分享:线下业务数据体系搭建
编辑导语:数据分析有助于帮助我们获知业务效果及其他效果反馈,然而当下企业在线下业务当中,不少数据都有所流失,这就要求企业寻找更有效的数据体系搭建方式。本篇文章里,作者就线下业务的数据体系搭建做了总结,不妨来看一下。

前言
在实际的业务环境下,能够完全通过线上留存的数据搭建业务数据体系的情况主要还是以互联网公司为主,有大量的线下传统公司,是没办法通过线上数据的积累完成业务数据体系的搭建的,在这种情况就得通过不同类型的数据来源去获取业务中可能涉及的数据,设计合理的业务数据体系,完成线下业务数据的监控、维护和分析。

01
如果是从数据逻辑出发,第一步应当是监控数据,就是我们平常一直说的看数据。
但在实际业务中,尤其是线下业务中,其实有大量业务没有留存业务发生时点的数据,在业务的各个转化节点的数据也很难及时获取留存,大量的数据丢失。如果需要从监控数据开始,其实相对来说难度会很大,甚至有很多业务数据没有合适的方式被留存下来,在日后的数据分析搭建中也无法起到作用。
所以,我更建议从业务的发展方向上入手,尽量细化业务流程,明确各个业务流程对部门业务到底有什么影响,核心业务流程是什么,优先从核心业务流程入手,根据业务流程的步骤完成业务数据的监控和留存。
举个例子,如果对保险行业熟悉的朋友会知道,保险业所有公司都有“培训”这个项目,甚至在保险业里面“组训”、“督训”都是很吃香的岗位,能够在短期内积累大量经验,往公司中高层走更快速,这个岗位主要的业务范畴就是“培训”,培训外勤、培训新人、培训合作渠道等等。
怎么评价培训效果呢?依靠外勤人员的销售量、销售额对培训效果进行评价,剩余对培训效果的评价来自学员和更高级的培训讲师的打分。
其实可以从上述模式看出,对线下培训这种业务模式的评判,对培训岗工作人员能力、业绩的评估其实很难通过以上评分模式进行量化,更不用说实际培训效果的追踪。
还是同个例子,如果要想追踪实际培训对销售业务产生的效果和影响,要关注几个模块:

从培训业务的目标出发,如果想从更细化的角度去关注培训,会有以下几个业务方会想要关注的点:
- 培训的效果怎么样,怎么评估培训效果;
- 培训效果和培训人员的关系;
- 什么课程的培训效果好;
- 不同类型的培训课程能够影响销售人员的销售业绩;
- 不同类型的培训课程影响销售业绩的时间长短。
所有这些关注点的数据,均无法从线上获取,也很难追踪(这还是仅仅线下业务在实际业务细化关注项提出后的一部分数据的数据量化和追踪,如果要实现业务数据的获取,就需要公司严格要求外勤人员反馈该类型数据,可想而知如果是沟通渠道获取业务数据,就会显得更为困难)。
在这种情况下,线下业务数据体系建立就需要建立严格且标准的业务数据体系,这需要与每一步工作流程相互契合,这个流程有点类似于线上数据埋点的过程,只不过因为业务不在线上,没法在线上完成数据积累。
当然,线下数据埋点和线上数据埋点完全不一样,因为缺乏线上工具的记录能力,大量数据记录只能依靠人力完成,如果想要通过人力完成这类数据登记汇总,就需要使用统一的工具,使用统一的数据字段、数据格式,这需要做到数据流转记录的标准化留存。
以上问题的解决方法除了需要依靠人力对数据进行核准清洗外,建议最好是按照统一的字段建立本地数据库。
熟悉EXCEL或者WPS EXCEL的朋友会了解,这两个软件的处理能力随着数据量的上涨会十分受限,如果是行数超过百万级的话,是无法在EXCEL中操作的,会出现数据丢失。
同样的,如果数据量在20万以上,使用IF系的函数将会加重性能负担,非常容易崩溃,尤其是当出现过去的某一原始主键重复出现的时候,利用EXCEL技巧实现等价FOR循环会变得更难。
这个时候我们会更倾向于在本地建立MySQL数据库,可以利用MySQLworkbench或者NAVICAT对本地数据库进行处理, 利用本地数据库的字典表的字段完成线下交互数据EXCEL/CSV表格表头字段的统一,在简单获取了线下汇总回来的数据之后利用update函数完成数据更新,形成本地数据库。
作为参考,这个是阿里天池某次比赛的测试集数据源,测试数据集的文件不超过100M,模型处理后的预测集也就100M-150M,这部分数据条数约为20W,如果是数据条数在70-80W左右的线下数据,文件大小会达到超过200M,如果还需要清洗、维护这些业务数据,仅仅依靠EXCEL是完全不现实的。
既然要建立数据库,线下数据的维护同步时间就极为关键,线下数据的收集端口需要明确,不同部门、不同渠道之间进行数据交互的人员要固定,交互时间要固定,否则就容易出现数据交互不清晰,导致最后在不同的统计节点的数据无法统一,不断会出现数据重复更新的情况,不利于数据检测监控。
这要数据监控和数据维护以及数据统计在同个周期内完成,同时还要确定所有数据的每一次更新都是以数据覆盖的逻辑,即每一次新增更新的数据范围和内容必须是完全新增的数据。
举个例子,新增的数据版本为C,数据库内现有数据版本为B,更早的版本为C,上传的时候就不允许C版本的数据中含有A版本的数据内容,这样会导致数据的转化顺序存在混乱,涉及时间续流的数据就出现问题。
02
以上是线下数据体系中数据监控和数据维护的部分,接下来我们聊聊线下数据分析体系的搭建.
和线上数据类似,所有的线下“埋点”的数据回收都是服务于实际业务数据分析的,可以这么说,我们要的不是数据,而是数据告诉我们的事实,以及我们根据历史事实能推导出的合理预测,从逻辑方法论上面,就是归纳—演绎。
想进行数据分析,首要的是需要对历史和现阶段的事实情况进行归纳统计,这就需要加入线下“埋点”的数据进行统计分析,即,先深入了解知道自己的情况。
深入了解自己的情况可以从以下几个方向去深入思考:
- 我们部门/公司实现盈利、绩效评估的核心指标是什么,什么指标是业绩反馈的核心指标(从律师来说是胜诉率,从医生来说是治愈率,蒙牛公司是销售额,德勤是咨询服务的收益)。
- 当前部门/公司处在什么样的阶段(在不同阶段下的核心指标是不完全一致的,像快要破产的公司的核心指标是清算)。
- 和核心指标有直接关联的业务主要有哪些,这些业务的工作流程分别是什么。
- 历史核心指标和当前核心指标出现了什么变化,这些变化主要源于什么工作流程上的改变?
了解了这些自身情况之后,还需要深入了解,那些和你在做一样事情的人,在面对同类型业务核心指标的人,他们的工作情况、业务完成情况、实际业务流程转化,和他们历史的情况。
当然,所有的这些外部事实情况都可能不准确,这就需要从业人员实际判断这些外部信息的准确性和可用性。
这些事实怎么得出?通过数据的形式。
这些事实怎么校验?通过数据的形式。
举个例子,还是以我们上说的保险公司培训部门的例子。
假设当前保险公司的业务正常,市场正常,政策上国家没有对保险市场提出什么更为严苛的政策要求,在这些条件下:
- 核心指标:保险专项培训对实际保险销售业务的影响大小;
- 当前部门所处阶段:所有工作正常展开,外部竞争环境处在正常竞争环境下,无不良竞争情况;
- 和核心指标有较强相关度的工作业务流程:根据外勤需求主动拆分培训需求-进行培训项目筛选-制定培训流程-设计培训课程-执行培训-跟进培训结果;
- 历史变动情况:历史同类型课程的培训量几乎保持一致,培训频率也保持一致。
这些是相对比较概念化的事实,这时候就需要利用数据把所有的事实细化描述清晰,且所有的数据都需要和工作流程相关联。
同时,所有的业务数据分析都需要建立“时间”的概念,我们可以画一个时间轴来看这个业务流程:
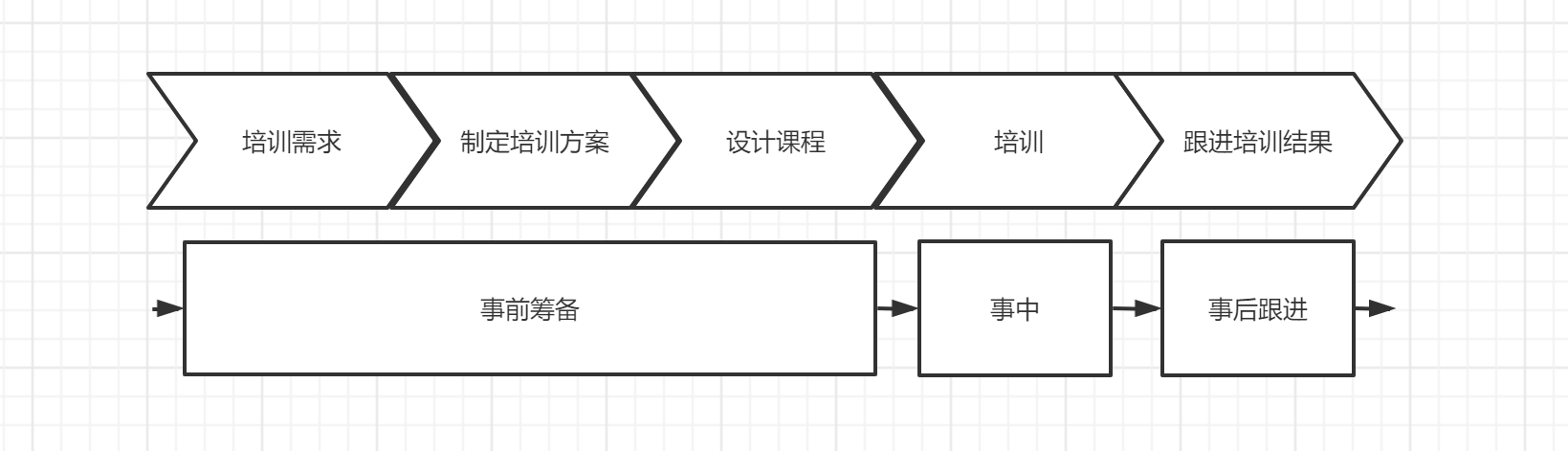
每个业务流程下其实都需要一定时间完成当前工作状态的信息收集,数据本身就具有时间的特性,如果是金融公司、金融部门,还会对数据的时间序列有更严格的要求,因此,数据本身就需要打上所属时间的标签。
在业务流程中,记录每个事件发生时间点的数据,留存这些时间标签下的数据,完成基础数据源的汇总。
在分析中可以将分析划分为几层,可以先按“事前—事中—事后”的顺序留存各个事件发生时点的数据,从中尽量明确有规律性的节点,例如:
- 从收到不同规模的培训需求到实际举办培训需要多长时间?
- 培训完到培训成果检验需要间隔多久时间?
这些时点的数据收集可以帮助你深入了解业务流程,在日后做到各类自动化有很大程度上的帮助,这就是业务体系初步建立之后再进行优化的工作了。
在关注了业务的核心指标后,找到能够对核心指标产生影响的因素,将这些因素拆分成“事前—事中—事后”的形式,设定一定的主键完成数据特质化的积累。
以电商为例,电商可以以“订单号—用户ID”的形式,如果是在保险培训的角度下可以参训外勤人员ID作为主键,当然,不同的业务模式会有不同类型的主键,涉及的后续的一些数据内容也不一致。
还是以保险培训为例,在培训中有大量数据是没有办法轻松进行积累的,也同样不能很明确地进行量化,这时候就要建立评分卡的制度,用于量化一部分难以直接估量的行为数据。
比方说,A讲师培训营销技巧和保险学原理课程,两门课程完全不属于同一个课程体系下,在实际外勤作业中,营销技巧所能给实际业绩的增长是短期高效的,而保险学原理课程可能在提升外勤人员金融素养方面更为突出,可能在面对高净值客户的时候能更体现优势。
这部分提升并不会很直接的在实际销售业绩上有明确的体现,这时候就会需要对实际的培训效果进行分类归纳,建立不同评分评级制度。
类似于量化投资,这些数据都会需要和业务核心指标建模拟合判断,根据历史经验,最好是建立相关的多元线性回归模型,机器学习模型虽然在预测方面更具有优势。
但是实际可解释性并没有那么强,在实际业务总结反馈的时候并不能明确的找出问题所在,所以在预测分析的角度还是更推荐从线性回归的角度配合相关性进行分析。
希望分享的这些给现在还在线下摸索业务数据体系搭建的朋友们一些启发。
作者:Logan_RRRC;公众号: Logan的运营学习日记
本文由 @Logan_RRRC 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议