AI产品经理必修课:机器学习算法

一、什么是机器学习
1. 含义
机器学习machine learning,是人工智能的分支,专门研究计算机怎样模拟或实现人类的学习行为,其通过各种算法训练模型,并用这些模型对新问题进行识别与预测。
本质上机器学习是一种从数据或以往的经验中提取模式,并以此优化计算机程序的性能标准。
2. 解决什么问题
解决复杂规则的问题。如果简单规则可以实现,则没必要借助机器学习算法实现。
2009年ACM世界冠军戴文渊加入百度的时候,百度所有的搜索、广告都是基于1万条的专家规则。借助于机器算法,戴文渊把百度广告的规则从1万条提升到了1000亿条。与此相对应的,百度的收入在四年内提升了八倍。
3. 三个名词之间的关系
人工智能>机器学习>深度学习
以机器学习算法是否应用了神经网络作为区分标准,应用了多隐含层神经网络的机器学习就是深度学习。
4. 对AI产品经理的要求
- 熟悉机器学习流程(详见文章第三部分);
- 了解机器学习可以解决的问题分类(详见文章第四部分);
- 了解算法的基本原理;
- 了解工程实践中算数据和计算资源三者间的依赖关系等。
二、机器学习的基础
1. 机器学习的基础——数据
人工智能产品由数据、算法、计算能力三部分组成,而数据,是其中的基础。

图片来源:http://www.sohu.com/a/160316515_680198
全球顶尖人工智能科学家李飞飞的成功离不开ImageNet千万级的数据集。
“ImageNet 让 AI 领域发生的一个重大变化是,人们突然意识到构建数据集这个苦活累活是 AI 研究的核心,”李飞飞说: “人们真的明白了,数据集跟算法一样,对研究都至关重要。”“如果你只看 5 张猫的照片,那么你只知道这 5 个摄像机角度、照明条件和最多 5 种不同种类的猫。但是,如果你看过 500 张猫的照片,你就能从更多的例子中发现共同点。”
数据量多大为好?
- 千级别:基本要求,可以解决简单手写体数字识别问题,例如MNIST;
- 万级别:一般要求,可以解决图片分类问题,例如cifar-100;
- 千万级:比较好,例如ImageNet,准确率2%左右,超过了人类5.1%。
2. 数据的衡量
人工智能产品对数据除了有量的要求,还有质的要求,衡量数据质量的标准包括四个R:关联度relevancy(首要因素)、可信性reliability(关键因素)、范围range、时效性recency。
数据获取地址:
- ICPSR:www.icpsr.umich.edu
- 美国政府开放数据:www.data.gov
- 加州大学欧文分校:archive.ics.uci.edu/ml
- 数据堂:www.datatang.com
三、机器学习的流程
机器学习的流程可以划分为以下几个主要步骤:目标定义、数据收集、数据预处理、模型训练、准确率测试、调参、模型输出。

图片来源:https://research.fb.com/the-facebook-field-guide-to-machine-learning-video-series/
机器学习流程拆解:
1. 目标定义
确认机器学习要解决的问题本质以及衡量的标准。
机器学习的目标可以被分为:分类、回归、聚类、异常检测等。
2. 数据采集
原始数据作为机器学习过程中的输入来源是从各种渠道中被采集而来的。
3. 数据预处理
普通数据挖掘中的预处理包括数据清洗、数据集成、数据转换、数据削减、数据离散化。
深度学习数据预处理包含数据归一化(包含样本尺度归一化、逐样本的均值相减、标准化)和数据白化。需要将数据分为三种数据集,包括用来训练模型的训练集(training set),开发过程中用于调参(parameter tuning)的验证集(validation set)以及测试时所使用的测试集(test set)。
数据标注的质量对于算法的成功率至关重要。
4. 模型训练
模型训练流程:每当有数据输入,模型都会输出预测结果,而预测结果会用来调整和更新W和B的集合,接着训练新的数据,直到训练出可以预测出接近真实结果的模型。
5. 准确率测试
用第三步数据预处理中准备好的测试集对模型进行测试。
6. 调参
参数可以分为两类,一类是需要在训练(学习)之前手动设置的参数,即超参数(hypeparameter),另外一类是通常不需要手动设置、在训练过程中可以被自动调整的参数(parameter)。
调参通常需要依赖经验和灵感来探寻其最优值,本质上更接近艺术而非科学,是考察算法工程师能力高低的重点环节。
7. 模型输出
模型最终输出应用于实际应用场景的接口或数据集。
四、算法分类
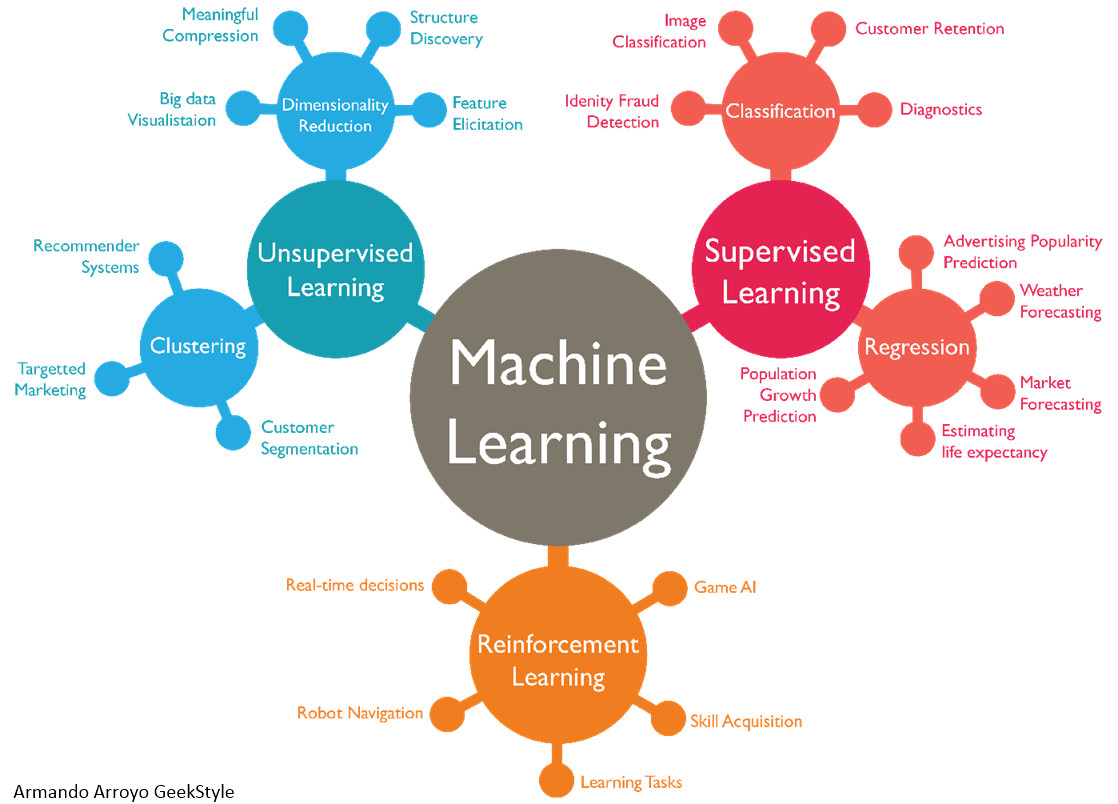
图片来源:https://www.datasciencecentral.com/profiles/blogs/machine-learning-can-we-please-just-agree-what-this-means
机器学习囊括了多种算法,通常按照模型训练方式和解决任务的不同进行分类。
1. 按照模型训练方式不同,可以分为
(1)监督学习supervised learning
定义:监督学习指系统通过对带有标记信息的训练样本进行学习,以尽可能准确地预测未知样本的标记信息。
常见的监督学习类算法包括:人工神经网络artificial neural network、贝叶斯bayesian、决策树decision tree、线性分类器linear classifier(svm支持向量机)等。
(2)无监督学习unsupervised learning
定义:无监督学习指系统对没有标记信息的训练样本进行学习,以发现数据中隐藏的结构性知识。
常见的无监督学习类算法包括:人工神经网络artificial neural network、关联规则学习association rule learning、分层聚类hierarchical clustering、聚类分析cluster analysis、异常检测anomaly detection等。
(3)半监督学习semi-supervised learning
含义:半监督学习指系统在学习时不仅有带有标记信息的训练样本,还有部分标记未知信息的训练样本。
常见的半监督学习算法包括:生成模型generative models、低密度分离low-density separation、基于图形的方法graph-based methods、联合训练co-training等。
(4)强化学习reinforcement learning
定义:强化学习指系统从不标记信息,但是会在具有某种反馈信号(即瞬间奖赏)的样本中进行学习,以学到一种从状态到动作的映射来最大化累积奖赏,这里的瞬时奖赏可以看成对系统的某个状态下执行某个动作的评价。
常见的强化学习算法包括:Q学习Q-learning、状态-行动-奖励-状态-行动state-action-reward-state-action,SARSA、DQN deep Q network、策略梯度算法policy gradients、基于模型强化学习model based RL、时序差分学习temporal different learning等。
(5)迁移学习transfer learning
定义:迁移学习指通过从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学习社区持续关注的话题。
迁移学习对人类来说很常见,例如,我们可能会发现学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴。
常见的迁移学习算法包括:归纳式迁移学习inductive transfer learning、直推式迁移学习transductive transfer learning、无监督式迁移学习unsupervised transfer learning、传递式迁移学习transitive transfer learning等。
(6)深度学习deep learning
定义:深度学习是指多层的人工神经网络和训练它的方法。一层神经网络会把大量矩阵数字作为输入,通过非线性激活方法取权重,再产生另一个数据集合作为输出。
这就像生物神经大脑的工作机理一样,通过合适的矩阵数量,多层组织链接一起,形成神经网络“大脑”进行精准复杂的处理,就像人们识别物体标注图片一样。
常见的深度学习算法包括:深度信念网络deep belief machines、深度卷积神经网络deep convolutional neural networks、深度递归神经网络deep recurrent neural networks、深度波尔兹曼机deep boltzmann machine,DBM、栈式自动编码器stacked autoencoder、生成对抗网络generative adversarial networks等。
迁移学习与半监督学习的区别:迁移学习的初步模型是完整的,半监督学习的已标注部分无法形成完整的模型。
2. 按照解决任务的不同分类,可以分为
(1)二分类算法two-class classification,解决非黑即白的问题。
(2)多分类算法muti-class classification,解决不是非黑即白的多种分类问题。
(3)回归算法regression,回归问题通常被用来预测具体的数值而非分类。除了返回的结果不同,其他方法与分类问题类似。我们将定量输出,或者连续变量预测称为回归;将定性输出,或者离散变量预测称为分类。
(4)聚类算法clustering,聚类的目标是发现数据的潜在规律和结构。聚类通常被用做描述和衡量不同数据源间的相似性,并把数据源分类到不同的簇中。
(5)异常检测anomaly detection,异常检测是指对数据中存在的不正常或非典型的分体进行检测和标志,有时也称为偏差检测。异常检测看起来和监督学习问题非常相似,都是分类问题。都是对样本的标签进行预测和判断,但是实际上两者的区别非常大,因为异常检测中的正样本(异常点)非常小。
3. 对AI产品经理的要求
产品经理应了解和掌握每种常见算法的基本逻辑、最佳使用场景以及每种算法对数据的需求。
这样有助于:
- 建立必要的知识体系以与研发人员进行良好的交流;
- 在团队需要的时候提供必要的帮助;
- 识别和评估产品迭代过程中的风险、成本、预期效果等。
五、各类算法的对比
1. 算法与学习过程的对比
- 监督学习——上课:有求知欲的学生从老师那里获取知识、信息,老师提供对错指示、告知最终答案的学习过程;
- 无监督学习——自习:没有老师的情况下,学生自习的过程;
- 强化学习下——自测:没有老师提示的情况下,自己对预测的结果进行评估的方法。
2. 算法适用场景的影响因素
- 业务核心问题;
- 数据大小、质量;
- 计算时间要求;
- 算法精度要求。
3. 算法优缺点及适用场景
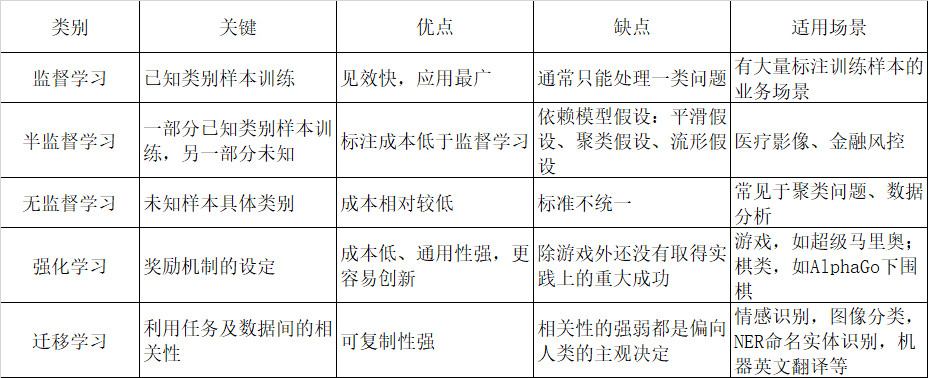
注意:
(1)目前监督学习和强化学习是目前应用范围最广且效果最好的机器学习方式。
(2)深度学习将在后续的文章中单独介绍。
(3)半监督学习依赖以下3个模型假设才能确保它良好的学习性能。
1)平滑假设(Smoothness Assumption)
位于稠密数据区域的两个距离很近的样例的类标签相似,当两个样例北稀疏区域分开时,它们的类标签趋于不同。
2)聚类假设(Cluster Assumption)
当两个样例位于同一聚类簇时,它们在很大的概率在有相同的类标签。这个假设的等价定义为低密度分类假设(Low Density Separation Assumption),即分类决策边界应该穿过稀疏数据区域,而避免将稠密数据区域的样例划分到决策边界两侧。
3)流形假设(Manifold Assumption)
将高维数据嵌入到低维流形中,当两个样例位于低维流形中的一个小局部邻域内时,它们具有相似的类标签。
#参考资料#
(1)参考书籍:
- 《自然语言处理实践—聊天机器人技术原理与应用》,王昊奋,邵浩等
- 《人工智能产品经理:人机对话系统设计逻辑探究》,朱鹏臻
- 《人工智能产品经理:AI时代PM修炼手册》,张竞宇
- 《图解机器学习》,杉山将
(2)相关网站
- https://www.stateoftheart.ai/
- https://www.stateof.ai/
- https://www.easyaihub.com/
- https://blog.csdn.net/daisy9212/article/details/49509899
- http://www.sohu.com/a/160316515_680198
- https://research.fb.com/the-facebook-field-guide-to-machine-learning-video-series/
- https://www.datasciencecentral.com/profiles/blogs/machine-learning-can-we-please-just-agree-what-this-means
- https://blog.csdn.net/weixin_42137700/article/details/87355812
本文由 @Alan 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议





