MIT黑科技:无需视觉输入,立体声音频+摄像机元数据即可实现移动车辆定位
公众号/机器之心
选自 arXiv
作者:Chuang Gan、Hang Zhao、Peihao Chen、David Cox、Antonio Torralba
机器之心编译
声音在物体定位中会起到非常重要的作用,人们甚至可以利用自身对声音的感知来定位视线范围内的物体。在本文中,来自 MIT 计算机科学与人工智能实验室、MIT-IBM 沃森人工智能实验室团队的研究者提出了一套利用无标记的视听数据来自监督学习的算法,仅依靠立体音频和摄像机元数据就可以在视觉参考坐标系中定位移动的车辆。
论文:https://arxiv.org/pdf/1910.11760.pdf
项目链接:http://sound-track.csail.mit.edu/
声音能够传达我们周围现实世界的丰富信息,人类非常善于辨别身边物体产生的声音。我们经常可以根据物体发出的声音(例如狗叫声)来判断物体是什么,并且可以根据它们与其他物体相互作用时发出的声音来判断材料的属性(例如它们的软硬程度)。
此外,我们对声音的感知使我们能够定位不在视线范围内的物体(例如在我们身后或被遮挡的物体),并且在光线不足的条件下,声音在定位物体方面起着重要作用。重要的是,我们的视觉和听觉在根本上是一体的,例如,我们可以通过看或者闭眼听来定位目标并准确指出其所在方向。这种将听觉和视觉信息融合到共同参考坐标系中的本领使我们能够将听觉信息和视觉信息整合在一起(如果两者都存在),或者在另一个不存在时仅依赖其中一个。
本文介绍了一种系统,该系统可以利用未标记的视听数据来学习在视觉参考坐标系中定位物体(移动的车辆),而在推断时仅使用立体声即可。由于两个空间分离的麦克风之间有时延和声级差异,立体音频可提供有关物体位置的丰富信息。下图 1 给出了示例来说明该问题的解决方案。

图 1:以立体声为输入,本文提出的跨模态听觉定位系统可以完全从立体声和摄像机元数据中恢复参考坐标系中移动车辆的坐标,而不需任何视觉输入。
由于手动注释音频和目标边界框之间的关系需要大量人力成本,因此研究者通过将未标记视频中的视频和音频流的同时出现作为一种自监督的方式来解决这一问题,而无需通过真实标注。
具体来说,他们提出了一个由视觉「教师」网络和立体声「学生」网络组成的框架。在训练过程中,使用未标记的视频作为桥梁,将完善的视频车辆检测模型中的知识迁移到音频域。在测试时,立体声「学生」网络可以独立工作,仅使用立体声音频和摄像机元数据就可以进行目标定位,而无需任何视觉输入。
在新收集的听觉车辆跟踪数据集中的实验结果证明,本文提出的方法优于几种基线方法。研究者还证明了他们的跨模态听觉定位方法可以在光线不足的情况下帮助移动车辆的视觉定位。
本研究的目标是在没有任何视频输入的情况下,完全从立体声中恢复行驶中车辆的坐标。这类系统的实际应用场景十分广泛。例如,可以仅使用麦克风来部署交通监控系统,因为麦克风比摄像头便宜且功耗低,可以保护隐私,带宽占用少(仅在前期训练阶段才需要摄像头)。同样,可以使用融合的视听定位来增强机器人的视觉跟踪能力,即使在光线不足条件下也可以表现良好。
方法
本方法的核心是观察到未标记视频中视觉和声音之间的自然同步可以作为自监督的学习形式。因此,机器可以通过查看和听到许多产生声音的移动车辆示例来学习预测物体的位置。研究者使用师生框架(student-teacher framework)对学习问题进行建模。他们的系统使用视频帧和声音同时进行训练,这使得音频「学生」网络可以从视频「教师」网络中学习如何定位车辆边界框。
研究者首先介绍了跨模态听觉定位系统的基本组成部件,然后介绍了如何通过使用目标检测损失和特征对齐约束训练音频子网络,将视觉车辆检测模型中的知识转换为给定摄像机元数据的声音信号。最后,他们提出了一种时间平滑方法(temporal smoothing approach)来跟踪车辆时间。。
下图 2 概述了研究者提出的方法框架。

图 2:跨模态听觉定位「教师-学生」网络框架。
「教师」视觉子网络
本文中的听觉目标定位系统包含两个关键组件:「教师」视觉子网络和「学生」音频子网络。
如上图 2 所示,研究者将 YOLOv2 [31] 作为基于视觉的「教师」网络,因为它能同时保证目标检测的速度和准确性。
YOLOv2 的主干是 Darknet,它由 19 个卷积层和 5 个最大池化层组成。为了使其更适合于目标检测,最后的卷积层被具有 1024 个滤波器的三个 3×3 卷积层替换,随后是一个需要检测输出数量的 1×1 卷积层。类似于 ResNet 中使用的恒等映射(identity mapping),从最后的 3×3×512 层到倒数第二层的卷积层间还有一个转移层(passthrough layer),以聚合细粒度级别的特征。此外,为了使模型更稳定且更易于学习,网络经过训练以预测锚框位置的定位坐标。
为了准备数据,研究者首先将每个视频片段分解为多个 T = 1s 的视频片段,然后选择每个片段的中间帧作为「教师」网络的输入。在训练期间,每个中间视频帧被输入到 YOLOv2 模型中,并利用 Pascal VOC 2007 和 VOC 2012 数据集来进行预处理,从而得到车辆检测结果。为了使检测结果更平滑,他们还应用了非极大值抑制(non-maximum suppression,NMS)作为后处理。
「学生」音频子网络
研究者将目标检测从立体声转换为回归问题。他们将「教师」视觉子网络产生的目标检测结果作为伪标签,然后训练「学生」音频子网络以直接从音频信号中回归伪边界框坐标。考虑到不同的摄像头角度对视觉内容的影响可能会比音频更大,因此在训练音频子网络时,通过将摄像头的元数据作为输入来解决此问题。这里的元数据包括摄像机高度、俯仰角以及摄像机在街道的方位。
研究者首先通过短时间傅立叶变换(Short-Time Fourier Transform,STFT)将每个 1 秒的音频片段转换成声谱图。由于立体声中有两个通道,因此他们分别计算了它们的声谱图,然后将它们叠加作为音频子网的输入。
要将输入音频频谱图的 FT(频率-时间)表征转换为视觉视图,他们首先使用了 10 个跨步卷积层,其中每个卷积层后边都跟着批归一化层和 ReLU 激活函数,作为编码器将立体声音信号压缩为 1×1×1024 特征图,从而消除了空间分辨率。然后,他们使用多层感知器将元数据编码为 1×1×128 特征图。在将压缩的声音信息和已编码的元数据进行通道连接之后,由 2 个全连接层和 3 个反卷积层组成的解码器将用于重建空间分辨率,并将音频信息映射到视觉视图。最终输出结果与 YOLOv2 类似,并且研究者采用 YOLOv2 中使用的目标检测损失来训练音频子网。
实验
下表 1 是本文方法与基线方法的结果对比。

表 1:跨模态听觉定位在平均精度(Average Precision,AP)和中心距离(Center Distance,CD)的结果对比。
从上表中可以看出,当研究者用目标检测损失和特征对齐约束来训练跨模态听觉定位时,它的性能优于所有纯音频基线方法。使用跟踪后处理(tracking post-processing)可以进一步提升平均精度,还可以使跟踪更加一致和平滑。
研究者还分别测试了单个车辆和多个车辆的检测情况。结果如下表 2 所示:
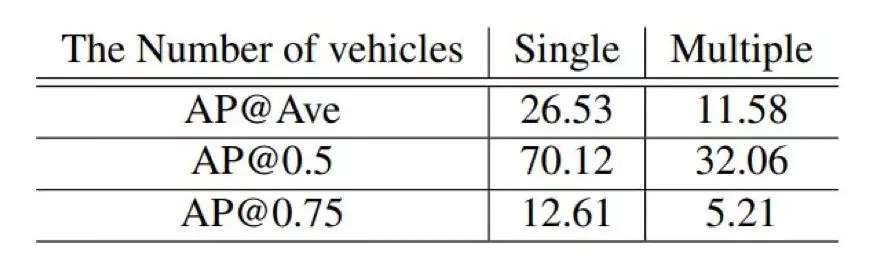
表 2:根据平均精度(AP)和中心距离(CD)得出的单个车辆和多个车辆的听觉车辆定位结果。
在下图 4 中,研究者可视化了输入声谱图和相应的立体声定位结果。
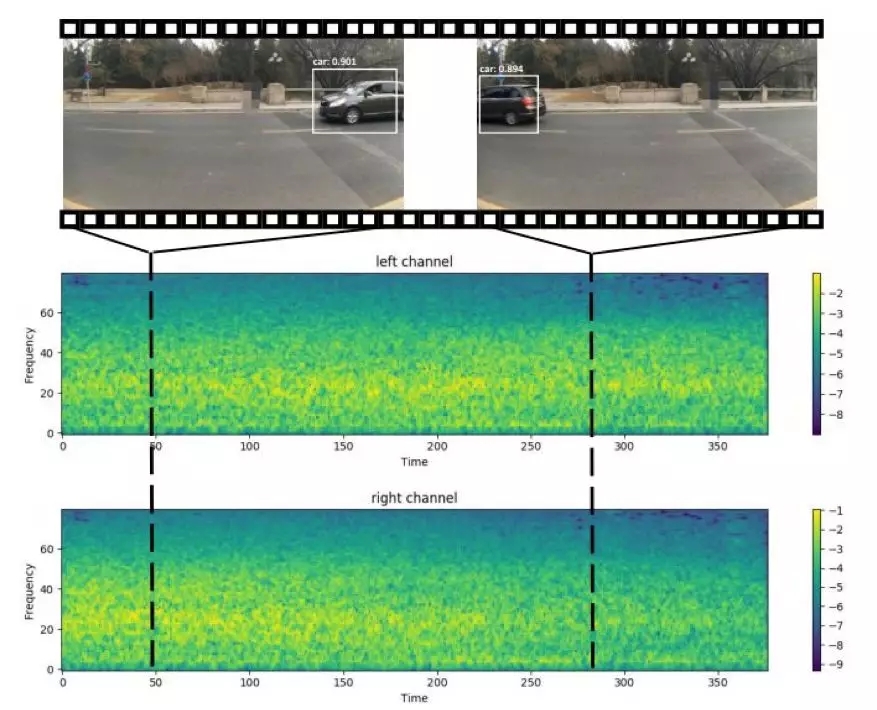
图 4:一个视频片段的跨模态听觉定位结果及对应输入声谱图的可视化。
如上图所示,在视频的开头,图像的右侧有一辆汽车,并且可以清楚地看到,右声道的频谱图振幅高于左声道。
对于无跟踪后处理的基线,研究者将 ID 随机分配给每个框,因为此类基线无法预测 ID。结果如下表 3 所示:

表 3:跟踪指标方面的结果对比。
研究者直接将经过白天数据训练的音频子网络应用于夜间场景,没有进行任何微调。结果如下表 4 所示:
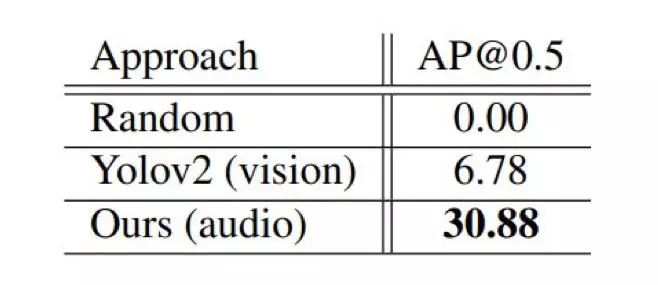
表 4:在恶劣照明条件下的听觉车辆定位平均精度(AP)。
研究者还可视化了一些有趣示例,如下图 5 所示:

图 5:(a)不同场景下跨模态听觉定位的可视化以及由于卡车、火车和杂物发出的嘈杂声音而检测失败的案例;(b)使用视觉目标定位系统的常见失效示例。
在下表 5 中,我们通过比较新场景的性能来探索听觉目标检测系统的泛化能力。
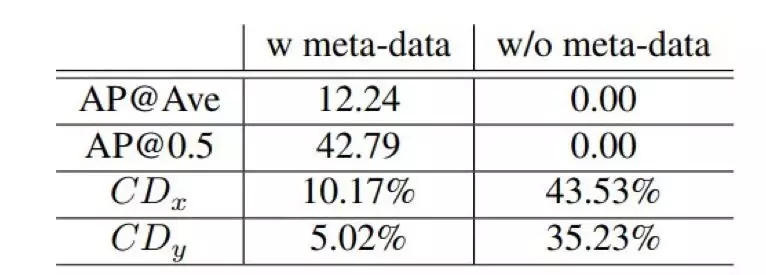
表 5:听觉车辆检测系统的泛化结果。









