如何用深度学习模型,解决情感分析难题?
本文以情感分析为分享主题,并分析了情感属性分析的挑战以及如何利用深度学习模型解决此类问题。

Meltwater通过机器学习提供情感分析已超过10年。第一批模型于2009年部署了英语和德语版本。今天,Meltwater in-house支持16种语言的模型。本博客文章讨论了如何使用深度学习和反馈循环向全球3万多个客户大规模提供情感分析。
什么是情感分析?
情感分析是自然语言处理(NLP)中的一个领域,涉及从文本中识别和分类主观意见[1]。情感分析的范围从检测情感(例如愤怒,幸福,恐惧)到讽刺和意图(例如投诉,反馈,意见)。情感分析以其最简单的形式为一段文本分配属性(例如,正面,负面,中立)。
让我们看几个例子:
Acme 到目前为止,是我遇到过的最糟糕的公司。
这句话显然表达了负面意见。情感由“最糟糕的公司”(情感短语 the sentiment phrase)承载,并指向“ Acme”(情感目标 the sentiment target)。
明天,Acme和NewCo将发布其最新收入数据
在这种情况下,我们只有关于“ Acme”和“ NewCo”的事实陈述。语句是中性的。
NewCo 在过去一年的创纪录销售数字和股市飙升的支持下,它成为第一个在其平台上积累1万亿美元资产的养老金计划。
这次,我们在积极的语义环境中使用了诸如“支持”,“创纪录销售”之类的短语,指的是“ NewCo” 。
Meltwater通过机器学习提供情感分析已超过10年。第一批模型于2009年部署了英语和德语版本。Meltwater现在拥有16种语言的in-house模型:阿拉伯语,中文,丹麦语,荷兰语,芬兰语,法语,印地语,意大利语,日语,韩语,挪威语,葡萄牙语,西班牙语和瑞典语。
我们的大多数客户都通过媒体监控仪表板(图1)或报告来分析情感趋势。较大的客户可以通过Fairhair.ai数据平台以丰富文档的形式访问我们的数据。

图1:Meltwater Media Intelligence媒体监测仪表板。
该产品的一个重要特征是,用户能够覆写(override)算法分配的情感值。覆写的情感属性被索引为Meltwater的Elasticsearch集群中同一文档的不同“版本”,在构建仪表盘和报告时,为客户提供了他们的情感的个性化视图(图2)。

图2:Meltwater的媒体情报内容流中的“情感属性”覆写下拉列表。
每个月,我们的客户都会覆写大约200,000个文档中的情感值。每天有6,500个文档!那么,为什么情感很难如此正确呢?
情感属性分析的挑战
人类语言的某些细微差别是挑战性的来源之一。举一些例子:
处理否定语义:
贵公司情况如何?还不错!我对最新的财务状况并不非常满意 ……
我们在这里有三个句子,第一个是中性的,第二个是肯定的,但包含“错”,通常在否定的上下文中使用,第三个是否定的,但包含“非常满意”。
讽刺语义:用这样的句子
今天又下雨了…… fun times!
尽管表达了“fun times”,但该文本可能是讽刺的,并表达了负面情感。
比较性语义:
我喜欢新的Acme手机,它们比NewCo的手机好得多。
这里的“爱”和“好得多”等表达带有积极的情感,但是,对于“ NewCo”来说,评价却是负面的。
取决于读者角度的语境:
阿克梅警察局今天逮捕了8名涉嫌袭击和抢劫的人员。该团伙几个月来一直在恐吓社区。
除单词的含义外,以上所有内容都需要理解上下文。
一个必须解决的实际问题是精度和速度之间的权衡。Meltwater每天对大约4.5亿个文档进行情感分析,范围从推文(平均长度约30个字符)到新闻和博客帖子(长度可达到600-700,000个字符)。每个文档必须在20毫秒内处理。必须保证速度!
传统的机器学习方法(如朴素贝叶斯(naïve Bayes),逻辑回归和支持向量机(SVM))因具有良好的可扩展性而被广泛用于大规模的情感分析。现已证明深度学习 (DL)方法在各种NLP任务(包括情感分析)上都可以实现更高的准确性,但是,它们通常较慢,并且训练和操作成本更高[2]。
“旧”方法:贝叶斯情感
到目前为止,Meltwater一直在使用多元朴素贝叶斯(naïve Bayes)情感分类器。分类器需要一段文本并将其转换为一个拥有特征值的矢量 (f1, f2,…, fn)。
然后,分类器计算最可能的情感正负属性S j,即正,负或中性,前提是我们观察到文本中的某些特征值。这通常写为条件概率语句:
p(Sj | f1, f2,…, fn)
通过找到最大化下面的公式的S j,从而获得概率最大的情感正负属性。
log(p(Sj)+log(p(fi | Sj))
让我们将以上理论应用于我们的情感问题。p(Sj)的值是找到“本质上”具有特定正负属性的文档的概率。可以通过将大量文档集标记为正,负或中性,然后计算找到其中具有给定情感政府属性的文档的概率,来估计这些概率。理想情况下,我们应该使用所有曾经的文档,但这是不切实际的。
例如,如果语料库由以下带有标签的文档组成:
- D1: My phone is not bad (正面)
- D2: My phone is not great (负面)
- D3: My phone is good (正面)
- D4: My phone is bad (负面)
- D5: My phone is Korean (中性)
然后 p(Sj)的值是:
- p(正面)= 2/5=0.4
- p(负面)=2/5=0.4
- p(中性)=1/5=0.2
我们使用一个简单的单词袋模型来导出我们的功能。我们使用一元语法,二元语法,和三元语法。例如D 1转换为:
(My, phone, is, not, bad, My phone, phone is, is not, not bad, My phone is, phone is not, is not bad)
p(fi | Sj)的值即为在语料库中被标记为S j的文档中看到某个特征的概率。
我们可以使用柯尔莫哥洛夫对于条件概率 的定义p(fi | Sj)=p(fi∩Sj)/p(Sj),来计算其值。例如,对于特征值“bad”:
- p(bad | 正面)=p(bad ∩正面)/p(正面)=0.2/0.4=0.5
- p(bad | 负面)=p(bad ∩负面)/p(负面)=0.2/0.4=0.5
- p(bad | 中性)=p(bad ∩中性)/p(中性)=0/0.2=0
给定一个文档(例如“My tablet is good”),分类器基于文本的功能为每个情感政府属性计算出一个“得分”,例如对于“正面性”,我们得到:
log( p(POS | my, tablet, is, good, my tablet, tablet is, is good, my tablet is, tablet is good))
即为:
log( p(POS) )+log( p(my | POS) )+ … +log( p(tablet is good | POS) )= −13.6949
同样适用于“负面性”和“中性”,从而产生以下按序的得分:
- log(p(正面 | …)) = −13.6949
- log(p(中性 | …)) = −16.9250
- log(p(负面 | …)) = −18.1709
然后分类器得出的答案是:“正面性”是最有可能的情感正负属性。
朴素贝叶斯(naïve Bayes)分类器运行很快,因为所需的计算非常简单。但是,就准确性而言,此方法可以实现的功能有限,例如:
- 准确的分类依赖于代表性的数据集,即,如果训练集偏向某个情感正负属性(例如中性),我们的分类也可能产生偏向。准确性还取决于培训语料库是否足够涵盖了我们所在意的语言。
- 朴素贝叶斯(naïve Bayes)的假设基于特征的独立性,即使得出的情感正负属性排名是正确的,得出的概率也不是那么可靠[3,4]。
- 当使用朴素贝叶斯和词袋模型时,作为训练标签的颗粒度仅仅为文档,通常会导致结果不佳。
- N-gram(元) 语言模型是一种钝器。如果将自己限制为3元,我们将无法正确捕获例如“not quite as bad”这样的4元表达式。但是,增加上下文的大小会破环特征空间,从而使分类器变慢,但不一定结果更好。
Meltwater的NLP(自然语言处理)团队的任务是改善所有支持语言的情感分析。由于训练新模型是一项复杂且昂贵的工作,因此团队首先研究了利用我们现有的技术堆栈来改善情感分析的快速方法。
改进1:句子级训练和分类
我们进行的第一个改变,是训练贝叶斯模型的方式。现在,我们不是在整个文档的粒度上进行训练和分类,而是在句子级别进行训练和分类。以下是一些优点:
- 与整个文档相比,将标签分配给单个句子(或上下文中的表达式)要容易得多,因此我们可以众包培训集的标签。
- 多年来,学术研究产生了可免费获得的带标签的数据集,用于情感分析评估。其中大多数处于句子级别,因此我们可以将其纳入我们的培训集中。
- 我们可以将句子级情感与命名实体和关键短语提取一起使用以提供实体级情感(Entity-level sentimate,ELS)。
然后,我们决定通过堆叠分类器“挑选”有意义句子的情感,将句子级别的情感汇总为文档级别的情感,以产生整个文档的情感。
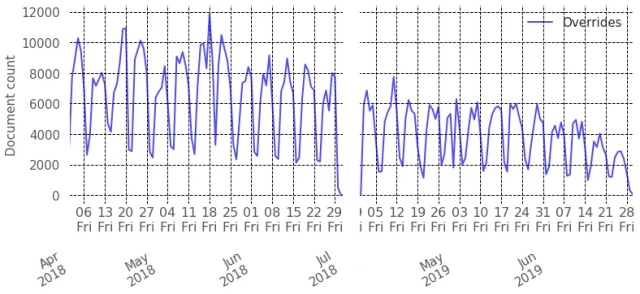
图3:在2018年第二季度(左)和2019年第二季度(右)中记录的情感属性覆写-所有语言。
这些简单的更改对减少客户每月做出的情感属性覆写次数产生了巨大影响。特别是,在16种受支持的语言中,新闻文档的情感属性覆写平均减少了58%。
该分析涉及7,193个客户产生的约4.5亿个新闻文档和4.2百万个覆写项。图3显示了2018第二季度(文档级预测)和2019第二季度(句子级预测+汇总)进行的覆写数量之间的比较。
改进2:新的深度学习模型
同时,Meltwater的NLP团队一直在努力改进我们的技术堆栈,以分析两种主要语言(即英语和中文)的情感,涵盖Meltwater处理的每日内容的约40%。
我们尝试了多种技术,例如卷积神经网络(CNN),递归神经网络(RNN)和长短内存网络(LSTM),目的是在准确性,速度和成本之间找到良好的折衷方案。
由于在准确性,速度和运行成本之间进行了很好的权衡,我们决定选择基于CNN的解决方案。CNN主要用于计算机视觉,但事实证明,它们对NLP的表现也非常好。我们的解决方案使用Tensor Flow,NumPy(具有MKL优化),GenSim和EKPhrasis在Python中实现,以支持哈希/现金标签,表情符号和表情符号。
体系架构
简化的架构如图4所示。它包括一个嵌入(输入)层,然后是单个卷积层,然后是最大池化层和softmax层[5]。
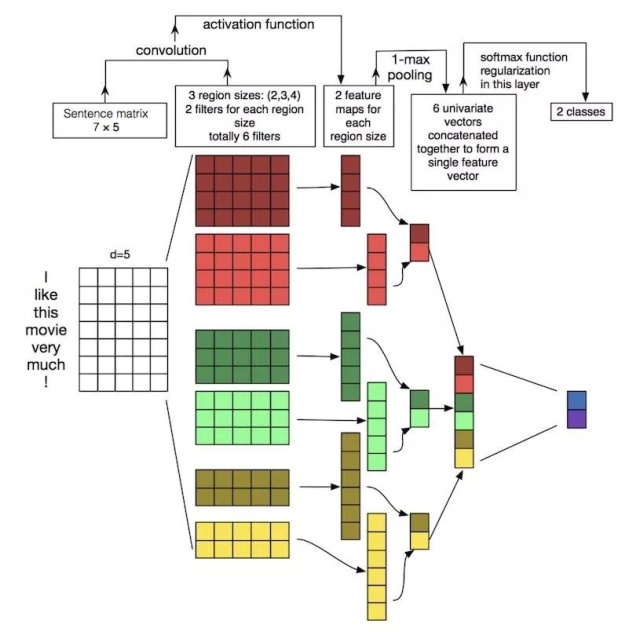
图4:简化的模型架构(来源:Zhang,Y.和Wallace,B.(2015)。卷积神经网络用于句法分类的敏感性分析(和从业人员指南)
嵌入层
我们的输入是要分类的文本。至于贝叶斯方法,我们需要根据其特征来表示文本。我们将文本嵌入为矩阵。
例如,文字“I like this movie very much! ” 表示为具有7行的矩阵,每个单词一行。列数取决于我们要表示的功能。与贝叶斯案例不同,我们不再自己设计功能。相反,我们现在使用经过预训练的第三方单词嵌入。
词嵌入可大规模捕获语义相似性。这些嵌入是可公开获得的,并由第三方机器学习专家培训的神经网络生成。对于英语,我们使用斯坦福大学的GloVe嵌入对8400亿个单词进行了训练常见抓取并使用具有300个特征的向量。我们也尝试过BERT和ElMo,但准确性/成本之间的权衡仍然支持GloVe。
对于中文,我们使用腾讯AI的嵌入,该嵌入针对200万个特征向量的800万个短语进行了训练。使用我们自己的训练数据集通过转移学习对向量进行微调。目的是确保嵌入内容考虑Meltwater的PR /营销要求。
卷积层
CNN的核心是卷积层,在其中训练人工神经元以从嵌入中提取显著特征。在我们的例子中,卷积层由英语的100个神经元和汉语的50个神经元组成。
优点再次是,我们不必尝试和设计功能,网络将学习我们需要的功能。缺点是我们可能无法再知道这些功能是什么。点击这里以了解更多的卷积层的细节,点击这里了解更多黑盒问题的阐述。
最大池化(Max Pooling)
池化的思想是在特征图中捕获最重要的局部特征,以减少维数,从而加快网络速度。
SoftMax层
合并的向量被合并为单个向量,并传递到完全连接的SoftMax层,该层将对极性进行实际分类。
数据集
对于英语,除了GloVe嵌入之外,我们还有23,000个内部标记的新闻句子和6万个社交句子,包括SemEval-2017 Task 4提供的Twitter数据集。对于中文,除腾讯AI嵌入外,数据集还包含来自新闻,社交和评论的约38,000句子。
该数据集使用Amazon的SageMaker Ground Truth通过众包进行注释。在训练之前,使用二八原则对数据集进行分层和随机排序,即,我们使用80%进行训练,使用20%进行验证。
结果
与贝叶斯方法相比,这个简单架构已经使该模型在句子级别产生了明显更好的性能(表1)。英文社交文本的收益为7%,中文(社交和新闻相结合)的收益为18%,英文新闻的收益为26%。
在文档级别进行汇总之后,与贝叶斯方法相比,我们发现英语级别的文档级别情感属性覆写数量进一步减少了48.06%,中文级别的情感属性覆写为29.24%。
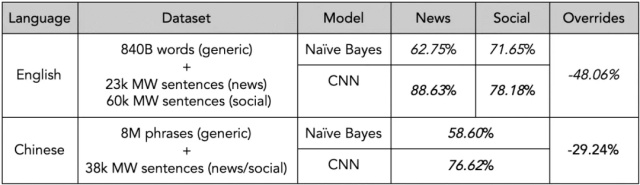
表1:CNN与朴素贝叶斯(英语和汉语)的情感准确性。
情感分析的准确性到底有多高?F〜1〜分数基本可以衡量模型得出的结果和人工注释相比的准确性。研究告诉我们,人工注释者仅在80%的情况下同意结果。
换句话说,即使假设100%准确的模型,在20%的情况下,人类仍然会不同意该模型[6]。实际上,这意味着我们的CNN模型在对单个句子进行分类时的表现几乎与人工一样好。
连续的提高
到目前为止,情感覆盖的结果从未被反馈到情感模型中。NLP团队现在已经设计了一个反馈循环,可以收集客户不同意CNN分类器的案例,以便我们可以随着时间的推移改进模型。
然后将覆盖的文档发送到Fairhair.ai Studio(图5),在此处注释者在每个级别(即实体,句子,部分(即标题,入口,正文)和文档)重新标记它们。
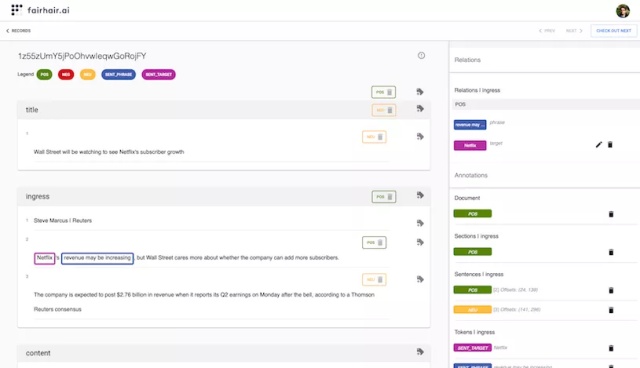
图5:Fairhair.ai Studio:Meltwater的注释工具
每个文档由不同的注释者多次注释,并由高级注释者进行最终审核。最终客户有时会参与此过程。当我们的注释人员不精通特定语言时,会将标签转移给第三方众包工具。
Meltwater是Amazon SageMaker Ground Truth的重度用户(图6)。使用众包时,我们会增加所需注释器的数量,因为它们可能不如我们内部培训的注释器准确。
图6:AWS SageMaker GT帮助Meltwater标记2690个中文文档5次
注释完成后,新的数据点将由我们的研究科学家进行审查。审查过程包括确保这些覆盖不会故意偏向我们自己的模型,或跟从需要特定模型的特定客户偏见。
如果数据是正确的,则将其添加到测试集中,即,我们不想通过将其添加到训练集中来过度拟合该数据点。我们需要该模型能够从其他数据点归纳正确答案。
我们将收集性质相似的数据,并携带必要的知识来正确分类覆盖的文档。例如,如果发现分类错误发生在讨论金融产品的文档中,那么我们将从Elasticsearch集群中收集金融类文档。
综上所述
我们对所有语言改变了训练和应用贝叶斯情感模型的方式,这使新闻文档上的文档级情感属性覆写次数平均减少了58%。
现在,我们支持所有16种语言的句子级和实体级情感。对我们而言,实体可以是个有自己名称的实体,例如“福特”,也可以是关键短语,例如“客户服务”。
我们针对英语和汉语部署了深度学习情感模型。他们的句子准确性在英语和汉语中分别为83%和76%。他们进一步将新闻文档的文档级别腹泻率降低了48.06%(英语)和29%(中文)。
新模型考虑了#标签,例如#love,表情符号和表情图示。
我们有一个反馈环来不断改善我们的情感模型。
关于作者
- Stanley Jose Komban博士是Meltwater的高级研究科学家
- Raghavendra Prasad Narayan是Meltwater的高级研究科学家
- Giorgio Orsi博士是Meltwater的首席科学家兼(NLP)工程总监
参考文献
[1] Bing Liu. Sentiment Analysis: mining sentiments, opinions, and emotions. Cambridge University Press, 2015.
[2] Daniel Justus, John Brennan, Stephen Bonner, Andrew Stephen McGough. Predicting the Computational Cost of Deep Learning Models. IEEE Intl Conf. on Big Data. 2018.
[3] Irina Rish. An empirical study of the naive Bayes classifier. IJCAI Work. on Empirical Methods in AI. 2001.
[4] Alexandru Niculescu-Mizil, Rich Caruana. Predicting good probabilities with supervised learning. Intl Conference on Machine Learning. 2005.
[5] Ye Zhang, Byron Wallace. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. Intl Joint Conf. on Natural Language Processing. 2015.
[6] Kevin Roebuck. Sentiment Analysis: High-impact Strategies – What You Need to Know: Definitions, Adoptions, Impact, Benefits, Maturity, Vendors. 2012.
本文由 @Meltwater 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自@Unsplash, 基于CC0协议