做数据分析如何从囚徒困境到合作的进化
编辑导读:囚徒困境是指两个被捕的囚徒之间的一种特殊博弈,说明为什么甚至在合作对双方都有利时,保持合作也是困难的。做数据分析时,也时常会遇到囚徒困境。应当如何解决呢?本文作者对此进行了分析,希望对你有帮助。

在推进业务线各种项目的过程中,做数据分析的人员在整体项目中起到了非常核心的作用,不管是决策支持还是数据支持,有着对业务线承上启下的意义,需要了解业务,还要与多个部门、各种不同外部组织以及个人打交道,但是,有的时候结果往往很难达到预期的效果,可能遇到项目无法推进,与技术或者业务人员无法有效的沟通等问题,其 主要原因之一就是在工作过程中不知不觉的陷入了 “囚徒困境” 。
而从“社会学”角度观察,不同组织之间,容易出现“本位主义”,越大的组织,越容易陷入“囚徒困境”中。那么, 做数据分析的人员如何有效的解决工作中的“囚徒困境”呢?
所以今天,小飞象非常荣幸的邀请到了快用云科创始人兼CEO, 创业老兵周海鹏 ,最近十年创业,一直在大数据技术、数据分析、数据应用的各个方面工作。服务过很多世界五百强企业(金融、房产、零售、医疗),对相关行业的背景、数据分析、数据智能和数据应用方面都有详细的了解。
将会为大家分享《 做数据分析如何从囚徒困境到合作的进化 》 的相关内容,分为四部分:
- 线下环境观察和零售选址案例
- 什么是所谓的“囚徒困境”
- 数据工作领域的囚徒困境
- 如何有效的解决囚徒困境?
做一个对世界充满好奇的人! 在分享之前,我们可以先思考几个问题:
- 你认为/了解过“囚徒困境”是什么?
- 你结合自身经历,是否在工作中也遇到过“囚徒困境”?
- 你觉得在数据分析领域的囚徒困境好解决么?以及数据分析有什么作用?
- ……
在分享的过程中,建议全程认真听,带着思考来听(去看),希望通过本次分享,帮助大家剖析一下“囚徒困境”和“纯粹理想情况下的解决方案”,并给做数据分析的人员提供一些思路,有任何问题都可以随时交流哦!
01 大数据时代如何推动智能化,线下环境观察和零售选址

在进入正题之前,我先讲一下咱今天分享的核心思想,我在一个大数据公司创业,做了好几个产品,从统计分析平台,到广告监测平台,再到用收集到的数据为移动设备打标签,最后到用这些数据进行商业分析,帮助客户增收降本。在这十年的工作中,我发现一个非常重要,但是很困难的职业— – 数据(商业)分析师 。
作为一个技术人员,我曾经以为数据分析师只要会写SQL,就可以做数据分析,但是随着工作年限的提高,我发现,做好数据分析的难度远高于我的想象。我从互联网上查找了一些关于“数据(商业)分析师技能要求”的文章,发现要想当好数据(商业)分析师,需要具备的能力可能远远超出技术人员的想象(如下图所示)

从这个图中,我觉得优秀的数据分析人员,简直就是个神的存在。从我常年在数据方面的工作而言,一个优秀的技术人员,可以很好的掌握这里面几项技术已经相当不错了。
那么,数据分析师如何成长成为这种神一样的存在呢?我认为,除了技术性因素外,还有一个组织问题:数据分析师在企业内承上启下,和多个部门、组织和个人打交道,在组织里起到组织核心的作用。从“社会学”角度观察,不同组织之间,容易出现“本位主义”,越大的组织, 越容易陷入“囚徒困境”中。
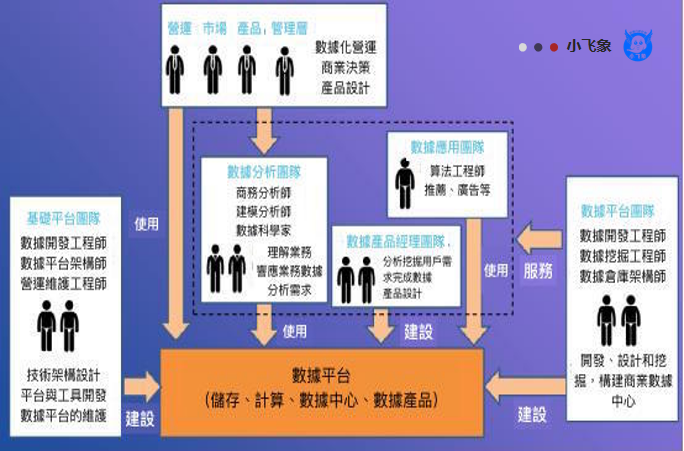
所以,我今天想剖析一下 “囚徒困境”和“纯粹理想情况下的解决方案 ”,并给数据分析师提供一点个人建议:数据(商业)分析师,应该以 “帮企业更好、更快决策” 为目标,寻求和下游(数据工程师团队)、左右(其他合作部门,例如销售、供应链团队等)、上游(老板)通力合作、保持有效沟通,减轻学习的负担,加快自身进化,最终成就了自己,也促进了企业发展。
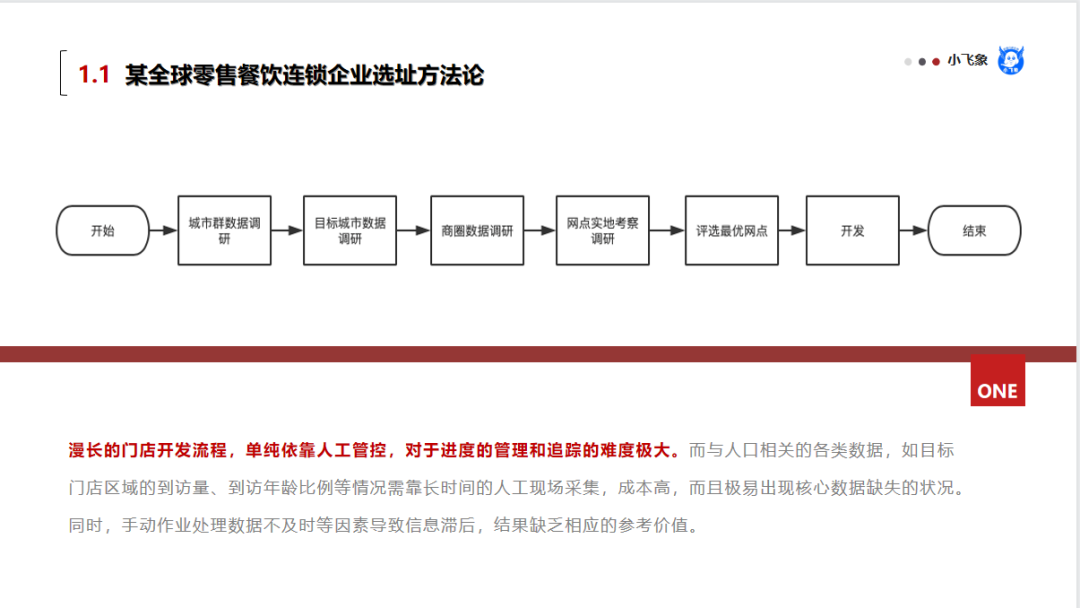
接下来,以某全球零售餐饮连锁企业选址的方法论为例,来讲讲在这个通过数据分析选址的项目中,出现的“ 囚徒困境 ”是如何解决的?
某全球零售餐饮连锁企业,在中国市场开一家火一家,除了特有的餐饮文化和严格的复制标准,还有一项在连锁餐饮界引以为豪的竞争力——选址成功率,几乎百分之一百的选址成功率!肯德基经营成功的首要三大因素必然是选址、选址、选址。
“选址”对于连锁经营实体的重要性不言而喻,但同时也是长久以来所有实体连锁的痛点 ,而且对于目标客群和商业模式并不清晰的便利店/超市连锁而言,选址的难度更高。
传统的选址作业流程主要靠人工调研和实地考察,大量及长时间周期的人工作业,使得选址开发的流程过长,同时人工作业模式也存在太多的不可控性。
漫长的门店开发流程,单纯依靠人工管控,对于进度的管理和追踪的难度极大。而与人口相关的各类数据,如目标门店区域的到访量、到访年龄比例等情况需靠长时间的人工现场采集,成本高,而且极易出现核心数据缺失的状况。
同时,手动作业处理数据不及时等因素导致信息滞后, 结果缺乏相应的参考价值。下图是PIE指标体系和应用。

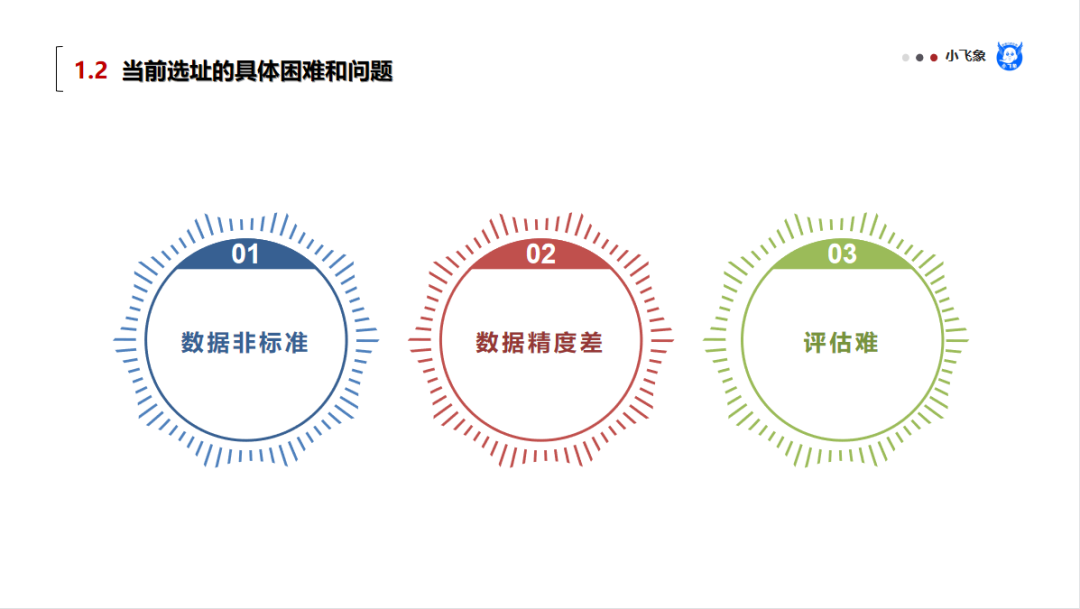
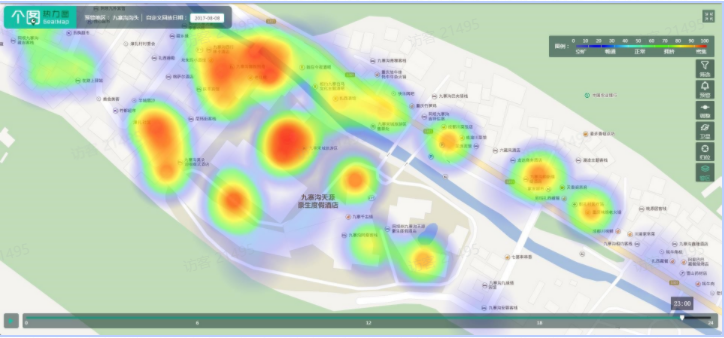
我们知道选址,在商圈数据调研的时候,会走访很多线下网点,还要采集很多线下环境数据,例如人口数据。我们可能可以从高德、百度获得这样的热力图,虽然看着非常焕丽。但是在精细的选址中却没有鸟用。
原因:在精细的选址中,业务方需要知道某个大楼、小区,甚至是小区的东门还是小区的西门人多。但是我们无法从这种图里获得具体的人口数字(或者指数)。
所以,数据不标准,现场调研的数据和地图数据无法绑定在一起。
场景:数据分析师发现地图上某个区域的流量特别大。他会找数据工程师进行排查:请帮忙查一下“某酒店”,流量为什么这么高?
数据工程师会反问:具体是哪个区域?能不能给我一个经纬度列表。
分析师可能没有工具获取经纬度列表,因此这个问题就耽误了,后续的分析会遇到意想不到的坑。
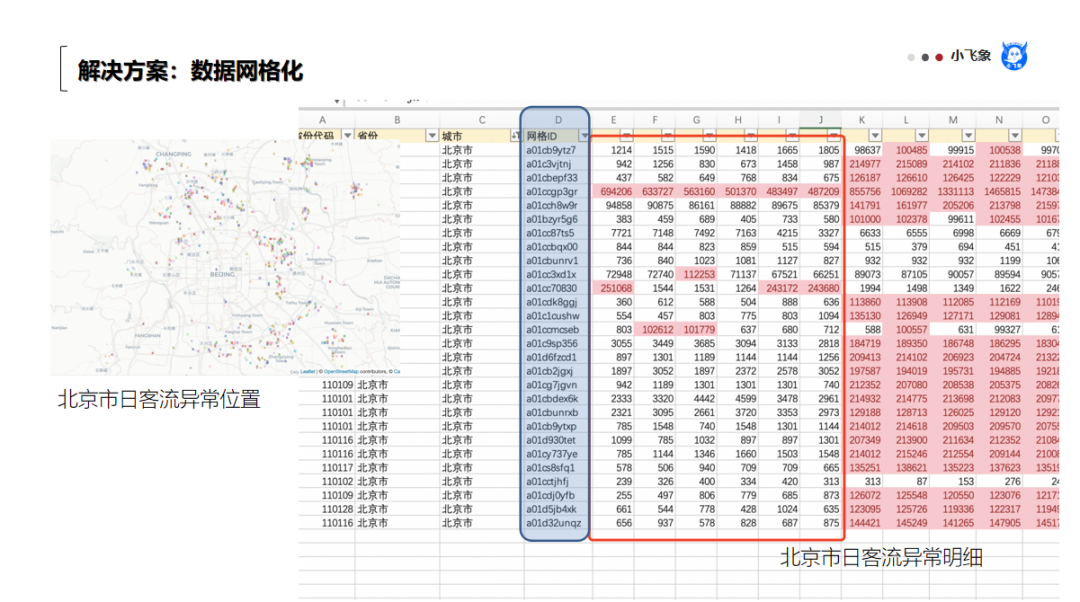
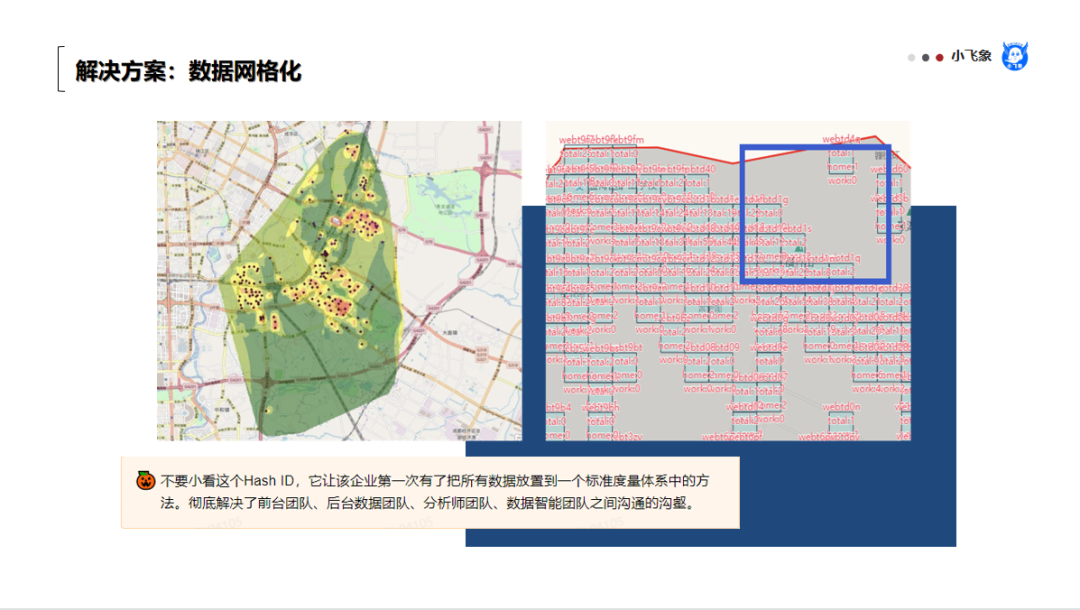
不要小看这个Hash ID,它让该企业第一次有了把所有数据放置到一个标准度量体系中的方法。彻底解决了前台团队、后台数据团队、分析师团队、数据智能团队之间沟通的沟壑。
在选址过程中,可能很多分析师都用过POI数据,如上图,客户提出了新的挑战。客户想估算出这个区域里人口的购买力指标,所以想用当前区域里房价来进行折算。但是,这个区域里,只有几个小区有房价数据,剩下的5、6个没有办法填充,造成这个指标一直参差不齐。
客户提出了新的挑战。客户想估算出这个区域里人口的购买力指标,所以想用当前区域里房价来进行折算。但是,这个区域里,只有几个小区有房价数据,剩下的5、6个没有办法填充,造成这个指标一直参差不齐。
所以,数据缺失多、数据精度比较差,无法对商圈进行标准的画像。
场景:数据分析师期待对左图进行分析,他手里有不少POI数据,但是,他如何给这块区域打标签呢?例如餐饮标签。
他想了个办法:区域中餐饮个数/区域的面积=此餐饮密度。
现场调研员拿到这个标签后会质疑:这个区域餐饮门店远比西南的高,这个密度不能显示现实情况。另外,现在只有十几种数据可以评估这块区域,调研员还想要更多的数据标签,例如房价标签、交通标签等等。但是,其他数据的缺失更多,更难标准化和归一化。
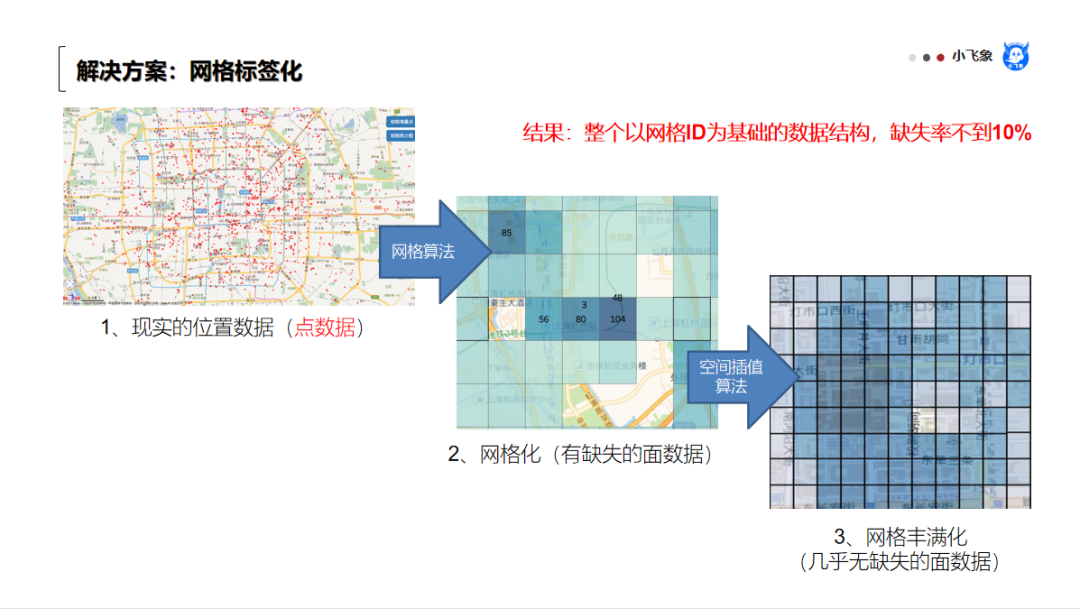
大家需要客观接受一个现实,就是这个世界离广泛、真实、准确的数据化,还差的远。在这种条件下,要多个团队(有巨大差异化的同事),进行合作、探索、挖掘数据的价值,就要给出一个有效、标准的框架和解决方案。
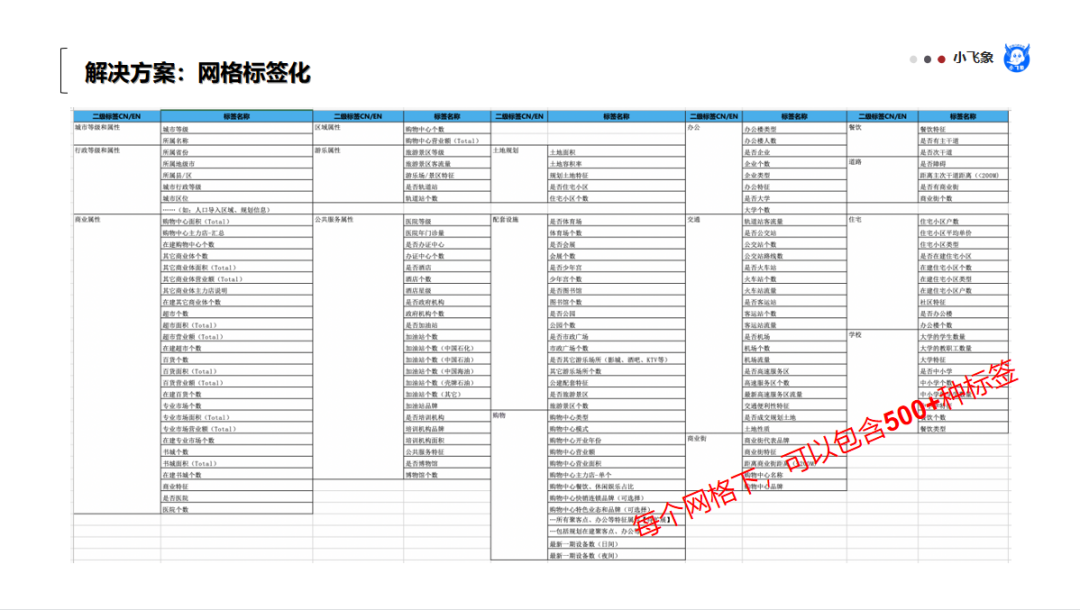
这套数字化的方法,让每一个网格都可以有一套标准、通用的标签,可以想象,原来不同团队需要在显示器前,大家一起看地图解决的问题,可以进一步转换成计算机自动进行计算的问题。
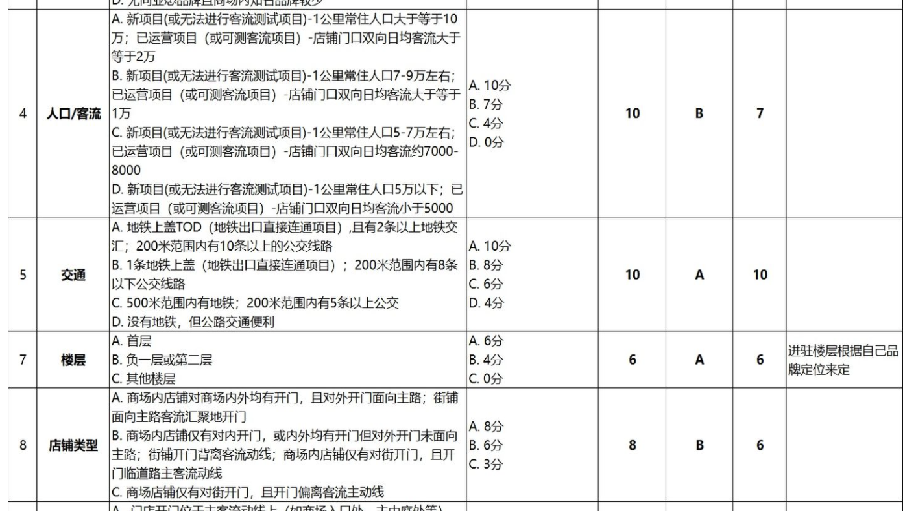
数据准备的差不多以后,想标准化评估一个区域,也是很难的,我们看上图,这种打分表,在选址团队中很常用,的确起到了一定作用。但是请注意,这个打分表是很主观的,而且无法精确量化。 所以,评估难,这种打分表,在选址团队中很常用,的确起到了一定作用。 但是请注意,这个打分表是很主观的,而且无法精确量化。
选址工作,是该企业成功的一个金钥匙。但是,随着企业的发展想三四线城市发展,如何快速评估一块区域,越来越不能靠调研员各地探访了。客户急需一种标准化的方法,来进行评估度量。 前线调研员需要和总部分析师一起,构建起一种沟通和评估的标准,这样,选址调研才能标准化、规模化 。

在选址评估上,客户也在转变,从原来的“线下调研员给一个门店,评估一个门店”,转换成“在城市所有网格里”智能搜索出潜在门店的模式。
我们进行门店选址模型探索。产出的模型,在上海市进行搜索,经过现实开店数据验证,在推荐的网点400米内,有80%的可能性有一家在运营的门店。解决进入同类型、同等级新城市冷启动问题。
公式:F(某网格开店成功概率) = 0.14*某网格购物中心个数1.24+0.101*某网格购物中心营业额0.88+0.08*某网格火车站流量1.2+……
虽然选址是一个数据分析和智能的冷门方向 ,但是要做的工作也有很多。在数字化企业的构建过程中,数据分析师一个非常重要的角色。他需要把很多工作串接在一起,得到对企业有价值的结论。但是现实的条件是残酷的。我给大家的建议,是边沟通、边解决问题,而且要时刻注意能不能做到数据标准化、算法智能化、应用简单化。让企业的上下游同事都可以认可数据采集、加工、分析的方法,最终让大家在数字化的世界中解决业务决策问题。
个人认为如何高效推进工作的方法总结:
标准化的数据架构(网格)
标准化的内容架构(标签)
标准化的评价架构(算法)
02 什么是所谓的“囚徒困境”

综上,我们了解的选址的案例,那到底什么是“囚徒困境”呢?
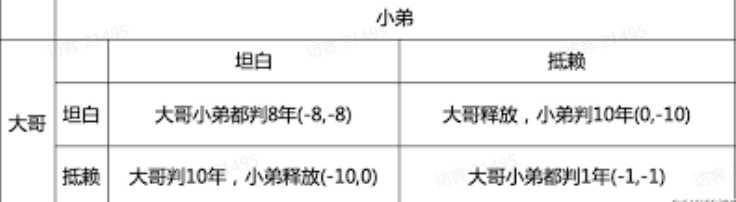
囚徒困境是博弈论的非零和博弈中具代表性的例子,反映个人最佳选择并非团体最佳选择。或者说在一个群体中,个人做出理性选择却往往导致集体的非理性。虽然困境本身只属模型性质,但现实中的价格竞争、环境保护等方面,也会频繁出现类似情况。


美国著名的科学家罗伯特·阿克塞尔罗德在1970年代向棘手的“重复囚徒困境”难题发起了冲击,并最终取得了重大突破。在他的研究之前,我们发现古往今来的众多学者对于人类能否跳出“囚徒困境”的诅咒都充满了悲观的看法,可是一战西线堑壕战里“圣诞停火”这种奇迹的出现,又证明人类在没有权威的情况下,其实是具有自发形成合作关系的可能性的。
阿克塞尔罗德利用当时刚刚兴起的计算机技术,沿着“计算模拟”这条不同于归纳和演绎的新研究路径,举办了三场对后世影响深远的“重复囚徒困境博弈策略的计算机锦标赛”,几十个出自世界各地不同学科专家之手的博弈策略作为比赛选手,在既定规则下彼此展开了激烈的对决。这三场比赛的结果直接指向了合作产生的本质,“圣诞停火”的秘密就藏在这三场比赛的背后。
试验的过程挺让人吃惊的:不同对手,经过激烈对抗,每个选择不同策略的参与者一再重复了很长时间之后,从利己的角度来判断, 最终“贪婪”策略趋向于减少,而比较“利他”策略更多地被采用 。他用这个博弈来说明,通过自然选择, 一种利他行为的机制可能从最初纯粹的自私机制进化而来 。最佳确定性策略被认为是“ 以牙还牙 ”。
这里要解释一下:以牙还牙不是字面意义上的,呈现死循环的报复,而是,有一定概率以德报德,以德报怨,但是,如果对手持续作恶,那么可以被激发的愤怒,也有一定概率相应的报复。这个试验说明了一个深刻的道理:以善意对待对手,推进整体合作的进化,是可以让大家走出囚徒困境的。
I.友善
最重要的条件是策略必须“友善”,这就是说,不要在对手背叛之前先背叛。在现实中,可以解释为:要尽可能善意的对待别人,不要抱怨、更不要给别人造成麻烦。
II.报复
但是,成功的策略必须不是一个盲目乐观者。要保持报复的可能,始终合作肯定不会获得最后的好结果(因为“下流”策略将残酷地剥削这样的傻瓜)。在现实中,一味的对邪恶妥协,只会造成彻底的囚徒困境和崩溃。
III.宽恕
成功策略的另一个品质是必须要宽恕。虽然它们不报复,但是如果对手不继续背叛,它们会一再退却到合作。这停止了报复和反报复的长期进行,最大化了得分点数。在现实中,我们要容忍别人的偶然的错误,给与一定的宽恕是挽救合作的必然条件。
IV.不嫉妒
最后一个品质是不嫉妒,就是说不去争取得到高于对手的分数(“友善”的策略必然不嫉妒,也就是说“友善”的策略永远无法得到高于对手的分数)。
03 数据工作领域的囚徒困境

正如背景部分描述的,数据工作领域里,数据分析师处于核心地位,在不同组织的协作中,容易出现“囚徒困境”。

经过好几轮折腾,数据分析师拿到数据,已经过去一周了,离老板给出的Deadline只剩下半天了。这时候肯定出现“囚徒困境”,
分析师一般会投诉:拿个数据太慢了,工程是会反诉:你的需求提的不清楚,我怎么知道你要什么数据?

数据质量是数据分析、数据科学、甚至是AI的基础,为什么提高不了数据质量?假设先排除搜集端的问题,后续数据清洗是一个非常重要的工作。 普遍情况是,工程师不懂业务、分析师普遍不懂技术,两个团队又容易陷入到第二个陷阱中。

几天后,分析师和工程师团队,总算把例行任务上线了,发现数据库性能上不去,工程师提出方案改成Spark执行,但是分析师不会Spark,又要排期。
04 如何有效的解决囚徒困境

上面只是罗列了一些“囚徒困境”的实际场景,两个团队之间,在需求沟通、数据质量控制、最终数据加工方案上,很容易遇到各种各样的问题。本质上这些问题就是: 技术不懂业务、业务不懂技术,鸡同鸭讲,能讲通吗? 那么我们如何走出来呢?
回到现实条件下,客观的看待阿克塞尔罗德的试验,虽然他指出了走出囚徒困境的解法,但是,这个试验的条件相对简单,而且试验的次数可以是几千几万次,而对于现实工作,我们如何在有限条件下走出囚徒困境,是需要各找各的办法的;另外,也要依托一些先进的产品,想办法降低摩擦,找到双方友善、宽容的合作方案,不陷入囚徒困境。
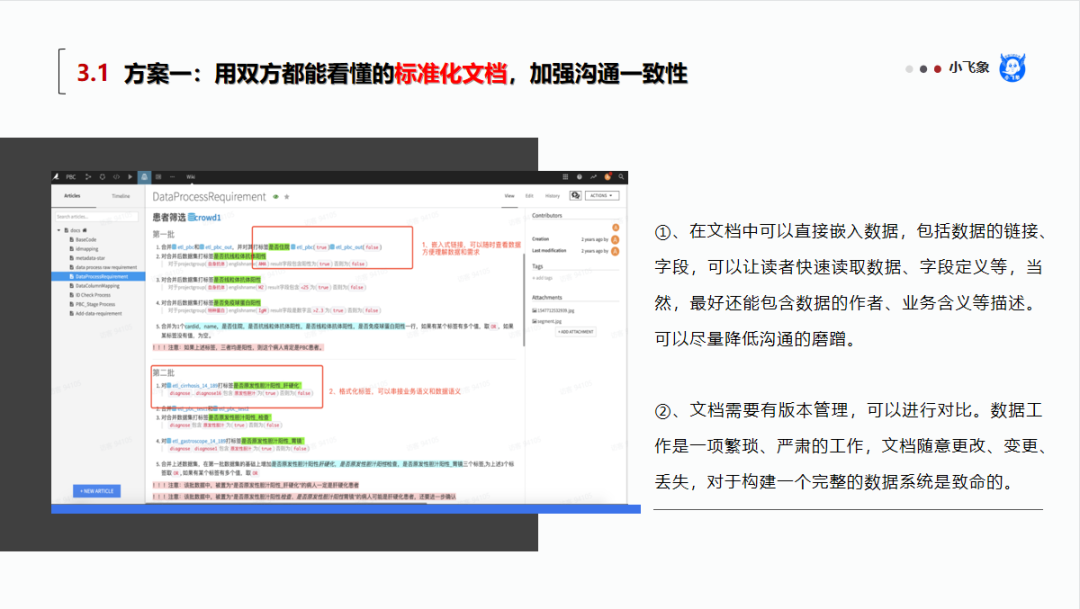
文档,在传播需求,达成共识的过程中,起到非常重要的因素 。在数据产品中,文档是一个不太起眼,但是非常重要的环节。它应该有这样的功能:
1.在文档中可以直接嵌入数据,包括数据的链接、字段,可以让读者快速读取数据、字段定义等,当然,最好还能包含数据的作者、业务含义等描述。可以尽量降低沟通的磨蹭。
2.文档需要有版本管理,可以进行对比。数据工作是一项繁琐、严肃的工作,文档随意更改、变更、丢失,对于构建一个完整的数据系统是致命的。
具体操作如下:
1.数据表统一
分析师和工程人员对表名的叫法统一,甚至可以通过工具可以自动跳转到页面对数据进行查询
2.数据字段统一
数据分析师经常使用中文的明年,比如“客户ID”,但是工程师习惯的是英文命名“CustID”,遵循统一的命名标准是一个很好的习惯
3.注意文档版本
分析师的文档,会随着业务发展产生不同的版本,编辑时间、发布时间、功能描述等,都需要关注版本,双方沟通中要基于同一个版本的数据、文档进行讨论。
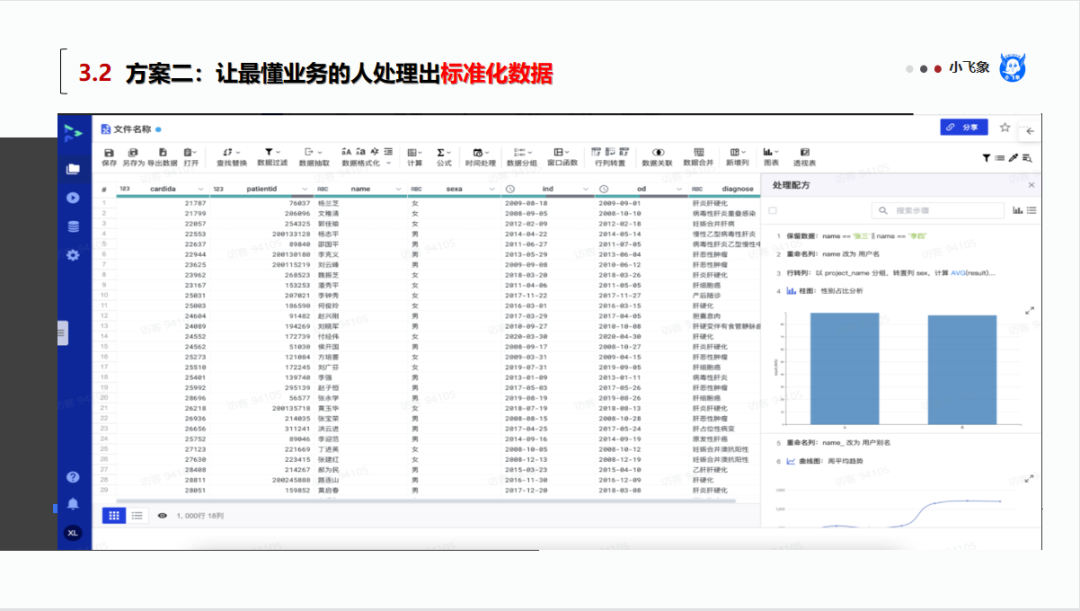
之前在一些群里,看到数据分析师讨论学习哪些技术,比如Spark、SPSS、SAS,我个人觉得这些技术工具值得学,但是更重要的是要从业务的角度入手。
1.数据(商业)分析师的职责,不是和数据工程师抢饭碗,而是帮助老板、企业研究数据,基于数据做决策,因此,更要以业务的视角去理解、使用数据。
2.工程师们,如果只想从事技术工作,需要更好的做好技术性的支撑,例如确保数据系统可靠性、易用性,做好不同系统之间的整合工作。要及时、有效的从搬数据、抽取数据中解放出来。
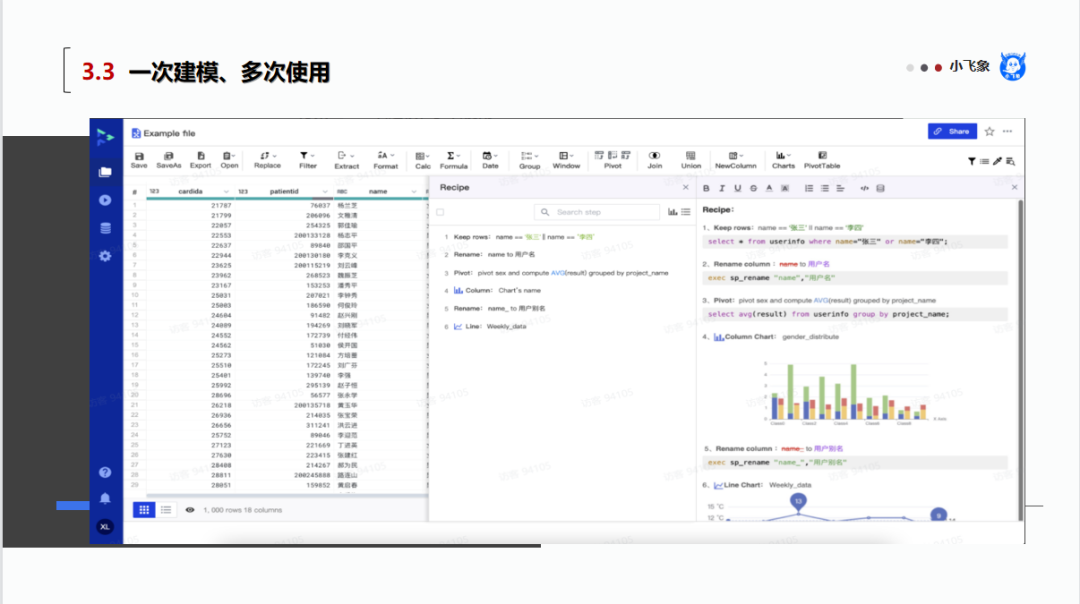
随着技术的发展,基础的数据平台会越来越多,数据分析师不太可能全部学会,更不要说精通。那么,一个业务逻辑,数据(业务)分析师如何让技术团队看懂、翻译自己的工作,就非常有讲究了。但是非要让别人看懂、翻译吗?我们数据分析师团队,能不能直接操作大数据平台呢?
1. 数据加工本身可以被抽象成语义,经过不同的编译过程,理论上就可以翻译成SQL语句、Spark程序等等。数据分析师对数据的整理、建模,尽可能不用工程师帮忙,这样可以尽可能的降低重复劳动、减少工作的误差、浪费。
2. 数据工程师,可以腾出时间去处理数据平台的其他工作,做好不同组件的整合,做好数据加工的性能优化。
05 总结
以上就是本次分享的全部内容!囚徒困境,是一个很让人难堪的境地。我想指出的是,博弈的双方/多方,有很多机会可以避免最差的结果。虽然友善、报复、宽恕等等字眼,属于伦理学的范畴,貌似和现实生活离的很远,但是,其实在日常沟通、协调中,哪怕一点细微的改进,都能体现合作的光辉。
我们不要小看沟通的威力,从某种角度来说,世界是多样性的,是让世界变得丰富多彩的基础。我们可以想办法在多元的世界之间设计出巧妙的沟通桥梁,一定可以产生友善和宽恕的化学反应,进一步促成整体的合作进化。我觉得其实在我的心目中,数据分析和数据工程师可以一起来协作,来去逃脱这种数据的困境,还包括这个深层的这个操作空间,能更好地帮助公司来进行发展决策。
相信大家通过不断的学习和实操,认识到数据分析对企业或者组织的重要意义。 学贵在行,需要我们在以后的学习工作中不断地积累经验掌握工具,学以致用。能站在多方角度,发现问题,分析问题,解决问题,总结问题。
后期小飞象会继续为邀请各业的精英分享数据领域的内容。 祝愿大家都能在自己所在的领域内,用数据思维,成就更好的自己,在可预见的未来,遇到更好的自己 。谢谢大家!
作者:周海鹏
本文由@小飞象-木兮 整理发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议







