清华评测更新!国产大模型强势出击,硅谷独霸已成历史 | 速途网

4月18日晚间,Meta正式发布全新一代开源模型Llama3。本次发布的Llama3涵盖了两个版本,即Llama3-8B和Llama3-70B,它以其8B的模型规模,超越了去年70B模型的性能。Meta宣称Llama 3-8B和Llama 3-70B是目前同体量下,性能最好的开源模型。
在开源与闭源路线的长期“较量”中,Llama 3的问世,无疑为开源社区注入了一剂强心针,不仅是对开源模式潜力的有力证明,更激励更多的企业和开发者加入到这一开放、协作的生态系统中。
针对Llama 3的具体能力表现,前不久,国内人工智能权威机构清华大学基础模型研究中心正式发布《SuperBench大模型综合能力评测报告》,测试了国内外数款大模型在语义、代码、对齐、智能体和安全五个评测集中的表现。

根据报告的评分结果,Llama3-70B模型的表现出色,其得分在众多国内外顶尖模型中位列第六位。
大模型之家还注意到,在SuperBench的评测榜单中,第一梯队的大模型已经不再是海外大模型“霸榜”的局面,有两款来自国内企业的大模型产品在语义理解能力表现中超越了Llama-3,其中一款是智谱AI开发的GLM-4,另一款是百度推出的文心一言4.0。可见,历经一年的技术发展与沉淀,全球大模型技术能力的竞争格局正在悄然发生改变,中国最前沿的大型人工智能模型已经达到了国际领先水平,成为全球人工智能领域的引领者。
多项评分领先,国产大模型对症下药飞根据SuperBench发布的评测报告,GLM-4在各项子项评测中均展现出优秀的成绩。特别是在知识-常识能力方面,GLM-4以77.3分的优异成绩荣登全球第二、国内第一的宝座。同时其强大的多模态处理能力使GLM-4不仅能处理文本信息,更能理解和生成图片、文件及视频内容,从而在图文理解和生成任务中脱颖而出,精准回应用户的复杂需求。

在长文本处理能力上,GLM-4具备128k的上下文处理能力,能够轻松应对长达300页的文本。在MMLU、GSM8K、BBH、HellaSwag等多个数据集上,GLM-4的表现均达到了GPT-4相应性能的94%至100%,展现出卓越的性能。
通过有机整合来自不同模态的上下文信息,GLM-4增强了对整个交互情境的理解能力,这种整合能力使得模型在应对需要综合多种信息源的复杂任务时,能够提供更加精准和全面的回答,进一步提升用户体验。
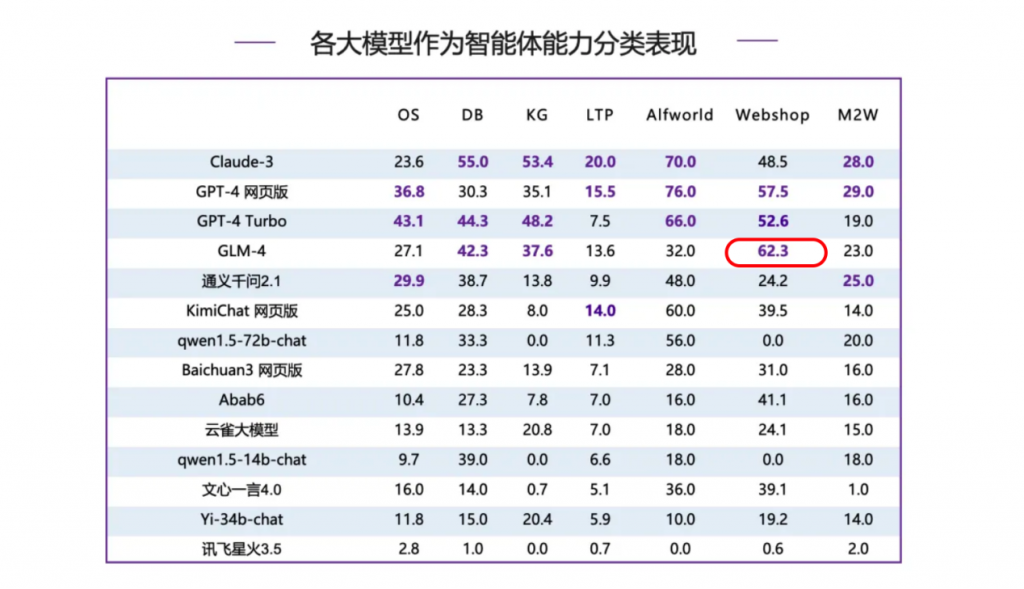
此外,在智能体能力方面,GLM-4同样表现出色,为产业化创造了条件。例如在电商场景中,依托出色的自然语言处理(NLP)能力,能够理解和解释用户的查询、评论以及商品描述,从而准确捕捉用户的购物意图和偏好。
通过先进的推荐系统技术,包括基于协同过滤、深度学习模型等,模型能够根据用户的个性化需求和行为数据,以及通过利用大规模数据处理和分析技术,实现对用户提供更具针对性和前瞻性的服务。
大模型之家还了解到,智谱AI推出了GLMs个性化智能体定制功能,允许用户无需具备编程基础,通过简单的语言提示轻松创建属于自己的GLM智能体,大幅降低大模型的使用门槛。

此外,GLM-4模型在图像生成和理解方面也实现了重大突破。通过集成CogView3代模型,GLM-4不仅能够生成具有艺术感的高质量图像,还能对图像内容进行深入分析和理解。这种能力极大地丰富了模型在处理涉及视觉信息的任务时的表现,使得GLM-4能够更准确地捕捉和回应图像中的细节和上下文。
学术+商业双管齐下,国产AI走向成熟
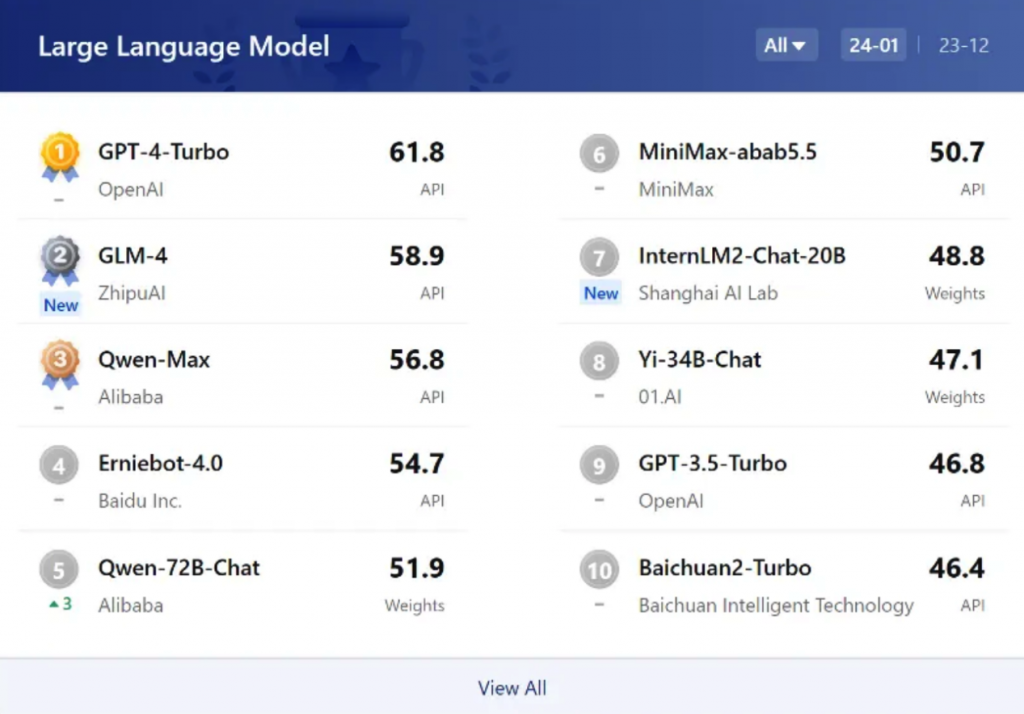
中国大模型技术的快速发展,也让越来越多的国产大模型登上了世界权威评测的榜单。不仅是SuperBench评测,在OpenCompass2.0公布的2023年度大模型公开评测榜单中,也能够看到智谱GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0位列榜单前列,中美在人工智能领域的技术差距正在以超乎想象的速度拉近。
大模型的技术革命,不仅为人工智能赋予了“涌现”的能力,也为行业逐渐“涌现”出了各种机会,我国人工智能企业也在积累中迎来爆发,全球AI发展的态势也逐渐将人工智能摆在了关键竞争高地。智谱AI CEO张鹏曾多次表示,智谱要将“实现大模型生成AI的全链路自主可控”作为企业的核心竞争力。
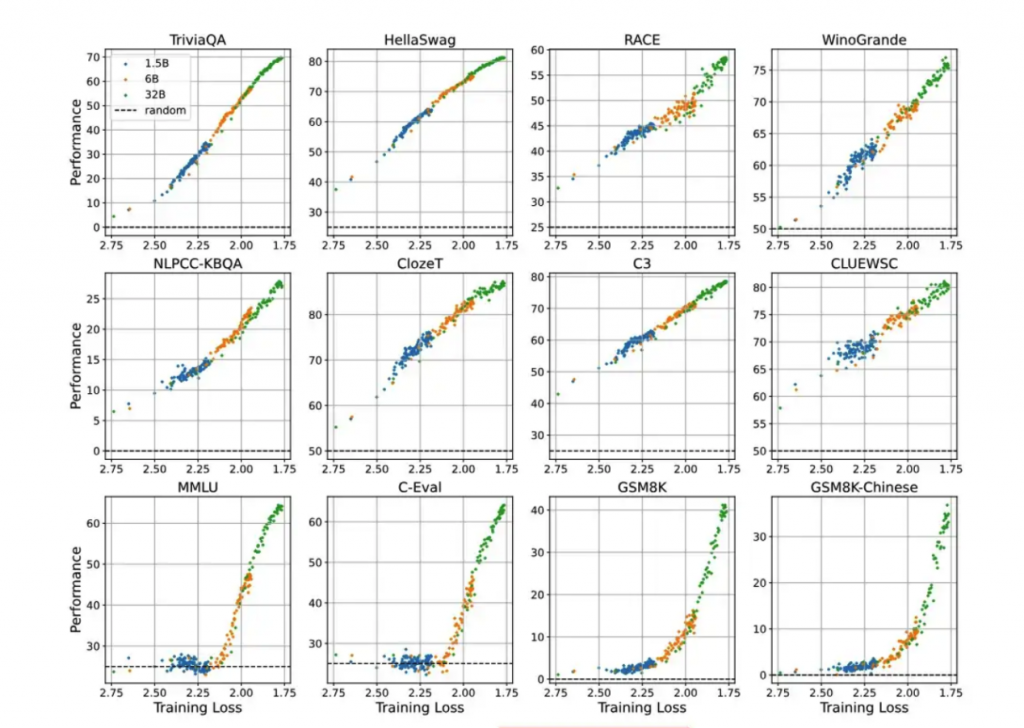
在学术领域,中国大模型从业者在多项研究领域都走在行业前沿。例如在近期研究中,智谱团队证明了依靠更好的预训练质量,在更小模型上也能实现了更优的模型能力,颠覆了大模型行业“大力出奇迹”的思维定势。
此外,智谱AI带来了提升大模型与人类偏好一致性的强化学习系统——ChatGLM-RLHF框架,该框架由三个主要部分组成:数据收集与处理、奖励模型训练和策略模型训练。
首先,ChatGLM-RLHF通过从SFT模型生成的两个输出中选择一个更优的响应,完成数据的收集。再利用收集到的偏好数据来训练一个奖励模型,预测最符合用户偏好的回答。最后,使用奖励模型来指导模型的优化过程,通过最大化累积奖励来提升模型的表现。
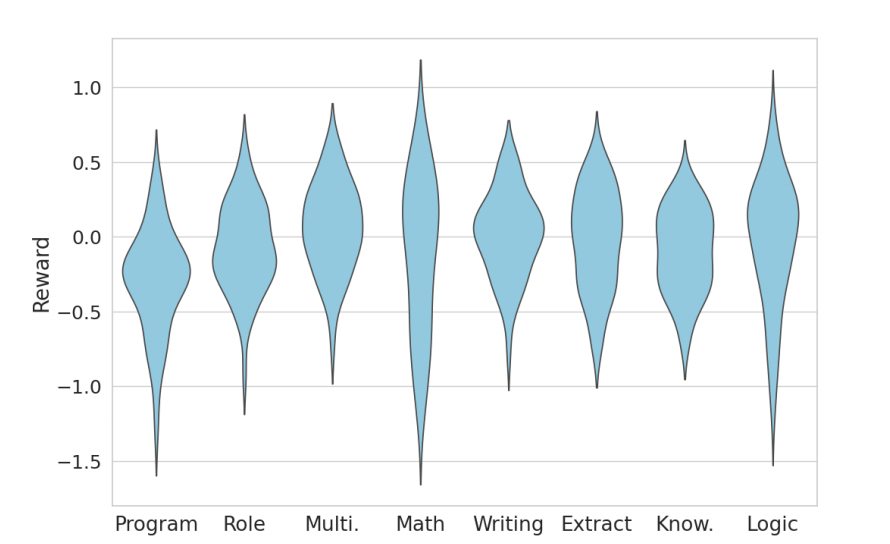
在三个步骤的协同工作下,大模型能够更加“通人性”,更清晰地理解人类的喜好与需求,才能够更好地为用户提供服务
在众多权威评测中的亮眼表现以及在研发领域的累累硕果,见证着中国大模型企业的创新能力得到了国际认可。国内丰富的应用场景,也让大模型产业落地走在世界前列,无论是智慧城市、智能制造,还是医疗健康、金融科技等领域都在探索利用大模型技术实现降本增效。
以智谱AI为例,在商业领域前已经有超过2000家生态合作伙伴,1000家规模化应用和200 家深度共创客户。智谱清言作为一款免费的AI工具,为大众用户提供了一个接触和体验生成式AI的窗口。
未来,随着技术的日益成熟和应用领域的不断拓宽,我们满怀信心地期待,我国大模型行业将不断砥砺前行,在探索新的技术高峰的同时,享受到人工智能技术带来的便捷与美好。




