大数据与数据挖掘的相对绝对关系
数据不是信息,而是有待理解的原材料。但有一件事是确定无疑的:当NSA为了从其海量数据中“挖掘”出信息,耗资数十亿改善新手段时,它正受益于陡然降落的计算机存储和处理价格。
麻省理工学院的研究者约翰·古塔格(John Guttag)和柯林·斯塔尔兹(Collin Stultz)创建了一个计算机模型来分析之心脏病病患丢弃的心电图数据。他们利用数据挖掘和机器学习在海量的数据中筛选,发现心电图中出现三类异常者——一年内死于第二次心脏病发作的机率比未出现者高一至二倍。这种新方法能够识别出更多的,无法通过现有的风险筛查被探查出的高危病人。
数据挖掘这一术语含义广泛,指代一些通常由软件实现的机制,目的是从巨量数据中提取出信息。数据挖掘往往又被称作算法。
威斯康星探索学院主任大卫·克拉考尔(David Krakauer)说,数据量的增长——以及提取信息的能力的提高——也在影响着科学。“计算机的处理能力和存储空间在呈指数增长,成本却在指数级下降。从这个意义上来讲,很多科学研究如今也遵循摩尔定律。”
在 2005年,一块1TB的硬盘价格大约为1,000美元,“但是现在一枚不到100美元的U盘就有那么大的容量。”研究智能演化的克拉考尔说。现下关于大数据和数据挖掘的讨论“之所以发生是因为我们正处于惊天动地的变革当中,而且我们正以前所未有的方式感知它。”克拉劳尔说。
随着我们通过电话、信用卡、电子商务、互联网和电子邮件留下更多的生活痕迹,大数据不断增长的商业影响也在如下时刻表现出来:
◆你搜索一条飞往塔斯卡鲁萨的航班,然后便看到网站上出现了塔斯卡鲁萨的宾馆打折信息
◆你观赏的电影采用了以几十万G数据为基础的计算机图形图像技术
◆你光顾的商店在对顾客行为进行数据挖掘的基础上获取最大化的利润
◆用算法预测人们购票需求,航空公司以不可预知的方式调整价格
◆智能手机的应用识别到你的位置,因此你收到附近餐厅的服务信息
互联网上的火眼金睛
当医学家忙于应对癌症、细菌和病毒之时,互联网上的政治言论已呈燎原之势。整个推特圈上每天要出现超过 5 亿条推文,其政治影响力与日俱增,使廉洁政府团体面临着数据挖掘技术带来的巨大挑战。
印第安纳大学 Truthy (意:可信)项目的目标是从这种每日的信息泛滥中发掘出深层意义,博士后研究员埃米利奥 · 费拉拉( Emilio Ferrara )说。 “Truthy 是一种能让研究者研究推特上信息扩散的工具。通过识别关键词以及追踪在线用户的活动,我们研究正在进行的讨论。 ”
Truthy 是由印第安纳研究者菲尔 · 孟泽( Fil Menczer )和亚力桑德罗 · 弗拉米尼( Alessandro Flammini )开发的。每一天,该项目的计算机过滤多达 5 千万条推文,试图找出其中蕴含的模式。
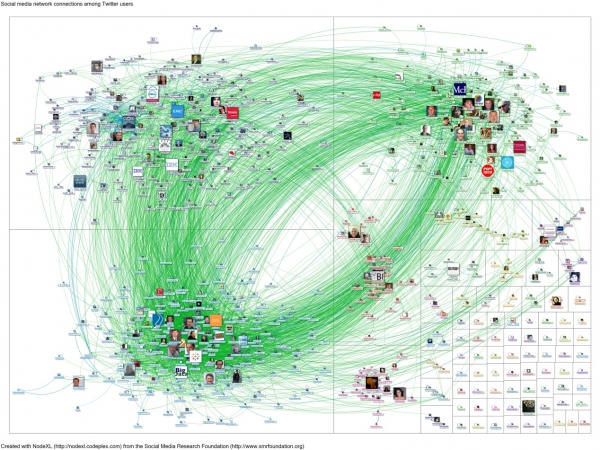
Truthy是由印第安纳研究者菲尔·孟泽(Fil Menczer)和亚力桑德罗·弗拉米尼(Alessandro Flammini)开发的。每一天,该项目的计算机过滤多达5千万条推文,试图找出其中蕴含的模式。
大数据盯着“#bigdata”(意为大数据)。这些是在推特上发布过“bigdata”的用户之间的连接,用户图标的尺寸代表了其粉丝数多寡。蓝线表示一次回复或者提及,绿线表示一个用户是另一个的粉丝。
一个主要的兴趣点是“水军”,费拉拉说:协调一致的造势运动本应来自草根阶层,但实际上是由“热衷传播虚假信息的个人和组织”发起的。
2012年美国大选期间,一系列推文声称共和党总统候选人米特·罗姆尼(Mitt Romney)在脸谱网上获得了可疑的大批粉丝。“调查者发现共和党人和民主党人皆与此事无关。”费拉拉说,“幕后另有主使。这是一次旨在令人们相信罗姆尼在买粉从而抹黑他的造势运动。”
水军的造势运动通常很有特点,费拉拉说。“要想发起一场大规模的抹黑运动,你需要很多推特账号,”包括由程序自动运行、反复发布选定信息的假账号。“我们通过分析推文的特征,能够辨别出这种自动行为。”
推文的数量年复一年地倍增,有什么能够保证线上政治的透明呢?“我们这个项目的目的是让技术掌握一点这样的信息。”费拉拉说,“找到一切是不可能的,但哪怕我们能够发现一点,也比没有强。”
随着数据及通讯价格持续下跌,新的思路和方法应运而生。
如果你想了解你家中每一件设备消耗了多少水和能量,麦克阿瑟奖获得者西瓦塔克·帕特尔 (Shwetak Patel)有个解决方案:用无线传感器识别每一台设备的唯一数字签名。帕特尔的智能算法配合外挂传感器,以低廉的成本找到耗电多的电器。位于加利福尼亚 州海沃德市的这个家庭惊讶地得知,录像机消耗了他们家11%的电力。等到处理能力一次相对较小的改变令结果出现突破性的进展,克拉考尔补充道,大数据的应用可能会经历一次“相变”。
“大数据”是一个相对的说法,不是绝对的,克拉考尔指出。“大数据可以被视作一种比率——我们能计算的数据比上我们必须计算的数据。大数据一直存在。如果你想一下收集行星位置数据的丹麦天文学家第谷布拉赫(Tycho Brahe,1546-1601),当时还没有解释行星运动的开普勒理论,因此这个比率是歪曲的。这是那个年代的大数据。”
大数据成为问题“是在技术允许我们收集和存储的数据超过了我们对系统精推细研的能力之后。”克拉考尔说。
我们好奇,当软件继续在大到无法想象的数据库上执行复杂计算,以此为基础在科学、商业和安全领域制定决策,我们是不是把过多的权力交给了机器。在我们无法觑探之处,决策在没人理解输入与输出、数据与决策之间的关系的情况下被自动做出。“这正是我所从事的领域,”克拉考尔回应道,“我的研究对象是宇宙中的智能演化,从大爆炸到大脑。我毫不怀疑你说的。”
本文来源:大数据中国 节选
本文被转载2次
首发媒体 | 转发媒体
| 转发媒体

