一文读懂最全KANO模型的理论与实践
编辑导语:KANO 模型是东京理工大学教授狩野纪昭(Noriaki Kano)发明的对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。对于产品经理来说,掌握KANO模型也很重要,接下来,本文作者就为我们总结了最全的KANO模型的理论与实践。

距离上一次语音交互文章已经好久了,一直被朋友催更,6月七月发生了一些事情,慢慢才调整自己的心态。
久等了,一直拖,后面将会勤快些,多分享一些比较系统、详细的文章,也感谢所有人的帮助与学习。

1. KANO模型的作用
KANO模型是之前学习和工作中使用的时候觉得特别有用的,这篇文章就是由浅入深、由概念说到使用方法,和大家分享最落地、成本最低的一个交互方法论。
你是不是经常遇到过这样的场景:运营说先做这个XX功能;产品说先做XXX这个功能;这个开发说时间不够,只能做其中一个,要么放在下一个版本。
各方有各方的需求和利益点,我们应该怎么去平衡呢?
某一个功能,在大范围上它到底存不存在,并不是你说它存在就存在的。
功能如果要上的话,我们也不是一个版本就上完,一定要有一个先后顺序——这个时候就用到KANO模型。怎么样去辨别需求的真伪,以及确定是真需求以后怎么样去做量化的优先级排序。
很明显了KANO模型的作用就是:怎么样去辨别需求的真伪,以及确定是真需求以后怎么样去做量化的优先级排序。

2. KANO模型的概念起始
你可能听过KANO模型,只是简单的知道这个是个什么东西,我们这次和大家分享他最基础的由来和概念,只有了解了概念和理论,你才会从根本去理解他,和别人分享的时候也会更加有理有据。
2.1 双因素理论
我们就先花一点时间把它概念来源说清楚。
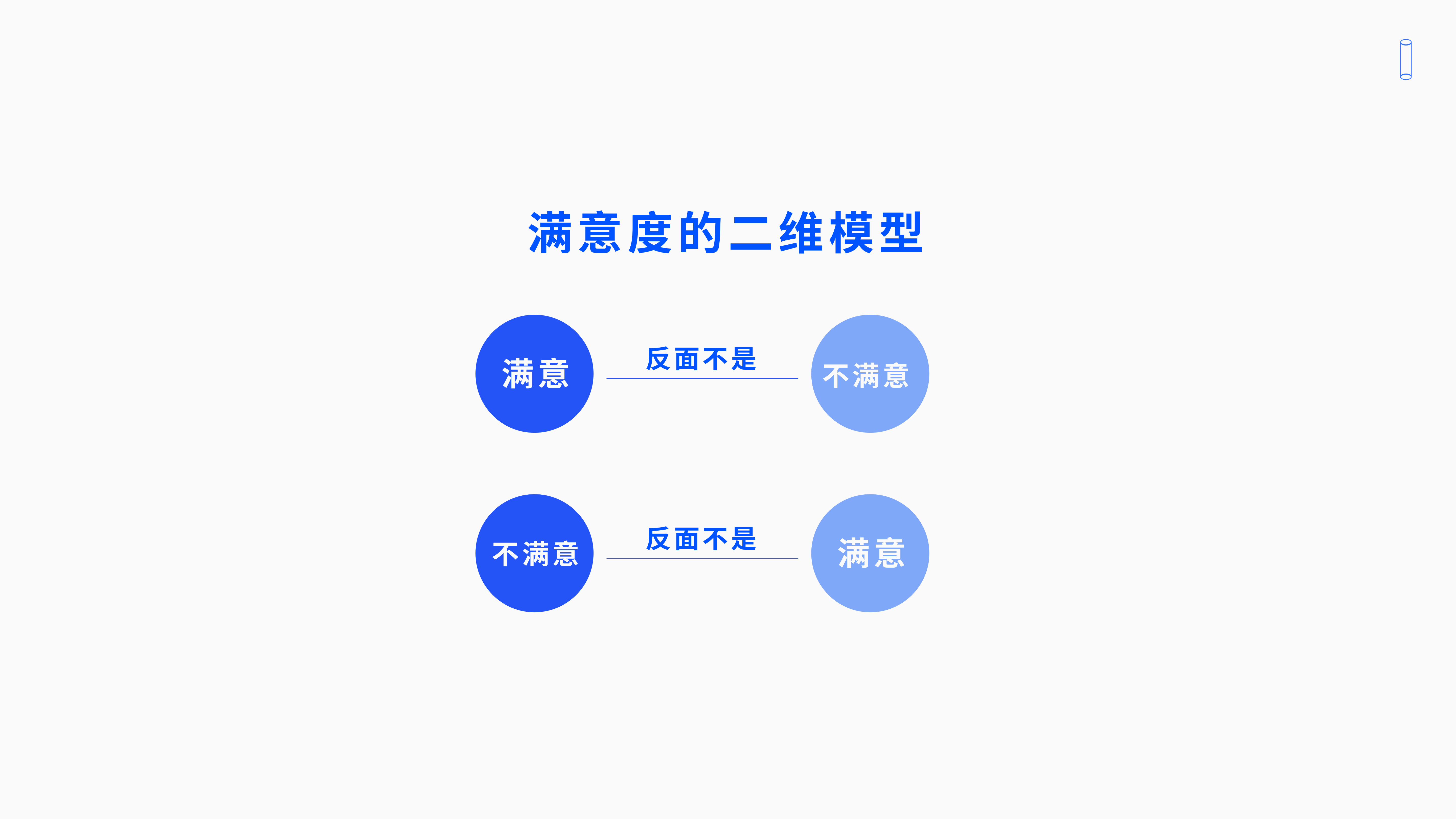
在大家传统的观念里面,我们大家会认为用户满意反面是用户不满意 。但是有一位美国的心理学家——赫茨伯格,他在研究企业员工的满意度的时候提出了双因素理论。
一般我们认为满意的反面是不满意,不满意的反面是满意。但是他认为,满意的反面不是不满意;他们不是连续体,二者是可以分开的。也说他们满意和不满意,不是二选一的关系。
因此满意的反面是没有不满意。
举个例子:如果我把令员工满意的一些条件因素去掉,员工充其量就变成了没有满意,他不一定会变成不满意。同样的,我把人不满意的因素去掉,也不一定会直接导致员工不满意,最多只是他没有不满意——这就是叫双因素理论。
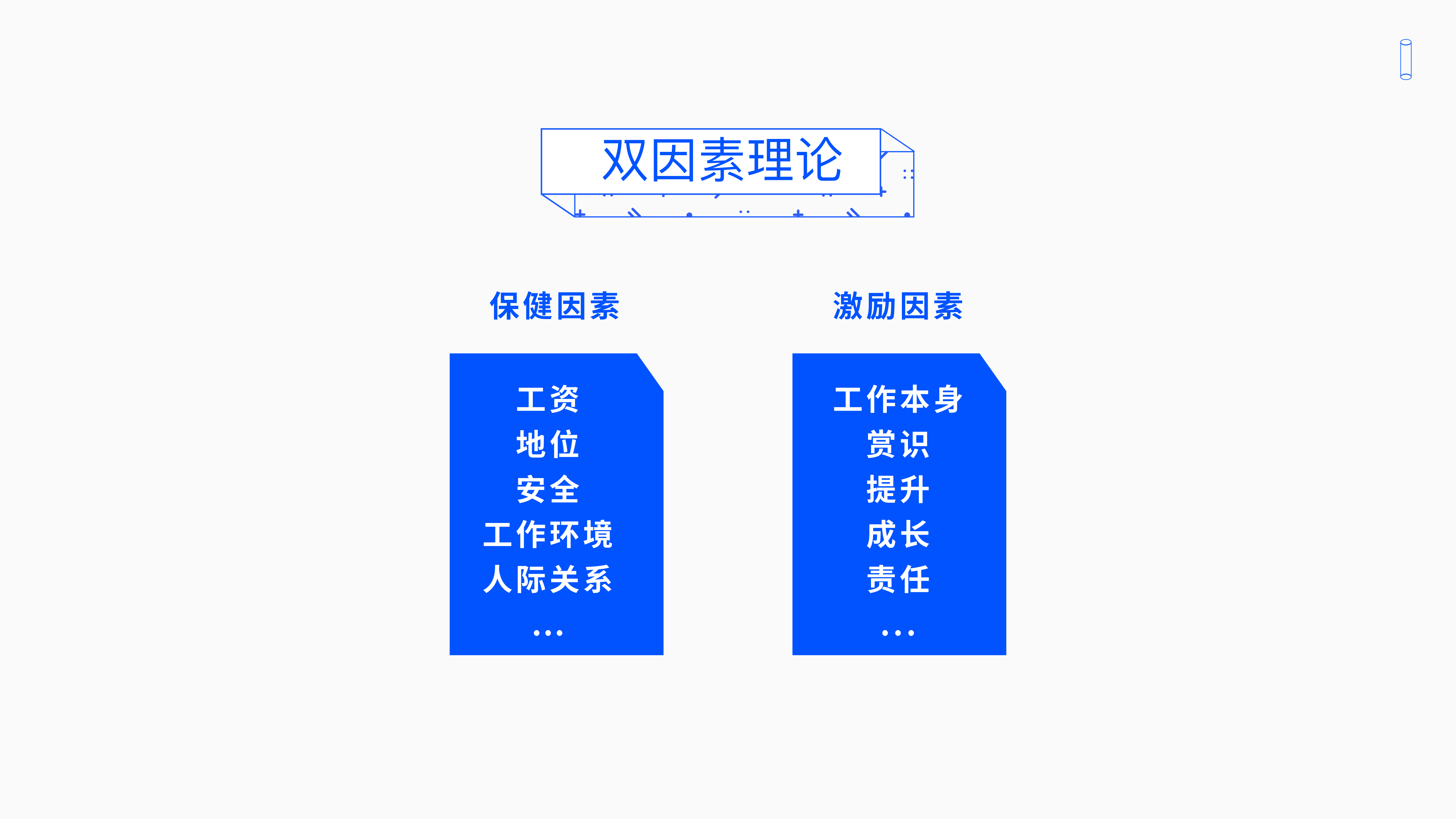
赫茨伯格他采访了两百多位美国工商企业的一些工程师,询问他们工作的满意度。研究发现,日常工作当中,员工的满意因素分为两种:一种的是叫激励因素;另外一种称为保健因素。
2.1.1 激励因素
激励因素的意思是,用户满意的工作本身给你带来的成就感,认可度和责任。
比方说你的设计稿上线以后,用户都来评价说,特别高大上特别喜欢,从此以后就爱上了这款产品了。这种是源自于对你工作本身的成就认可,发自内心的开心。
激励因素和钱没关系,和升职加薪没关系,来自于对你精神上的奖励或者老板对你的责任心的认可,同事的关爱——这种叫做激励因素。
2.1.2 保健因素
第二种因素叫做保健因素,公司政策福利好不好,薪水好不好,工作环境如何种就叫做保健因素。
发现当具备精神上的激励因素的时候,会增加员工的满意度。但是当没有激励因素,或者缺乏激励因素的时候,员工不会不满意,因为有钱拿你还是可以接受
同样,当我们会发现,当具备保健因素的时候,并不会提高用户的员工的满意度。我发你工资并不会提高员工的满意度,因为他觉得是应该的。
但是一旦缺乏保健因素了,你说我断了你的薪水了,员工一定会不满意,直接给你告到劳动仲裁去。
2.2 双因素理论小结
双因素理论的核心是激励因素,发自内心的认可责任,激励因素才能够给人们带来满意度的提升。而那种准时发工资的保健因素,只能够消除人们的不满意,刚刚具备的时候,员工并不会满意。
我们会发现,令人满意的因素即使被去掉,并不一定会导致用户的不满意;同样如果让人感到不满意的因素被去掉,也并不一定会让用户就满意了。
那么,满意度的二维模型告诉大家的是:满意度并不是正反面的,是很多灰色的地带和空间。满意的反义词是没有满意,不满意的反义词是没有不满意。
3. KANO模型需求组成
3.1 提出作者
后来,东京理工大学的教授,KANO教授学会双因素理论。
他学会了以后,他在1984年发表发表了一篇论文,篇论文里面就首次的提出了KANO模型。
因为在当时,1989年,当时的日本怎么样提高产品和企业的服务质量,都是难题。卡农教授他提出了模型,就以他的名字来命名了卡诺模型。用来分类用户需求优先级高低。
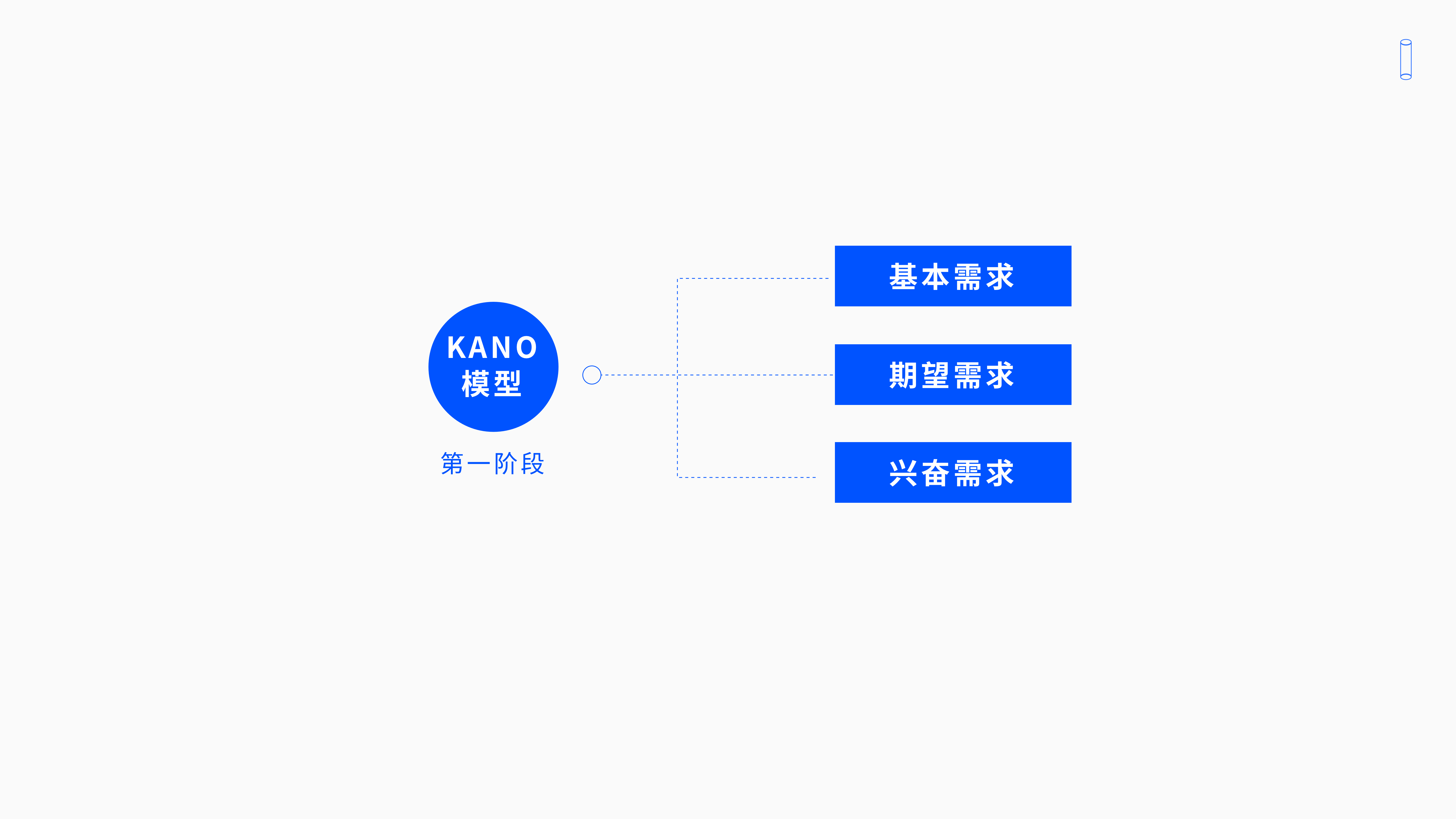
3.2 KANO模型需求的三个层次
3.2.1 第一个基本型需求
当产品不能够满足顾客的基本型需求的时候,顾客一定是很不满意的。但是当产品满足了顾客的基本型需求以后,顾客也并不会非常满意。
因为你是你该做的,做了你该做的,难道还要我表扬你吗?
会发现基本型需求和我们我们前面讲的,类似于双因素理论当中的保健因素。你给我准时发工资,难道不是你该做的吗?难道你给我准时发工资了?我就一定要很满意吗?
基本型需求和我们前面讲的保健因素相似,对于这种基本型需求,要知道即使超过了顾客的期望,顾客充其量达到满意,但是他不会对此表示表示出更多的好感。
但是你只要稍微有一点点疏忽,没有达到用户的期望,用户的满意度就会一落千丈。对用户而言,基本型需求是必须满足的,是理所当然是你该做的。
3.2.2 第二个期望型需求
期望型需求用户对期望型需求,其实没有对基本需求那样苛刻,他们并不会认为说,期望型需求是产品必须提供给他们的。但是当你产品提供给用户的期望型需求越多,用户的满意度就会越好。
3.2.3 第三个兴奋性需求
比如说之前微信聊天只能打字,打字的时候,基础上用微信多了直接发送语音的功能。
那你的语音服务做的非常好,超出用户打字的期望了,他会觉得不错, 那你后面再有更多种的表情包等等对于满足用户沟通聊天种需求更好的多样化。
你可以给用户提供一些完全出乎他意料的让用户感到惊喜 ,但是种魅力型需求往往是些无关紧要的需求,什么叫无关紧要的需求呢?
当你给用户提供种兴奋型需求的时候,其实当你不提供用户这种兴奋性需求的时候,用户无所谓。但是当你提供了呢,用户会觉得好像也不错,用户满意度也会随之有所提升。
那么这三种基本、期望和兴奋型需求,是卡农模型第一次提出的三种用户需求层次。
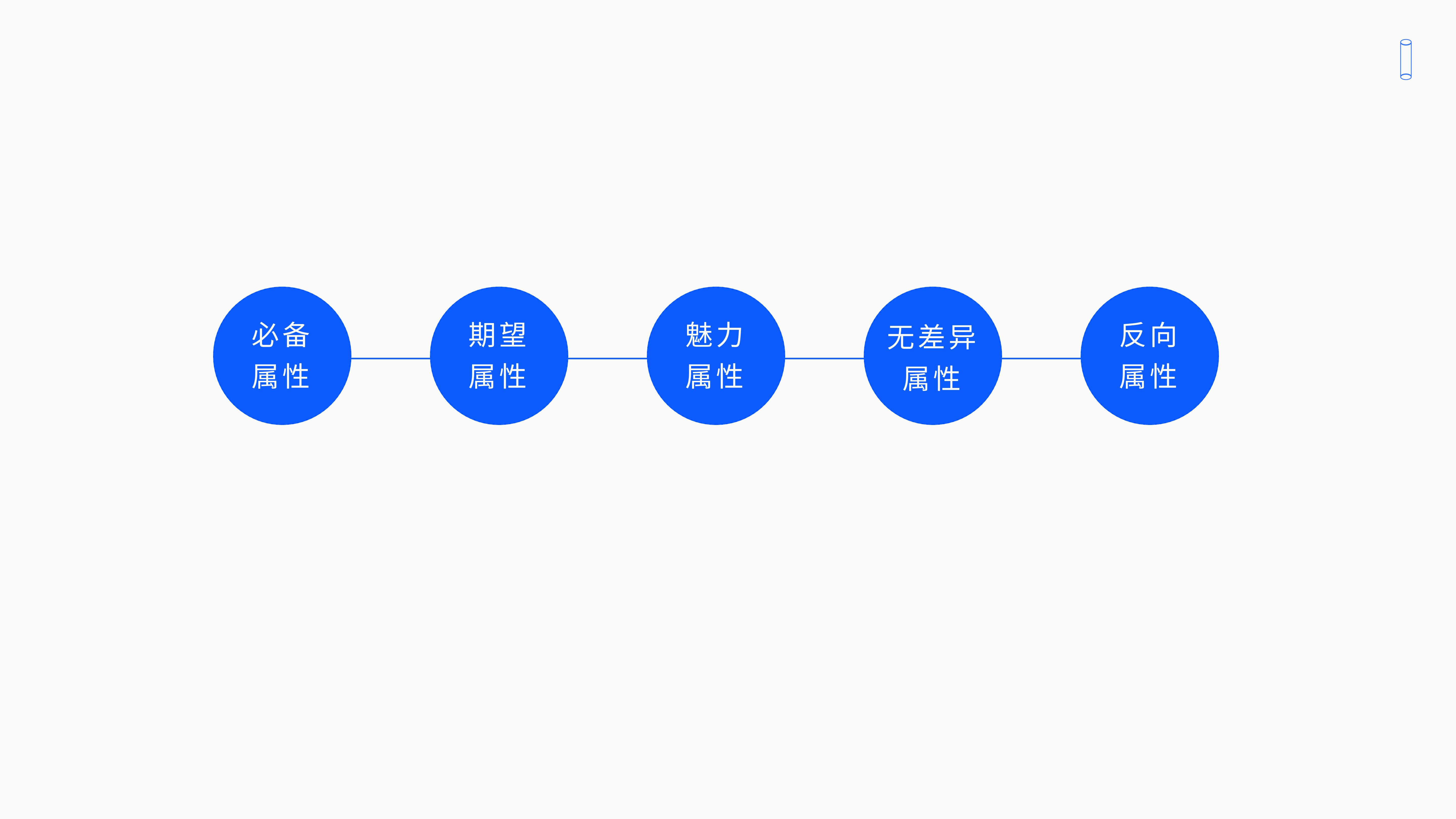
4. KANO模型五大属性
后来KANO教授又把他扩展为五大属性,也就是我们今天所看到的KANO模型的样子。
KANO教授卡诺把他做成了象限图:
4.1 如何查看图像
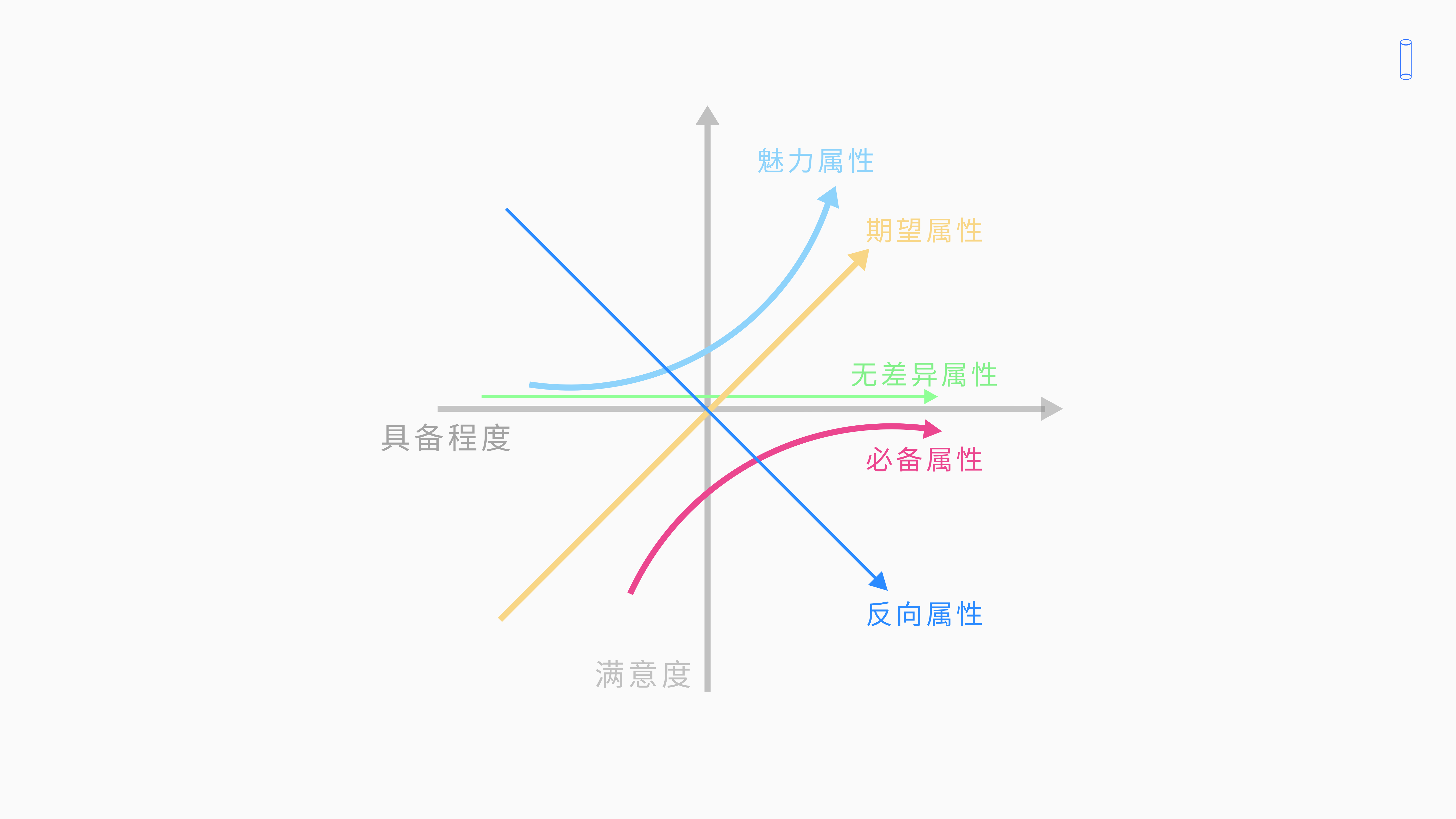
横轴是功能的具备程度,完善程度可以理解为功能。它开发的好不好,做的好不好。
纵轴是用户的满意度,他通过横纵轴,分成了四个象限来拓展了之前的卡诺模型,把三类需求分成了五类属性,变得更加详细。
我们来看一下下边这上图,再讲一下横轴,大家可以看到某功能或者是某一类需求它越像右边表示功能做得越好,具备程度越高越完善。越靠左边,表示功能做得越差。
纵坐标表示用户的满意度,纵坐标越往上表示用户越不满意,那么通过实现程度和用户满意度两个维度,我们就可以把用户需求分为五类属性。
4.2 必备属性
我们再来看必备属性,也是呈指数函数关系。
当你功能越具备、功能做得越好,用户满意度你看他虽然有所提升,但是他永远是在零度以下的 ,他不会提升特别高;你再往上优化,他也就在零度以下。
但如果你不优化呢或者优化的不好呢?
曲线就会无限的往下掉。
必备属性,当你不提供需求的时候,用户的满意度一定会大幅下降,但是如果你提供了呢?用户的满意度并不会随着你的优化显著提升。

4.3 期望属性——线性相关
我们再来看期望属性?
红色是线性相关,大家会发现是线性相关成正比的。当完成程度,功能具备程度做得越好 ,那用户的满意度就往上提升;当我做的越不好满足就下降完全是成正比的。

4.4 魅力属性——指数相关
首先我们一起来看一下魅力属性黄色的条线。
我们会发现,对于魅力属性来说,用户的满意度和需求的实现程度是相关指数函数关系;我们会发现,就算我不提供需求,我在具备程度很低的地方,哪怕我不提供需求。
你看他黄色的线最多永远接近于横轴、但是他不会超过下面。这就说明——就算我不提供种魅力属性,用户的满意度也不会降到下面;但是如果我提供这种的魅力属性越来越足够的话,他的满意度就成指数函数飞快的上升 。
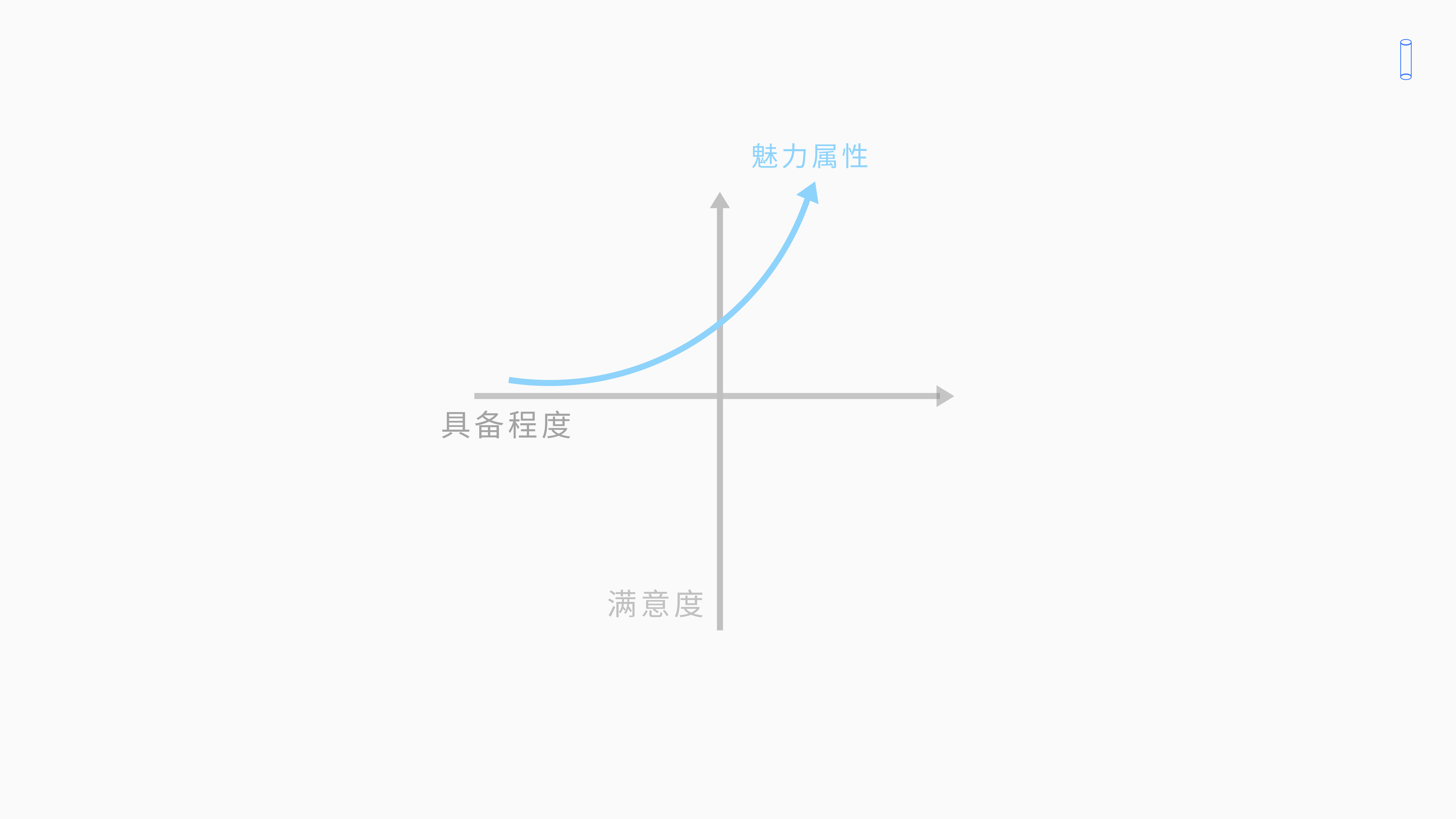
魅力型需求,如果你提供的话,他会对用户的满意度有很大提升。但如果你不提供,他最多满意度在零点吧, 他不会不满意。
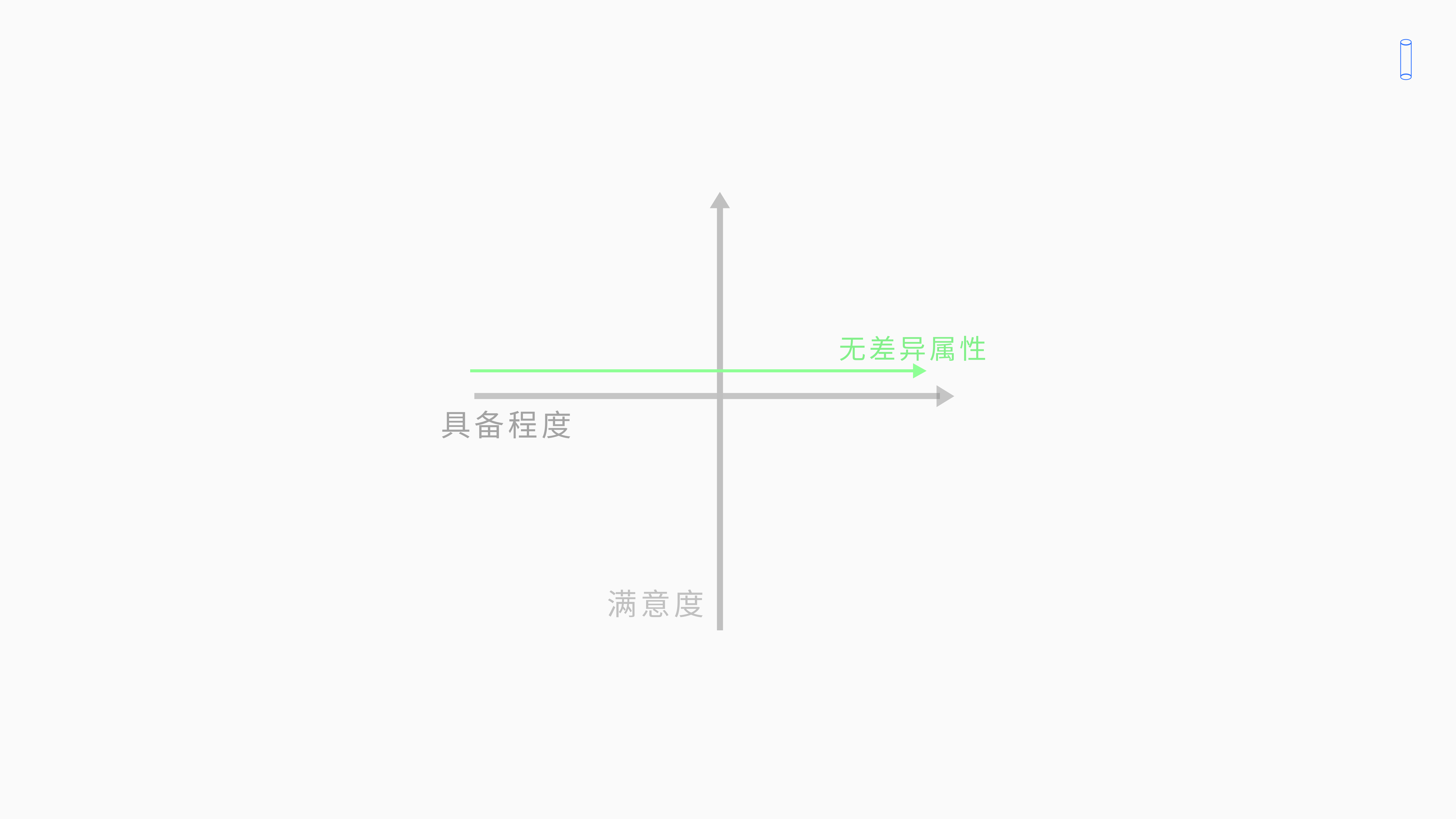
4.5 无差异属性
我可以看第三个无差异属性,无差异属性,不管你功能具备与否,用户的满意度永远停留在条线上。对于无差异属性来说,不管你做不做功能,用户的满意度都不会改变,因为用户不在意。
4.6 反向属性
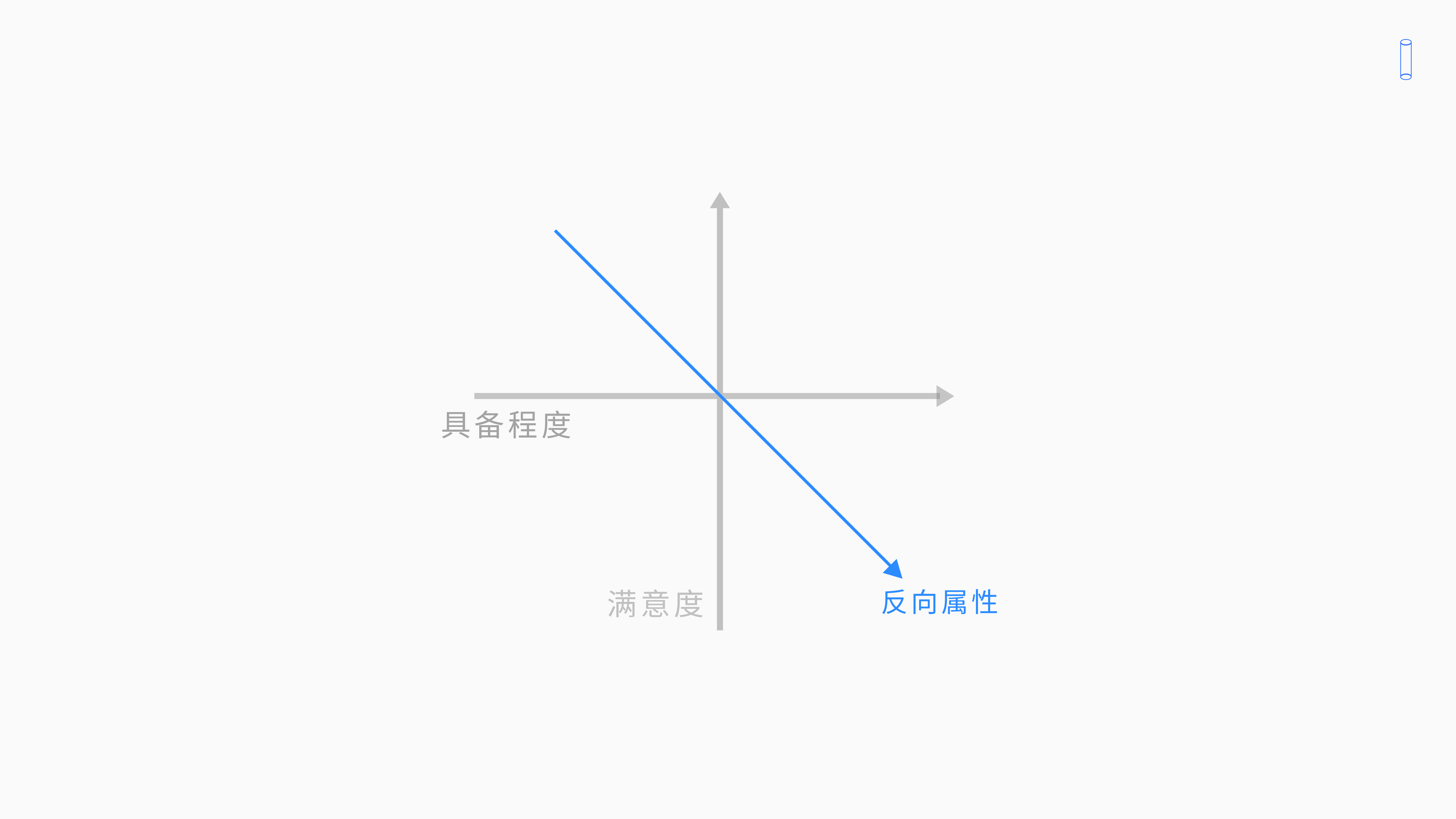
那反向属性紫色的线很奇怪功能做得越好,卖越多反而越低了。
说明用户不仅没有需求,而且你的叙述做了以后会让用户感到反感,但现在很少产品会这样去做。我们在做卡通模型的时候发现属于反向属性特点的功能是很少的,除非你的产品经理真的是个xx,要不然不太会做出反向属性的功能出来。
4.7 功能属性会随时间变化而改变
我们通过象限图来去理解五种属性。
但是和大家说明一点的是,一个功能的属性是有时间动态变化而变化的,怎么说呢?今天这个功能属于期望功能,他可能下一个月或者明年就变成了必备属性,或者其他属性。
随着时间的推移,随着产品或者是服务的提升,大家对些功能的要求会越来越高。
从前有功能,你对他的态度是有的话,我很开心,没有我也无所谓。而今天你的态度就变成了,这个XX功能肯定得有,变成了是基本的要求。
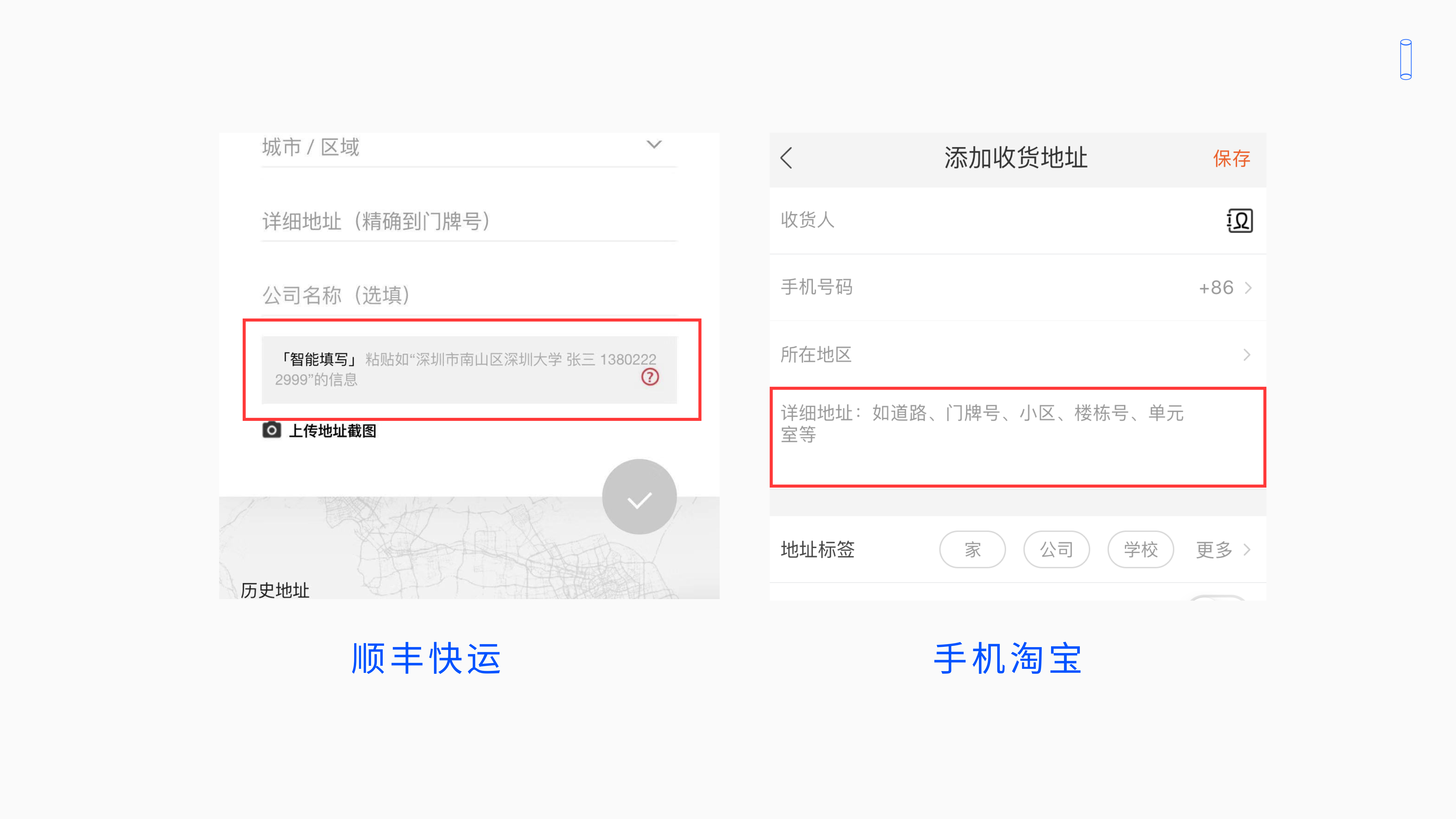
4.7.1 举个例子,快递地址智能填写功能
快递填写地址之前是没有智能填写功能的,是没办法你智能帮你识别地址、电话等一些信息的,需要每一个都填。快递地址之前可能是属于魅力属性,觉得给了会很惊喜。
可是现在有一些快递填写没有智能填写这个功能,就会觉得有那么一点不舒服,会期望有这个功能多方便。比如手机淘宝就没有这个功能,让我觉得有点小难受。
所以不是说做一次卡诺模型就搞定终身的,我们要经常过个几个月或一年,要根据市场的需求,根据竞品的竞争情况体验好坏来重新梳理一下工作的优先级。
5. 功能属性的判断方法与优先级排序
5.1 比大小
有些用户觉得他是期望属性,有些用户觉得还是魅力属性。
那我们怎么界定呢?是最简单的判断方法——比大小。
举个例子:我找十个用户来通过一些问题判断功能属于哪种属性,其中三个用户属于觉得是期望属性,七个用户觉得属于魅力属性。
7>3。最后我们就把该功能定义为它是属于魅力属性。
5.2 从功能上排优先级
我们一起来再重新的回顾一下五个属性五个功能属性。
首先,我们把公司所有的功能都进行了分类。基本都是在这个5个功能属性的类别里面的,必备属性、期望属性、魅力属性、无差异属性和反向属性。
单从在功能的优先级上面,我们的顺序就已经是确定了。首先一定要尽快满足的必备属性的功能,其次是期望属性,第三是魅力属性,第四是无差异,第五是反向属性,
那么无差异属性的话,直接不要也罢,因为你做不做用户都那样 。当然,反向属性的话肯定是不能做,做了就会引起用户的骂声,真正要关注的必备属性,期望属性和魅力属性。
5.3 必备属性的功能是优先级最高
我们再来看一下必备属性功能。
虽然我做了用户不一定会满意,但是我不做他一定会不满意,所以很要紧,必备属性的功能是优先级最高。
排名第二是期望功能:期望行属性当我做了需求,用户的满意度会提升,不做他就会下降;排名第三的是魅力属性:用户自己是想不到的,如果你不做用户满意度不会降低,但如果你做了用户满意度就会提升。
有些产品会做出来一些无差异属性也正常,但是反向属性的基本上很少见。
6. 使用场景
那我们总结一下,在日常的工作当中一般性情况下,我们会在什么时候需要使用卡诺模型呢。
举个例子:产品经理说我们会发现,根据后台数据来看,很多功能用户不怎么用,使用率特别低。
我们心里产生疑问,会不会是用户本身对些功能就没需求了,所以他不用。产品经理会觉得说,那会不会是功能的位置不太明显或者是推广力度曝光性不够。
在这个时候,那我们就可以用卡诺模型来验证一下这个功能,到底用户有没有这个需求?
根据他需求的强烈程度,我们再看看是不是要去做优化推广。
如果说需求强烈程度非常好属于必备功能,但是他就不用,那可能是推广不到位或者其他产品上的问题;但如果本身用户就没啥需求,属于无差异属性,那你何必花精力去推广优化。

7. 如何使用-具体步骤
如何通过这个KANO模型的使用和数据的转译,判定这个功能是属于那种属性,从而来安排该功能的优先级,将是我们需要了解的重点。
我们把卡诺模型的做法拆分成七个步骤,我们来一步一步的看一下。
第一步:假设我们选出了功能,选出功能要去验证一下,要去看看功能是属于哪种属性 。如果你选出了两个三个四个五个……那其实每功能的方式都是一模一样的。
我们就一个功能来说,我们需要把功能编成一道问卷,但问卷一道题目就可以了。
7.1 收集需要分析的功能,并明确定义
因为有的时候产品经理取的名字和用户的理解是不一样的。
首先我们得把定义告诉用户,我们要把功能的定义是怎么用的,功能的定义作用写出来,方便用户了解。如果当他看不懂功能的名字的时候,至少可以看下定义。
然后针对功能,问正向的问题,再问反向问题。
什么意思呢?
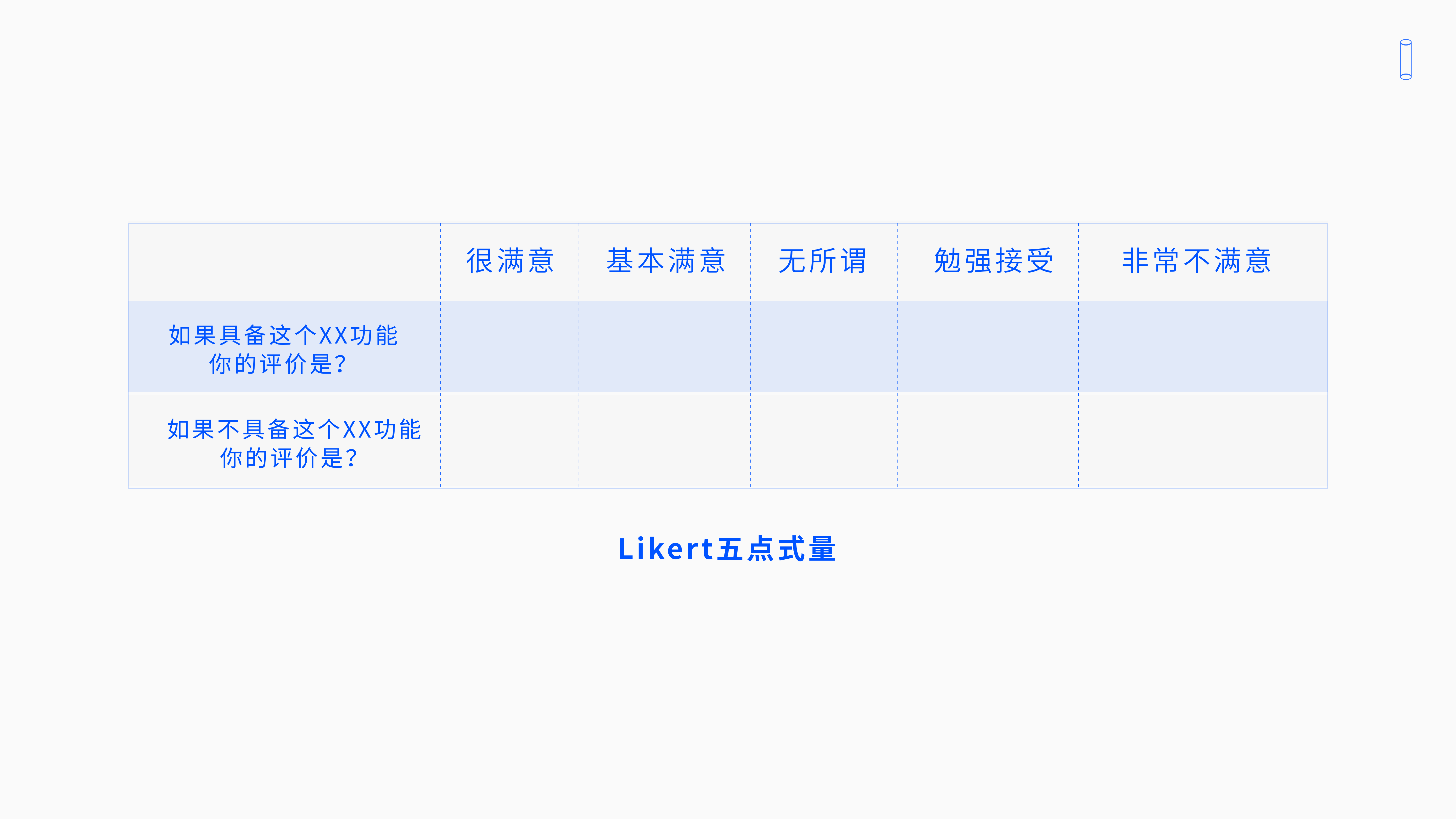
正向问的意思是:如果我们App上有这个功能,你的评价是什么?选项就是让用户进行Likert五点式量表选择 ,从我很喜欢到我很不喜欢(有五个程度);再问一道反向题:如果没有这个功能,或者是我们下架了 ?您的评价是?

7.1.1 设置问卷问题的组成
那其实每道题目,每个功能如法炮制地去设计的,每道题目有三部分组成:
- 第一部分是功能定义:要告诉给用户是什么样的功能定义?
- 第二部分给用户正向题:如果有这个功能,你的评价是?
- 第三部分给用户反向题:就假设我们没有了你会怎么做,你会怎么样,开心还是难过。
7.1.2 定义的功能有哪些
还有另外一个情况就是,如果说你想要去验证的功能属性,但是是平台上没有上线的功能,也是可是做的。比说:我们产品经理想上线十个新功能,但是到底先上哪个后上哪个?这个时候怎么办呢?
我们就把每个功能做成每一道题目,让用户去选择 ,那么这个时候功能的定义,你更加要写的非常清楚了。
因为用户没有见过功能,如果他不清楚你的定义是怎么用,那他很难去客观的评价,对有这个功能和没有这个功能的态度。
7.2 发放问卷
假设有十个功能组成的题目。问题就需要20道,因为每一个功能正反两道。这边建议是电话访谈,后面会说道是什么原因,这里不细致展开讲。
7.3 问卷编译,把回收到的问卷转换成可视化的数值(很重要)
我把答案问卷收回来了,我们要怎么样去编译呢?是非常重要的方法。
大家可以看一下,首先纵坐标,纵向每一行,具体的每个功能都设置一道正向题目和反向题目。
如果有这个功能,如果没有这个功能 ,把它列出来,每列都是用户的名字;如果你二十个用户的话,你就20列表,以此类推。

7.3.1 编译前——规则制定
那么我们拿第一个用户为例,用户在里选择对应的态度,方法的是你要把它转化为数字。可以是升序的1到5分,也可以是5到1分,顺序是不重要的。
把每选项对应成数字记录在里,最好再做编译文档前注释好,1是代表什么、5代表什么。比如:这里设定的标准是,很满意是“5”,非常不满意是“1”。

比方用户对这个功能的态度正向是1分,反向是5分,我们要把他结合起来,变成1-5。我们会发现个问题,1-5弄到最后,我都不知道是前面的数字,表示正向题目还是后面的数字表示正向。
所以我们定好一个规则:
正向的用5、4、3、2、1表示;反向用A、B、C、D、E表示。这样的话那我就可以合并单元格了,那我就可以把单个用户针对单个功能的正反两个数字合并成组合答案形式。

7.3.2 记录
这个用户对这个功能的正向评价是几分,反向评价是几分。记下来我可以。当问卷回收回来以后,建立好表格。其中要注意那用户的态度程度转化成积分,虽然很简单,但是要细心。
7.4 合并每项功能的正反向答案,统计每项功能的答案占比
我们会发现,每功能它会有两个分数,正向分对应正向题目。反向题,对应也是分数 ,我们要把正向和反向集合起来,合并成单元格。

那么功能,他就会出现5*5=5种的答案形式(因为正像提示五个选项,用户可以选择其中任何选项。反向也是五个选项,用户也可以选择其中任何选项,那么五乘以五一共是25种单组的形式)。
我们刚才说了一共有25种组合形式,我们拿出其中一道题目。他就会有25种单组的形式 ,我就画25种单元格。每道题目他的答案形式必定会落在25个单元格中的其中,图表就非常的可视化了。
以下是标准对照表。
8. KANO模型对照表

我们拿其中一道题目为例,其中一道题目的版表格。
纵向表示正向题目当功能具备的时候,用户选择的选项从很喜欢→很不喜欢。当功能不具备的时候,是从很喜欢到很不喜欢,看上图25个格子就是25种答案组合形式。
如何查看这个表格呢?
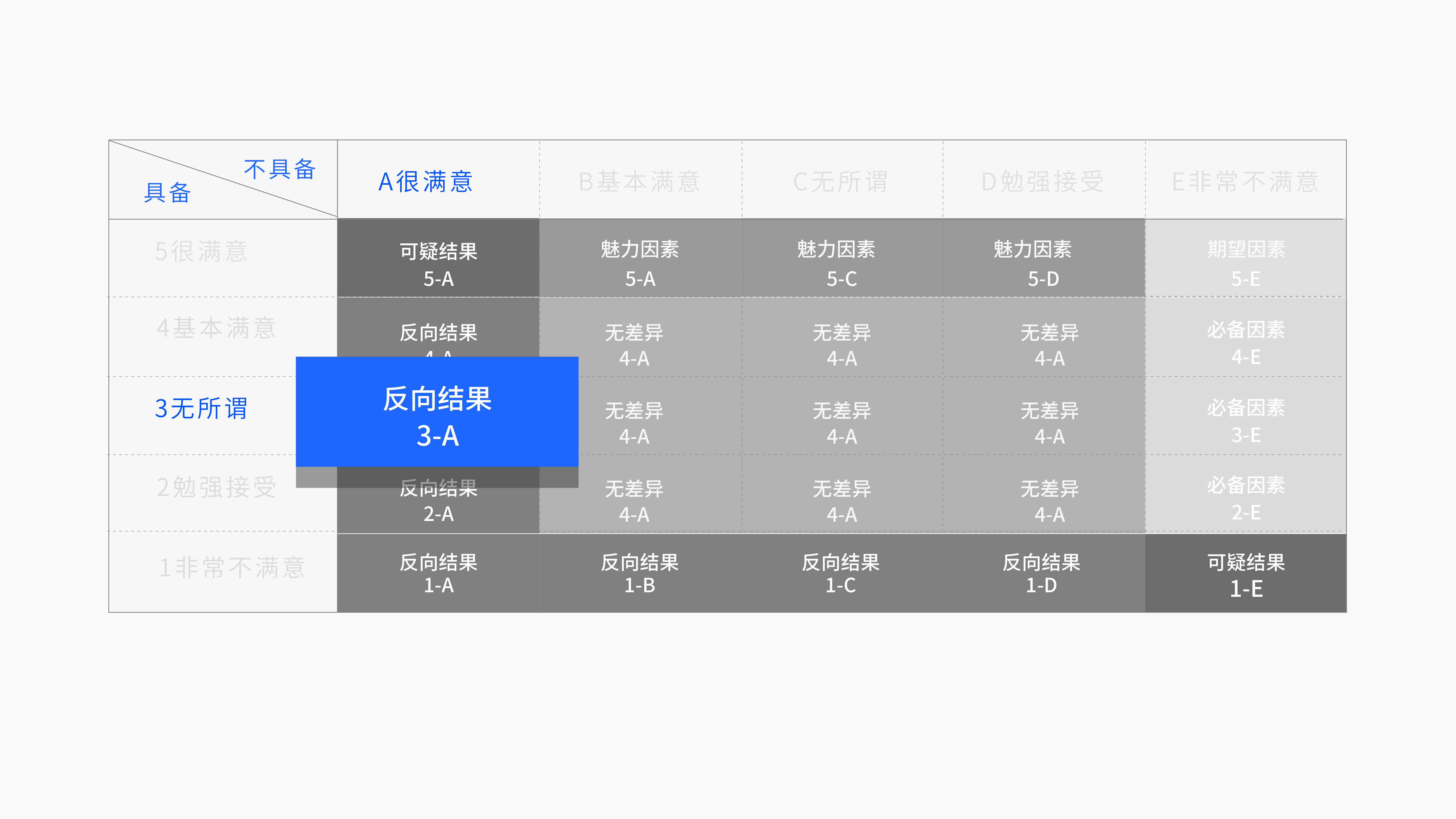
如果答案落在上图所示的的单元时候,说明你的产品具备这个功能的时候,用户觉得是无所谓的态度。当你的功能不具备的时候,用户会是很喜欢的态度。
8.1 如何查看
图示可以看到,如果组合答案是落在黄色区域则代表该功能是必备因素、绿色则代表期望因素、红色则代表是魅力因素、灰色则为无差别因素、蓝色则是反向因素。
8.2 可疑结果
如果答案组合中出现这种情况,你产品具备或者不具备这个功能的时候,用户都很喜欢或者都很不喜欢,就说明是一种可疑结果。这样的用户数据我们就不要了,因为他是瞎写的。
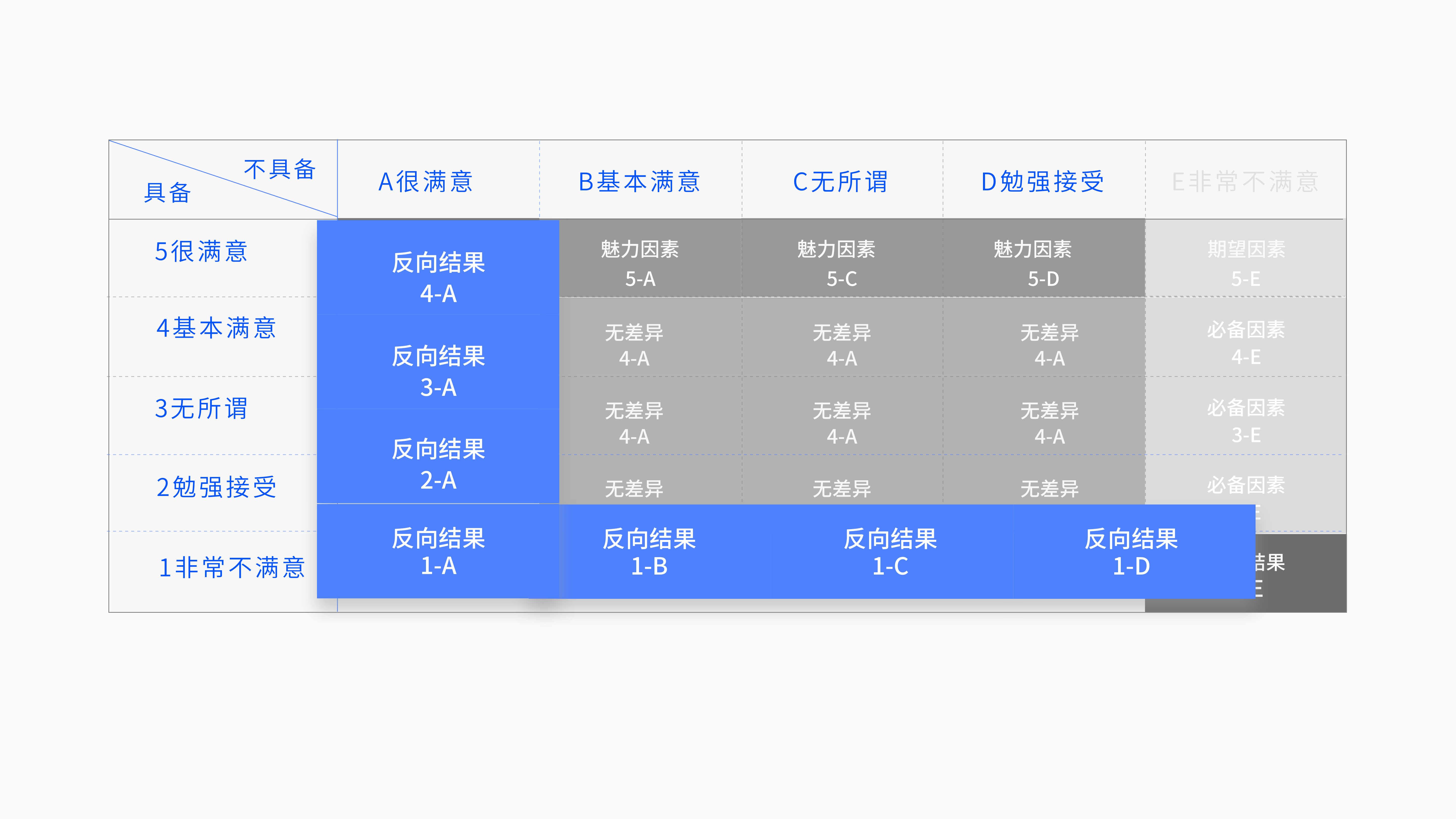
8.3 反向结果
蓝色区域,我们来看方向结果的这个共同点,其实是和前面反向属性是一致的。当功能具备的时候,用户就很不喜欢。当这个功能不具备的时候,用户是很喜欢的。很明显的反向属性的结果。
一共七个蓝色的单元,当你的答案落在蓝色区域的格内的时候,就说明该功能是不能做的,做了以后用户就不开心,是得罪用户的功能。
8.4 魅力因素
红色单元格代表的是:当功能具备的时候,用户都是选择很喜欢;当不具备的时候,表现的态度是理所当然 、无所谓、勉强接受。
如果功能的答案组合形式是三种之一的话,那么说明功能是魅力因素。因为当没有的时候,用户好像不会怎么样,也能接受,有的时候呢?
他很开心 ,是典型的魅力属性。

8.5 无差异
如果你的答案组合形式是落在灰色九种之一的话,就说明功能做不做都一样。做也无所谓,不做也能接受,所以这个功能可做可不做,一般我们是选择不做的。

8.6 期望因素
绿色区域:具备,用户很喜欢;不具备,用户很不喜欢的时候,就说明他是期望因素(和前面的期望属性是一致的)。

8.7 必备因素
出现黄色三种之一组合形式的时候,是必备因素了。
具备的时候,用户觉得理所当然无所谓,勉强接受 ,感情不强烈;一旦不具备用户很不喜欢,他是属于必备因素。当你的功能出现在三种答案组合形式中的一种的时候,功能属于必备属性。

9. 如何判断属于哪一种属性
原则:总和占比多者取胜。
哪个单元格中的选择的人数最多,单元的是颜色,它属于那种结果属性了,该功能就是那种属性。
举例:
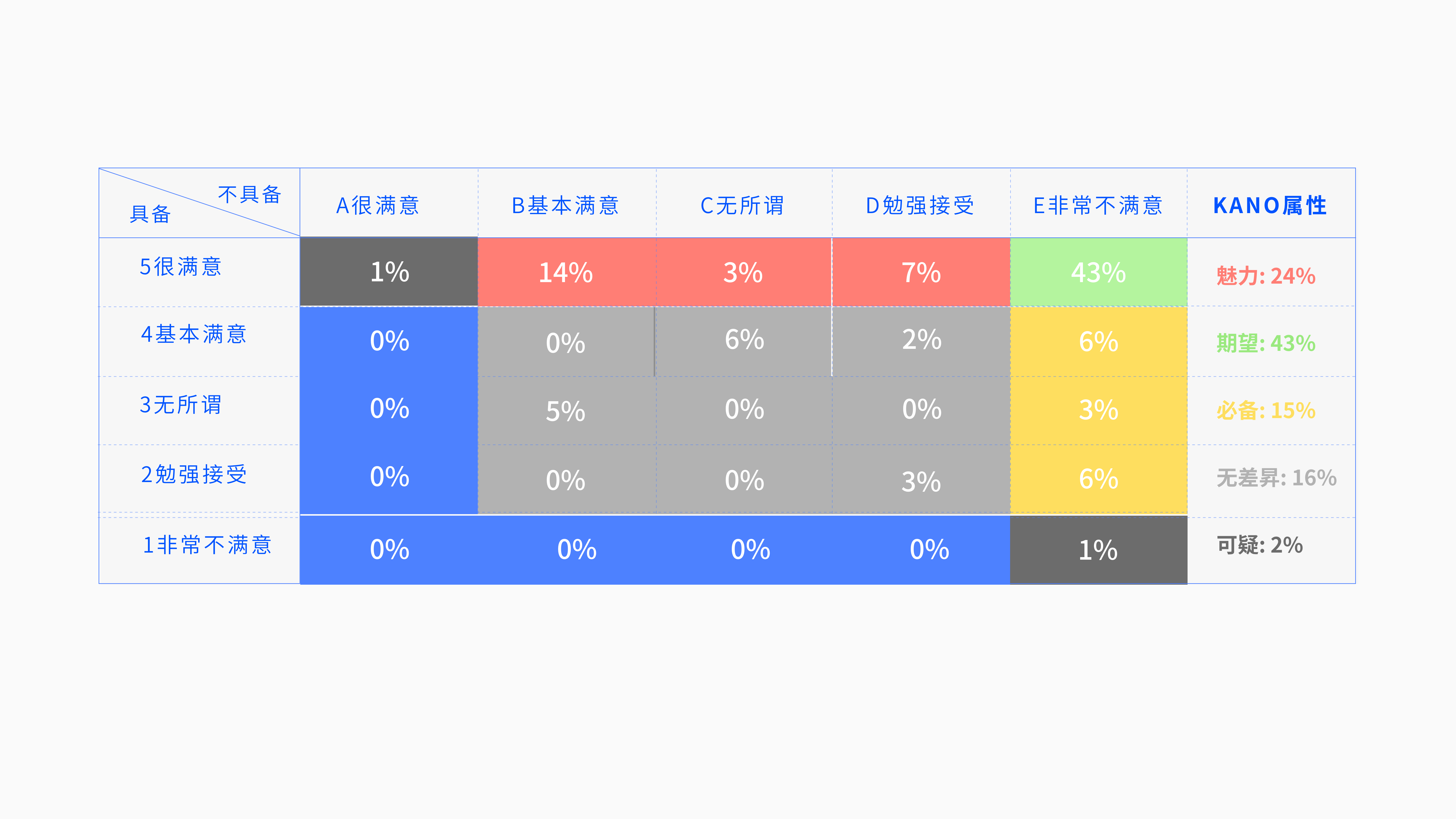
注意点:一道题目是对应上面的一张表格的。
我们要假设我们现在有100个用户,我们要计算出用户在25个选项里面?每个选项到底有多少用户选择了?每个选项的百分比是多少?我们把百分比给标上去,然后同颜色的相加:
- 黑色区域:可疑结果 ,百分之零的用户选择这个选项 ,可疑记为:2%;
- 红色区域:魅力属性,的人数占比分别是:14%+3%+7%,即魅力人数占比:24%;
- 绿色区域:期望属性,占比43%,即该功能选择是期望属性的人数占比是:43%;
- 黄色区域:必备属性,占比6%+3%+61%,即该功能选择是必备属性的人数占比是:15%;
- 灰色区域:无差别属性,占比6%+2%+5%+3%,即该功能选择是无差异属性的人数占比是:16%;
- 蓝色区域:反向属性,占比0%,即该功能选择是无差异属性的人数占比是:0%。
进行大小对比:绿色>红色>黄色、期望>魅力>无差异>必备>可疑>反向。
结论:说明该功能属于期望属性功能。
10. Better系数和Worse系数
10.1 适用场景
当属性占比出现两个第一的时候,这个时间段我只有一个功能开发的排期,那我选哪个呢?当期望属性和必备属性都是40%的时候,我们应该如何决定?
这个时候需要用到两个系数做对比了。
10.2 Better系数和Worse系数计算方法
Better系数=(魅力属性+期望属性)/(魅力属性+期望属性+必备属性+无差异因素)
Worse系数=(必备属性+期望属性)/(魅力属性+期望属性+必备属性+无差异因素)(-1)

10.3 判断方法
当两个功能 ,他的所选择的用户数又是百分比一模一样的时候,我们就把Better系数算出来。这个功能如果做的话,用户的满意度大概可以提升多少?Worse系数是相反的,任务都不做的话,我的满意度会下降多少?
做了以后满意度提升度更大,我就做哪个。或者哪功能不做满意度下降会更多,那我就做哪个.
10.4 Worse系数或者Better系数作用
Worse系数或者Better系数是当用来无法无法根据属性来去做优先级的时候,但是又不得已一定要选做一个的时候,就可以进一步看功能的Worse系数或者Better系数。
11. 制作所有功能汇总表,选择部分属性制作汇总图
11.1 汇总表制作
如上图:该功能的KANO属性是属于魅力属性功能,功能二属于魅力属性,功能三是必备,功能四和功能五是无差异属性,功能三必备属性反正是优先做的嘛。
但是一和二都是魅力属性,我们该做哪个呢?先做哪个呢?
我们就可以看一下他们的Better系数分别是89%和67%,按照逻辑我们就先做89%的Better系数,Worse系数或者Better系数看一个即可,优先看Better系数。
那我们就可以根据Worse系数或者Better系数的绝对值,我们可以把它做成一张图表 ,因为每功能,它都会有者Better系数,也会有Worse系数。那就有横纵坐标就可以确定了,我们就把它做成图表,每小点就带着功能属性。
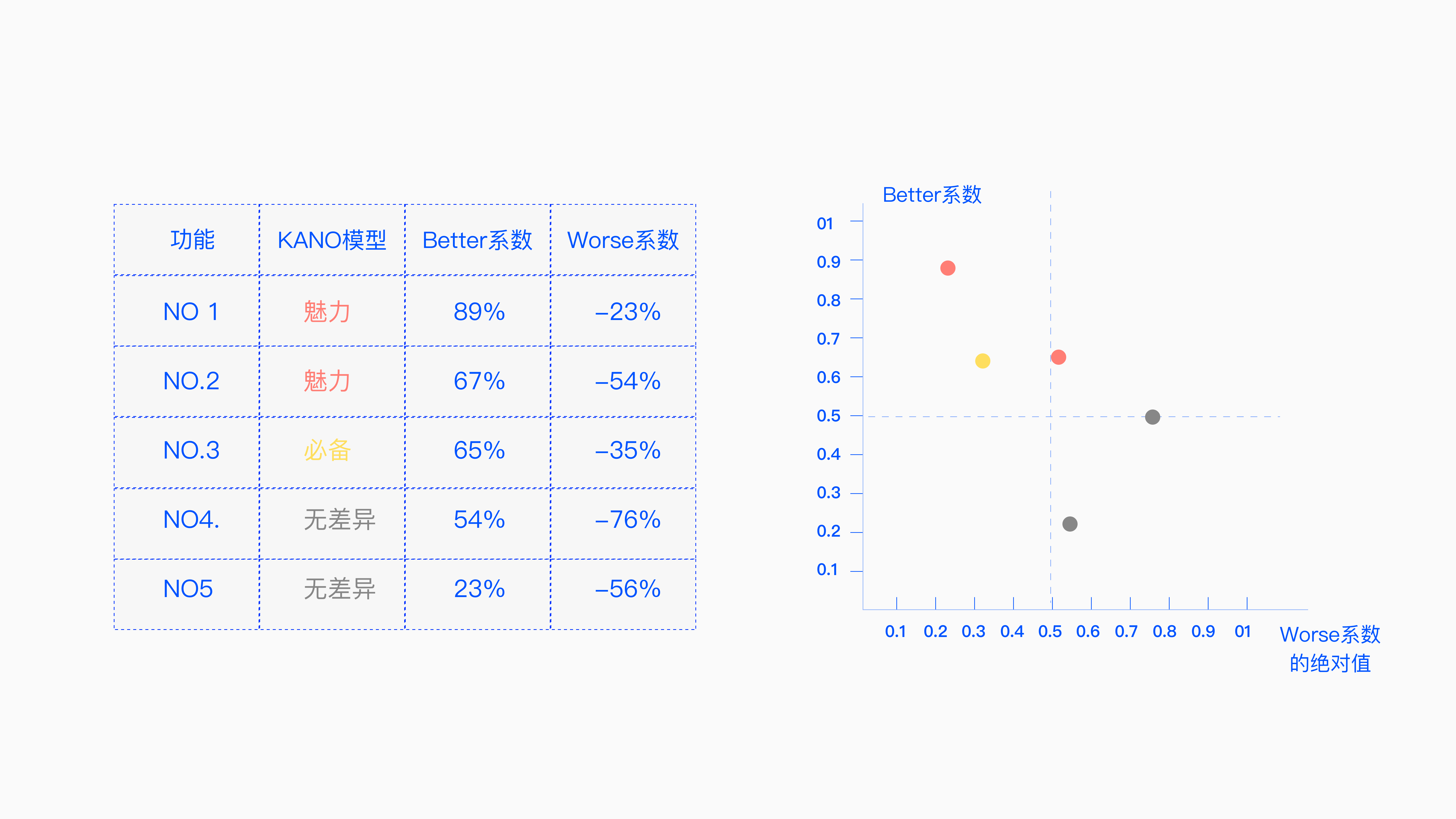
11.2 小规律
其实我们会发现小规律,基本上如果Better系数大于50%的话,也大于零点五的话,基本上都是魅力因素。
如果Better系数小于50%里面的话基本上属于无差异的因素了,当然上的一些小规律是没有什么依据的,基本是靠经验得来的,具体是什么因素直接算基本就知道了。
11.3 确定排序
接下来我们在讨论事情,比方说我们已经定下来了,把我们要做几个功能,每个功能它到底是属于属性,我们都确定了好。
11.4 小结
那我就可以根据他所属的属性来把些功能排优先级了。
当两个功能它都属于同一种属性,但是一定要排出优先级的话,那么Better系数越大,他优先级越高;或者Worse系数越小,它的优先级会越高。
12. KANO模型优缺点
12.1 优势
12.1.1 细致全面的挖掘功能的特质
它的优势就在于是呢?他可以按照五个功能属性。基本上五个功能属性已经很全面了,帮你细致的来定义,它属于哪种功能属性的特性。
12.1.2 可以帮你进行优先级的排期来辅助项目
12.1.3 原来用户没有抱怨,并不代表他满意,要转变我们的思维认知
12.2 不足
12.2.1 引起情绪上的波动,引起数据质量的下降
KANO模型也会有一些不足。
我们来看一下,比方说我们会发现比较墨迹,因为他一道题目要问两遍,正想问一遍反向的一遍。会引起用户情绪上的焦躁,他填到一半觉得特别烦躁,不填了也是正常的。
避免方法:
我们尽量减少要去探索了功能的个数,因为你有多少个功能,意味着你的屏幕亮是双倍的。你有十个功能,那你就要问二十遍 ,分别是正反上课玩一遍了。
建议大家在做KANO模型的时候,功能最好控制在十个以内,因为10个已经是二十道题目了。
12.2.2 部分功能属性用户也许并不是很好理解
很多功能属性用户也许并不是很好理解,说我们要把定义写的很清楚。如果说定义,觉得还是特别官方写不清楚的话,可以附上一些用户案例,就一般讲述。
避免方法:
用户遇到问题的时候,他用了功能解决了问题,得到帮助。我可以通过一些用户案例来做一些诠释备注,帮助用户更好地去理解功能。
12.2.3 我很喜欢”和“我很不喜欢”过于极端化
有些用户,比较喜欢偏向于中庸之道,对于我很喜欢和我很不喜欢种选项,又不会觉得太极端化,我不好意思选的。
避免方法:
如果发现自己的用户有种特征的话,可以改成把很字去掉。那那些有些用户就不会觉得太极端化了。
12.3 样本相对越多,数据相对越准确
那还有我们归类的时候经常会出现频数相等或者近似的情况,比方说50%的人选择认为功能是期望属性,50%人认为他是魅力属性,有时候会经常出现这种情况?那怎么办呢?
其实就告诉我们,其实样本量是很重要的,你的样本越丰富,参加调研的用户数越多,那么你就越不出现种情况 ,样本量大最好多一点。
那如果发现有种情况出现了,可以适当再增加样本量,看看结果会不会有一些变化。
12.4 问卷人数建议
目前KANO问卷,咱们最好也是够按照正常的问卷的填写量小样本填写了。
按照三十个人来算,三十人也是我们正常的问卷的最小统计单位。KANO问卷跟正常的就一样,回收有效样本量至少三十的来做。
13. 注意事项

13.1 需求沟通
首先第一步在需求沟通方面,其实和所有的调研是一样的。我们在和业务方沟通项目的时候,一定要明确调研的目的。
反复的问自己次调研是不是适合用KANO模型去解决? 利用卡诺模型去做调研的意义和好处在哪里 ?
如果我们经过分析讨论,发现这次用卡诺模型可以很好的贴合业务需求,也可以真正的帮助解决问题,那我们就可以用它。
同时,如果需求沟通阶段 ,如果说我们的需求沟通阶段已经够深入,能够了解用户了解业务了,那么在我们编写问卷的时候,其实就可以更加的全面和清晰。
13.2 个问卷编制的问题
因为KANO问卷呢,会有正问和反问,两种问法会导致用户的疲倦厌倦情绪,我们要更加怎么样让用户更加方便的去填写问卷,我们要在方面去下功夫。
比方说:我们在问卷的前面加入一些填写说明,确保用户,是理解问卷怎么做的。
如果功能定义阐述不清楚,我们就可以加入一些典型的用户案例,让用户可以生动地去了解功能点的作用。
问卷的措辞要简单具体避免语义上的歧义。
那么,如果说不能确定问卷,有没有说清楚,还是可以按照我们之前的方法——找一些用户做些预调研,看一看哪些问题是不清楚的,我们可以加以讨论,把它完善。
时间允许的话建议使用电话访问。
问卷方式,我们真正的去做问卷投放的过程当中,还是会有一些用户,不太理解某一些功能点 ,他会写选择错误之类的。
在时间允许的情况下,KANO模型其实不太适合直接发放给用户做的,最好是通过电话的形式一对一的和用户进行交流,确保数据的质量。因为当你一对一教你的时候,用户是真正能够听懂的。我们可以用电话问卷的形式来做。
13.3 数据的清理
数据转化的时候需要特别的细心,真的要特别的细致,稍微有一点点粗心是很容易出错的。
13.4 合理解释
以及最后,比方说你把功能定义出来是那种属性了,你肯定是要给到合理的解释的。
比方说:他是属于期望性功能,那你是不是能够有非常富有逻辑的、自己能能不能够认同的答案?逻辑上是不是解释的通,认为他是期望属性的。 如果你自己都解释不通的话,你把答案丢给业务放产品。
他们如果不理解的话,你要怎么样去解释呢?如果你都觉得你得出的答案是莫名其妙的?
一定要找到。
找到些填写KANO问题的用户去跟他聊一聊,为什么你觉得有功能?你的评价是这样的;没有功能,你的评价是这样的,把它背后的原因给了解清楚。
在这种情况下,你才能够深入的有逻辑性的去真正理解,为什么功能是这样的属性。
13.5 回访的重要性
KANO问卷为说他适合用电话问卷的形式做?
因为当这个用户,给到你一些让你觉得不太正常。匪夷所思的一些选项或者态度的时候,你可以及时的问为什么?
那当然,如果你是通过纸质的问卷发放或在线问卷来做的话,那么拿到答案虽然并不要求你把每用户都做回访。但是如果最后定义出的问题,功能属于哪一种属性,你自己都没有办法给出合理的解释的话,那你一定要做回访 。
要不然当所有人都不认同答案的时候,你不就白做了吗?
全文总结:
去小试牛刀,自己体验一下,哪怕做一个用户、两个用户、三个四个五个用户都好。
主要来梳理一下,看看拿到问卷以后,你会从数据的录入、转型转化换算、到统计分析,这种简单的步骤是不是能够无差零差错的去把它完成 ,最后也能够拿到结果,大家可以自己去尝试下。
交互方法论,其核心意义在于实践,实践之前的理论也必须充分去了解。
可能在工作中你不一定会有机会使用上KANO模型这个方法,毕竟不是每个人都处在那么理想的环境,更多的还是“你就按照我的来就行”的一个大坏境。
但我们依旧需要保持不断学习,不断思考,不断自我反驳的习惯。这样,回头看的时候,曾经那些糟糕的事情、那些一直抱怨的事情、都在悄悄变好。
作者:木七木七,欢迎交流~
本文由 @木七木七 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash ,基于 CC0 协议