7条建议帮你「竞争分析」能力level up!
「竞品分析」是PM入门的必修课。
我曾在网上搜集过
一坨「竞品分析」的案例分享
,真可谓方法各异、良莠不齐。
不过若能做到以下5点,在我眼里,可算上乘了。
- 明确调研目的。
- 进而确定调研的产品list。
- 进而观察产品UI、交互、使用流程、设计亮点等各个维度。
- 做异同点比较和优缺点分析,深入挖掘和思考背后原因。
- 最后结合目标,给出有具体的、可落地的结论。
但总觉得还缺点什么。
昨夜辗转无眠,终于想通,原来是
传统方法有三个缺陷
:
- 快照而非动态。只能看到当前状态,很难直观看到 历史演变过程 。
- 表象而非规律。只看到功能,无法看到其 数据表现 。
- 局部而非全面。只看到产品表现, 用户声音 少能听到。
(滚粗,能不能说人话了~!)
咳咳,我是想说,搞不清楚下面的问题常常让我们崩溃:
"XXX每天大概新发表多少个帖子?"
"XXX的市场占有率大概是多少?"
"XXX什么时候更新到这个版本的?"
“XXX怎么赚钱的?大概收入是多少?”
"XXX这个功能看起来很cool,用户真的喜欢吗?"
.......
这些问题怎么破?我有7条建议看你知道几个:
1.让id告诉你
操作难度:★★☆☆☆
数据准确度:★★★★☆
原理:很多网站直接会用【数据库id】用作【页面元素id】,我们直接拿到一段时间的【页面元素】差值,就可以大致评估出每天新增的内容数量。
举个例子:豆瓣小组每天发表的话题数
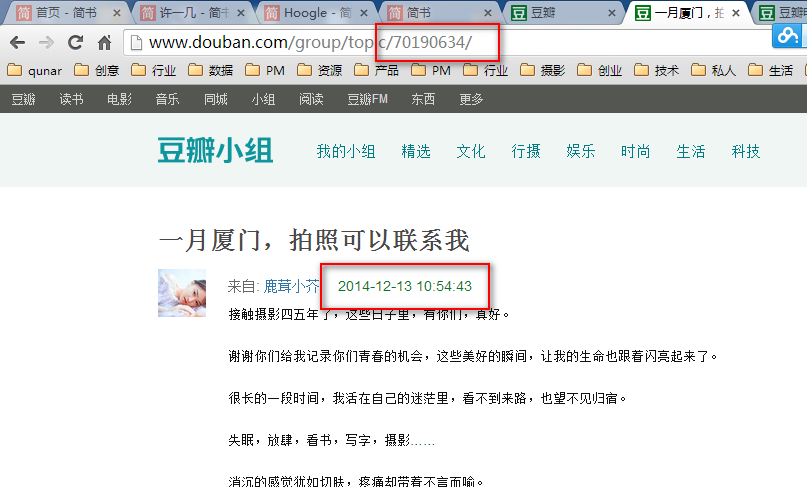
先检查:发现id=70190631~70190634的发表时间分别为2014-12-13 10:54:33~2014-12-13 10:54:43这10秒钟,且时间依次累加,验证成功。
于是我们只需抽两个样本:
- id达到70110000时,是在2014-12-11 13:12:15。
- id达到70194473时,是在2014-12-13 13:10:00。
48小时,id增长了84473,平均每天发表的新话题数量42236,问题解决。
当然这是一个大致数量,包含了删除、私密话题等各种情况。
2. 利用搜索引擎
操作难度:★★★☆☆
数据准确度:★★★☆☆
原理:搜索引擎通常会抓取网站多数页面。我们只需分析url和页面规律,利用几个搜索语法,就能获得一些数据结论。
搜索引擎语法:site,inurl,intitle,-,“”,具体用法自行百度之。
挑战:如何分析网站URL、网页Title和页面内容特点
【举个例子】
老板紧急召唤:
30分钟,帮我看下携程无报价酒店大概比例?
我擦泪~~
写程序来不及啊!
人工统计不现实啊,得搞到下个世纪!!
别急,收起你心中的万匹草泥马,搜索引擎可以给你答案。
【解决思路】
从百度拿到「无报价的酒店页数」和「酒店总页数」,做比即可。
(酒店详情页,不包含list页)
我们先观察携程酒店详情页的URL:hotels.ctrip.com/hotel/513153.html
因此:
第一次尝试搜索:【site:hotels.ctrip.com】
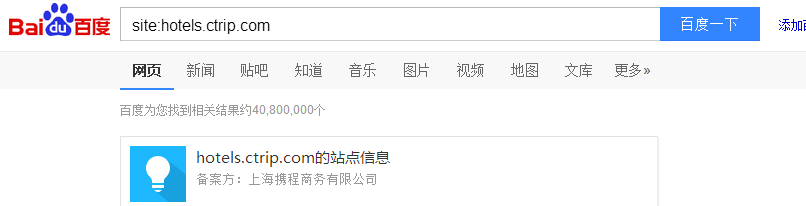
我们把全部酒店域下的页面都搜出来了,于是添加URL规则试试:
第二次尝试搜索:【site:hotels.ctrip.com inurl:/hotel/ 】

结果量还是太大了,点击几个结果,发现搜到了很多list页数据。
于是查看detail页源码,发现和list页相比,页面标题有明显特征:

于是第三次尝试搜索:【site:hotels.ctrip.com inurl:/hotel/ intitle:联系电话\位置地址 】
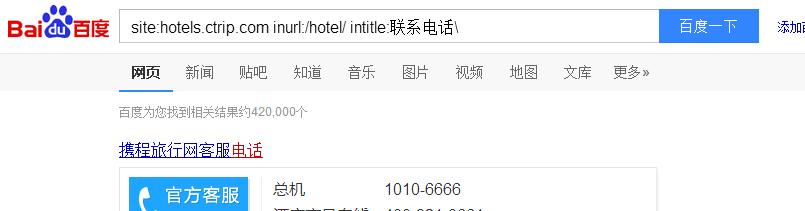
搜到了42万结果,大致量级符合,cool!
下一步,找到一个无报价酒店页面观察,发现页面有特征:
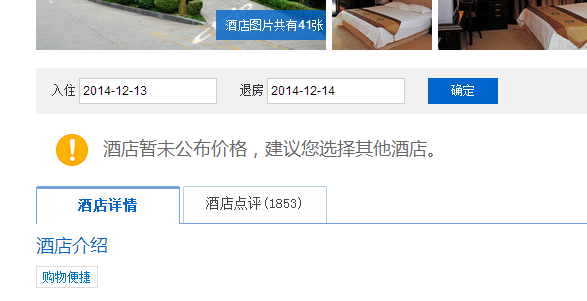
于是最终拿到无报价酒店数的检索条件:
【”建议您选择其他酒店“ site:hotels.ctrip.com inurl:/hotel/ intitle:联系电话\位置地址】
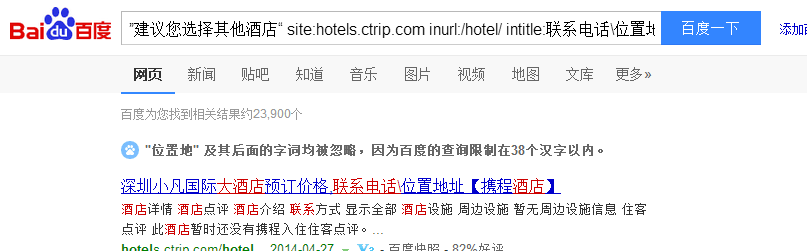
(找到2.3万条结果,数量做比。任务圆满完成!2333~~)
3. 互联网档案馆
操作难度:★☆☆☆☆
数据准确度:★★★★★
原理:这是一个网站档案馆,会定期爬取各个网站的快照,并打上版本号存起来,以备全球用户查询。
地址: http://archive.org/
(不稳定,偶尔需翻墙)
这才是一个神奇的网站好吗!
搜下Google试试,我们可以看到Google首页的改版演化:

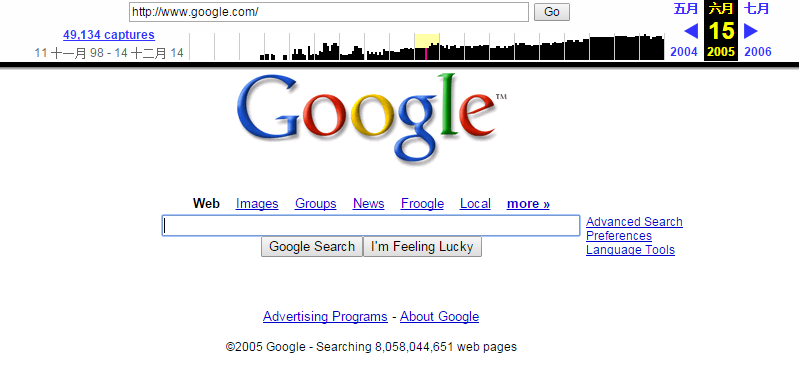
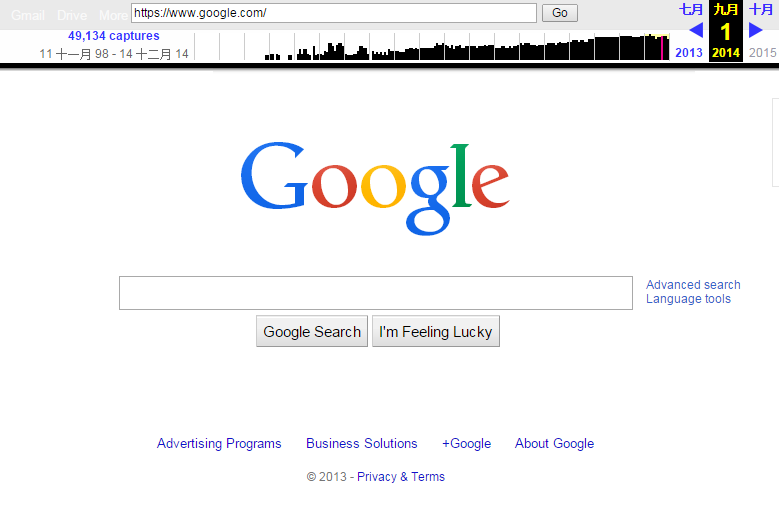
说两个真实的栗子。
有一次
我们发现,艺龙页面上展示的点评数远远低于我们的判断,纠结良久,最后还是档案馆给了答案:这是两年前的一次大改版就写死在了页面上,一直没有更新。
还有一次
,做产品方案时需要参考上上个版本,那个版本是在我加入公司一年以前上线的,wiki和文档库里翻遍了都没有。终于还是从档案馆里翻到了当初方案的原貌。
总结一下,档案馆解决问题场景,如:
- 想了解网站UI的成长过程(由傻B到牛B的进化,看看 04年的京东 ,乐呵下)
- 想了解网站的历次版本迭代时间点。
- 早期版本的PM把PRD和UI稿弄丢了,这个网站帮你备份。
-
听听竞品用户声音
操作难度:★★☆☆☆
数据准确度:★☆☆☆☆
严格来说,我只是想分享一个不太常用到的观察思路。
总结成一句话:帮竞品分析用户反馈。
具体渠道:微博、应用商店、知道、知乎、贴吧。
具体来说,比如:
- 从应用商店的下载量和评论量,可以横向比较用户规模。
- 在知道/贴吧,大家的困扰、吐槽能让你了解用户对竞品的态度。
- 【分享到微博】的功能,常常会加##,搜一下你能看到很多,如:
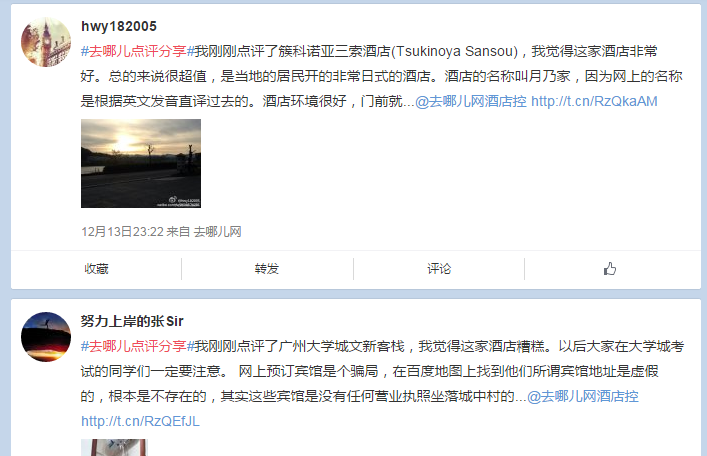
5.写程序抓取/统计
操作难度:★★★★★
数据准确度:★★★★☆
简单说,就是用程序把竞品页面抓过来分析
抛开成本高不提, 这是竞品数据调研最理想的方法。
这类例子就非常多了:
- 一个朋友为解知乎用户的称赞数分布,几乎爬走了所有用户profile页。
- 我曾写过一个小程序,用来监控每天豆瓣的新topic数量和最热topic。
- 很多公司会监控竞品的关键指标,每天会精确到个位数地抓取和分析。
PS。这里面有一个技术难点:
需要解决“防抓取的问题”
成熟产品通常都会设置放抓取策略,不会轻易让你把大量页面抓走分析。
(作为PM,我给个技术方案,可参考不负责(笑):多次尝试、分析对方的防抓策略,然后有针对性的设置抓取频率,如果不能满足要求,考虑使用代理(eg.goagent))
6. 看公司财报
操作难度:★☆☆☆☆
数据准确度:★★★★★
适用情况:市场份额、用户规模、核心指标数据、收入情况
这是最可信的方法,当然通常只对上市公司有效。
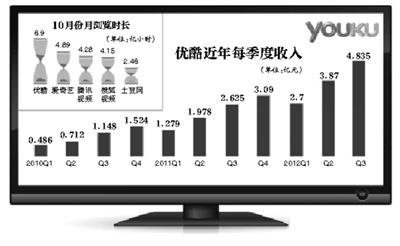
这个不多解释,如果因为英文poor/不懂名词而看不懂财报
市面上有大量的财报分析文章,也可供参考和相互印证。
7. 问“奸细”:)
操作难度:不定,看人脉和运气
数据准确度:★★★★☆
适用情况:一次性,而非日常监控
这是一张最给力的底牌。
每当山穷水尽,一筹莫展时,总有一个声音冒出来:
“哦对了,XX不是去了那个公司/团队吗?直接问下不得了!”
然后一条微信,瞬间解决了所有难题。
每每此时,我都会感叹:
“同事跳到对手公司,看来也不一定是坏事。(笑)”

本文由许一几投稿, 载请注明来源于人人都是产品经理并附带本文链接
本文被转载1次
首发媒体 | 转发媒体
| 转发媒体