。然后,他们通过使用来自五个溶菌酶家族的 56,000 个序列以及有关这些蛋白质的一些上下文信息来启动模型,从而对模型进行微调。
该模型迅速生成了一百万个序列,研究团队根据它们与天然蛋白质序列的相似程度以及 AI 蛋白质的潜在氨基酸「语法」和「语义」的自然程度,选择了 100 个进行测试。

图 2:生成的人工抗菌蛋白多种多样,在该实验系统中表达良好。(来源:论文)
从头开始生成人工蛋白质序列
为了评估功能,通过无细胞蛋白合成和亲和层析来合成和纯化全长基因。在 100 种天然蛋白质的阳性对照集中,72% 的表达良好。ProGen 生成的蛋白质在所有序列同一性箱中与任何已知的天然蛋白质的表达同样好。此外,使用 bmDCA7(一种基于直接耦合分析的统计模型) 设计了人工蛋白质,bmDCA 无法适应五个溶菌酶家族中的三个,并且对其余两个蛋白质家族表现出 60% 的可检测表达(30/50 蛋白质)。这些结果表明,与一批天然蛋白质相比,ProGen 可以生成结构良好折叠的人工蛋白质,即使序列对齐大小和质量限制了替代方法的成功,也能正确表达。
在第一批由 Tierra Biosciences 进行体外筛选的 100 种蛋白质中,该团队制作了五种人工蛋白质以在细胞中进行测试,并将它们的活性与鸡蛋清中发现的一种酶(称为鸡蛋清溶菌酶,HEWL)进行比较。在人类的眼泪、唾液和牛奶中发现了类似的溶菌酶,它们可以抵御细菌和真菌。
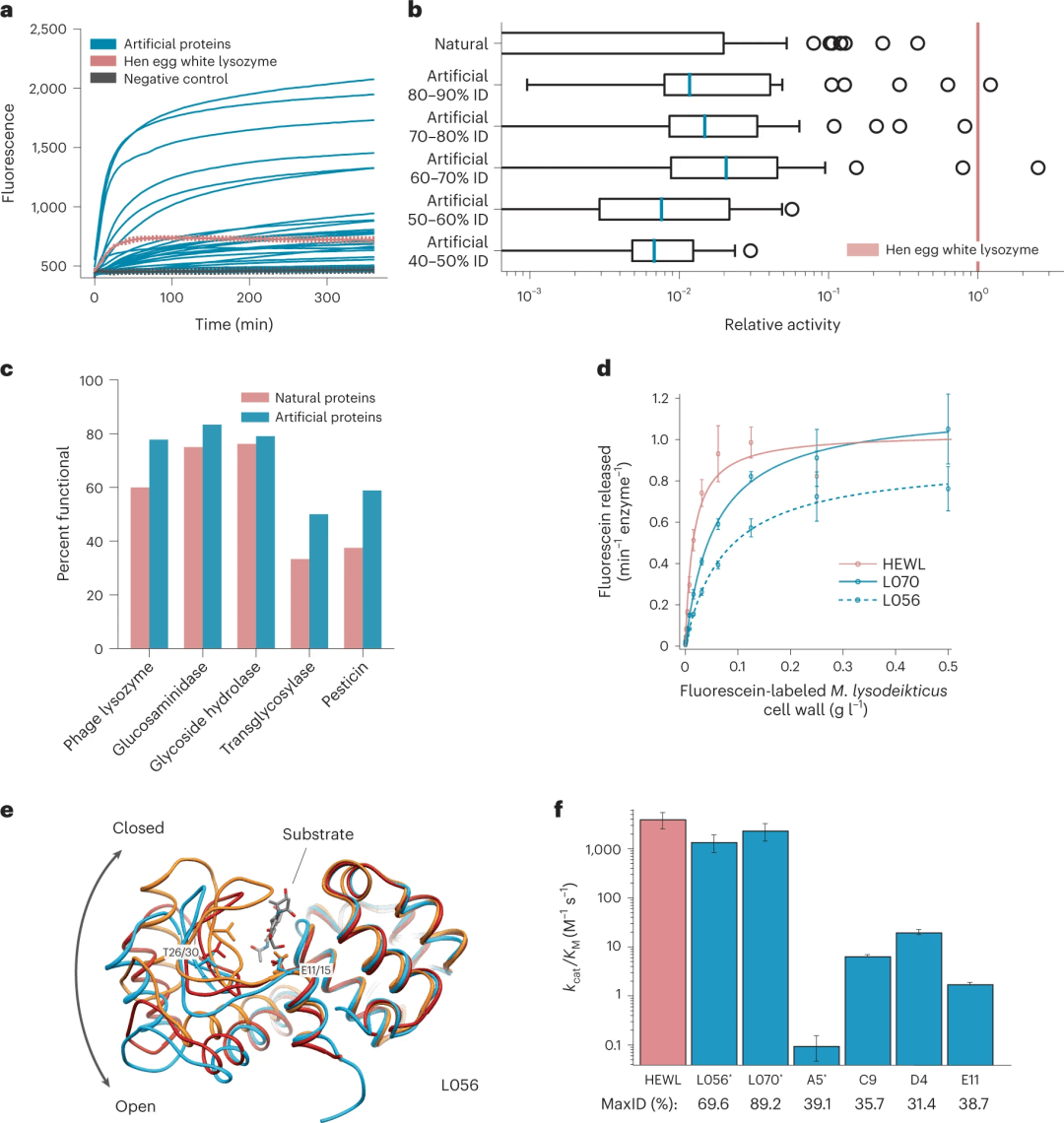
图 3:人工蛋白质序列具有功能,同时与任何已知蛋白质的同一性低至 31%,表现出与高度进化的天然蛋白质相当的催化效率,并展示与已知天然折叠相似的结构。(来源:论文)
结果表明,ProGen 生成的蛋白质序列不仅可以很好地表达,而且可以维持跨蛋白质家族的不同序列景观的酶功能。
其中两种人工酶能够以与 HEWL 相当的活性分解细菌的细胞壁,但它们的序列彼此只有约 18% 相同。这两个序列与任何已知蛋白质的同一性约为 90% 和 70%。
天然蛋白质中的一个突变就可以使其停止工作,但在另一轮筛选中,研究小组发现,即使只有 31.4% 的序列与任何已知的天然蛋白质相似,AI 生成的酶仍显示出活性。
为了解通用序列数据集和目标蛋白质家族序列对 ProGen 生成能力的相对影响,研究人员使用分支酸变位酶(CM) 和苹果酸脱氢酶(MDH)实验测量的测定数据进行了两项消融研究。
结果表明,训练策略的两个组成部分——对通用序列数据集的初始训练和对感兴趣的蛋白质家族的微调——对最终模型性能有显着贡献。使用包含许多蛋白质家族的通用序列数据集进行训练,使 ProGen 能够学习编码内在生物学特性的通用且可转移的序列表示。对感兴趣的蛋白质家族进行微调可以引导这种表示,以提高局部序列邻域的生成质量。
正在进入蛋白质设计的新时代
Salesforce Research 的研究主管 Nikhil Naik 表示,他们的目标是证明可以利用公开可用的蛋白质数据,将大型语言模型部署到蛋白质设计问题中。「既然我们已经证明 ProGen 有能力产生新的蛋白质,我们已经公开发布了这些模型,以便其他人可以在我们的研究基础上进行构建。」
「开箱即用地从头开始生成功能性蛋白质的能力,表明我们正在进入蛋白质设计的新时代,」该论文的第一作者,Profluent Bio 创始人、Salesforce Research 前研究科学家 Ali Madani 博士说,「这是蛋白质工程师可用的多功能新工具,我们期待看到治疗应用。」
本文中描述的方法的综合代码库可在:https://github.com/salesforce/progen 上公开获得。
参考内容:
https://phys.org/news/2023-01-ai-technology-generates-proteins.html
https://spectrum.ieee.org/ai-protein-design