站内搜索系列:如何通过产品策略优化搜索排序结果?
编辑导读:搜索是最常见的功能之一,用户通过站内搜索帮助自己快速找到想要的内容来改善用户体验,促进转化率。如何搭建一个高质量的站内搜索引擎呢?本文将从五个方面进行分析,希望对你有帮助。

一、站内搜索的意义
对于媒体内容站、电商、SaaS服务等B端企业来说,增加「站内搜索」功能来帮助自己的用户快速找到心中所想的内容是改善用户体验,降低跳出率,促进用户转化率的最好方法。
另一方面来说,站内搜索也是帮助B端企业快速收集用户真实想法的好工具,用户每一次搜索和点击,都是对自己网站内容的反馈,特别是无结果的搜索词,更是帮助我们改善网站的至关重要的一手资料。
那么如何快速搭建起一个高质量站内搜索引擎呢? 接下来我会写一系列文章来详细讲解站内搜索的方方面面,欢迎大家持续关注。
今天,我们先从产品层面谈谈如何优化搜索排序结果。
二、从初代搜索算法谈起
要想深入理解搜索,要从搜索引擎的起源说起。任何一个复杂系统都是首先从一个简单系统开始,逐渐演化而来的。而一上来就设计一个复杂系统,很难让它良好的运转起来。所以我们必须追根溯源,从源头谈理解搜索。

90年代,TREC(全球文本检索大会)组织了一系列年度研讨会。这次研讨会主要想找到「非结构化长文档」组成的数据集的最优搜索算法。TREC对搜索引擎算法做了非常多的优化,其中TF-IDF算法应该是当时最棒的排序算法的主要组成部分。
TF-IDF算法如它的名字一样,含两个关键要素,「词频TF」与「逆文档频率IDF」。用这两个要素统计加权后获得搜索排序。
- 词频(TF,即Term Frequency)。词频TF是指「搜索词」在一篇文档中出现的频次。
- 逆文档频率(IDF,即Inverse Document Frequency)。逆文档频率IDF是指「搜索词」在整个语料库中的频次。
当用户键入一个「搜索词」后,首先比对整个文档库中哪些文档中包含的「搜索词」最多。包含的越多,这篇文档排名就越高。
这个简单的规则有一个致命的问题,我们的语言中有非常多的连词,代词,助词等只是用于辅助句子表达的词。比如「吗」、「也」、「这个」、「可是」这样的词,这些词并非文档的核心内容,应该降低权重处理。
此时,我们引入第二个关键要素——逆文档频率IDF。它的作用是降低语料库中出现频次多的词的权重。一个词在语料库中重复出现的次数越多,包含这个「搜索词」的文档的排名就越低。
TF-IDF的设计是不是简单又巧妙,TF-IDF排序算法以及类似的比如BM25算法基本上就是古早搜索引擎的查询和排序核心算法。这类算法主要针对非结构性长文本而设计,比如大型企业文档,历年判案文书,全球论文检索库等设计。
这类算法是搜索引擎的基石,很好的理解它们的原理,有助于我们设计自己的站内搜索。接下来,我们谈谈针对独立站、小程序、APP应用内搜索搜索问题应该怎么设计和处理。
三、如何通过数据属性来优化排序结果
今天咱们不谈搜索技术问题,只谈站内搜索的产品设计问题。
站内搜索技术的问题其实已经被解决的很好了,开源免费的有ElasticSearch,国内SaaS形式的站内搜索解决方案也有很多,比如卡拉搜索 KalaSearch.com ,一行代码即可部署站内搜索,非常方便。 在搜索技术不是大问题的前提下,剩下比拼的就是产品策略和产品设计。接下来,我们从产品设计层面谈谈如何优化搜索排序。
这种算法的问题是它只能针对极少数场景设计,并不适合当下互联网中网站、小程序、app里的信息搜索。这种搜索会把所有文档不分类型的混排在一起,而我们现在的数据信息包含非常多的纬度,甚至有些用户行为投票的社交指标包含在其中,比如(浏览量、点赞数、转发数等)。
如何利用多维度数据提升搜索准确度是我们要思考的问题。
前文我们提到TF-IDF类搜索算法的原理,那么接下来应该添加些什么元素使搜索引擎排序准确性上更进一步呢?我们网站/小程序/APP中的文档信息其实并不是混排在一起的,而是包含非常多纬度的信息,甚至有一些纬度是用户行为产生的对文档质量的投票,比如浏览量,点赞数,转发数,收藏数等。如何利用这么多丰富的多维度信息来帮助我们优化搜索呢?
一般我们可以把站内文档信息分成这么几个纬度。
- 搜索属性:标题、正文、标签、文章描述、图片描述、评论内容等。这些属性可以作为搜索的基础属性放入我们的站内搜索中。
- 人气指标:点赞,转发,评论,评论的点赞,收藏,关注等通过用户的行为产生的人气指标。这些指标可以辅助我们判断一篇文档的内容优质程度。
- 站长策略:作为管理员,有时候会有根据自己站的情况,手动调整的一些内容。可以调整这些内容的在搜索结果中的排序权重。
我们来举个例子。假设用户最近看了威尔·史密斯的经典电影《当幸福来敲门》,很喜欢。第二天打算去豆瓣上看看影评,但昨天看的是“幸福”什么来着?用户只记得电影名里有个幸福,于是在豆瓣电影的搜索框输入“幸福”。
请思考一下这时候用户的心理状态。他肯定不关心到底有多少含有“幸福”这个词的电影名(TF词频),肯定也不关心“幸福”这个词到底是不是电影名的常见词(逆文档频率IDF)。
这位用户更关心的是怎么快速准确找到昨天看的那部叫什么“幸福”的电影,赶紧看影评。
这时候,我们的搜索引擎应该把什么排在联想词列表的第一位呢?

虽然《当幸福来敲门》中的「幸福」这个词并非在属性的第一个,但因为这个电影名本身权重高,所以被排在第一名。
在这个场景的搜索中,「幸福」这个词,有很多属性可供我们的搜索引擎用来做排序判断。
- 「幸福」这个词在“演员姓名”属性中,还是在“片名”中?
- 「幸福」的拼写是否正确?有错别字,同音字、相似形状的字或者南方无法分清前后鼻音的用户输入的词,比如「新福」?
- 「幸福」这个词在属性中是第一个词吗?还是当中的一个词。
- 含「幸福」的属性中有多少用户行为投票数?比如:看过/想看/影评/以及简评等。
- 含「幸福」的属性包含在外部榜单中吗?比如奥斯卡奖,金球奖等。
- 含「幸福」的属性是不是在豆瓣电影自己的站长策略中?豆瓣250电影榜等。
以上这些属性在数值加权后,把「当幸福来敲门」排在搜索结果最前面的可能性,肯定比使用TF-IDF排序算法找到「当幸福来敲门」的可能性大得多。
所以,我们应该要把网站业务的各种属性考虑到排序结果之中,并根据不同属性的重要程度来设计权重。我们可以从以下几个方面来考虑排序问题。
- 词语匹配:如果用户输入多个词,那么与用户输入的搜索词匹配度最高的结果,肯定是排在最前面的。
- 相近度:词与词彼此靠近,排序更靠前( 搜「海底捞」,那么「海底捞自热火锅」应该比「海底的捞网」排名靠前 )。
- 业务属性权重:比如刚刚豆瓣电影的例子,在这里搜索的用户首先想找的一定是电影,其次才是电影人。比如搜「史密斯」排在第一的大概率是「史密斯夫妇」(电影名),而不应该是「威尔·史密斯」(电影人)。
- 搜索词所属位置:处于重要属性中的词,排名会更高。比如标题或描述里包含了搜索词的文档,排名肯定高于只有正文才有搜索词的文档。
- 精确性:完全匹配的精准词,没有任何前缀和后缀的,会排在最前面。
- 错别字:有错别字的文档被认为是文档质量低的表现之一,它不应该比没有错别字的文档排的更高。

豆瓣电影输入「史密斯」前面三位是电影,后三位是电影人,这是根据产品业务权重的搜索排序策略。
站内搜索加上这些排序策略后,比经典的搜索算法排序在搜索准确度上有了非常大的飞跃。那么,我们要怎么继续提升排序质量呢?
接下来我们来聊聊如何灵活运用这些搜索策略来进一步改善搜索排序结果。
四、如何通过调整数据属性的排序来优化搜索结果
现在的各种站内搜索解决方案,之所以搜索结果准确度低,问题并非出在搜索算法上。因为网站/APP再大、情况再复杂,规则也是可以穷尽的。这和全网搜索的难度相比,难度上低了无数个数量级。
那么问题出在什么地方呢?问题出在没有或很难灵活运用搜索策略上。
如果我们用ElasticSearch搭站内搜索,那么从“搭建”到“能用”其实很简单,但从“能用”到“好用”就得好几个工程师+无数时间积累才行。这不是一般中小公司能够承受的成本开支,大多数中小公司会停留在凑合能用的状态上。
特别基本搜索算法选择使用一个大的浮点分数,把所有东西混在一起。给每一份文档根据所有规则加权获得一个分数。然后根据这个规则来排序。这种方法有个有一个致命的问题,就是把完全不是一码事的属性混在一起谈排序。
举个例子。假设排序方案包含TF-IDF及点赞数这两个纬度。那么问题来了,我们的搜索引擎会怎么排序?
如果某个文档的点赞数非常高,会怎么排序?这个文档会排在非常靠前,即便文档与搜索词的相关度非常之低也会被排在很靠前。
那么如果某个文档与搜索词相关度非常高,但点赞数为0,又会怎么排序呢? 这篇点赞为0的文章很可能都不会出现在排序结果中。
这种混合搜索排序方法的另一个问题是它的复杂性。当多个纬度的属性被混在一个公式里,我们发现搜索结果很糟糕时,也不知道应该怎么调整。
那么,面对这种多个纬度的搜索问题,我们应该如何设计搜索排序呢?
聪明的办法是把所有属性拆开来看,针对自己的业务调整他们的顺序即可。不把所有属性混在一起计算大分数,而是计算N个分数,并进行N次连续排序。
接下来我来讲讲它的工作原理。
所有匹配结果按照第一条标准进行排序,如果有结果得分并列,则继续根据第二条标准计算得分并排序。如果仍有并列,那么就继续执行第三条标准,直到搜索结果中每一条都有自己的位置。
那么流程中先用哪条标准来进行判断,成为这个排序方案的关键。
来个案例,你就明白了。
[
{
“title”: “为什么《黑肯帝国3》在IDBM才不到7分?”,
“featured”: true,
“number_of_likes”: 2647
},
{
“title”: “《黑客帝国》里面,为什么最后是尼欧赢了?”,
“featured”: false,
“number_of_likes”: 3077
},
{
“title”: “还好当年没让小李子演《黑客帝国》”,
“featured”: false,
“number_of_likes”: 531
},
{
“title”: “多年以后,才真正看懂黑各帝国”,
“featured”: false,
“number_of_likes”: 797
},
{
“title”: “如何理解《黑客帝国》?”,
“featured”: true,
“number_of_likes”: 611
}
]
为了简化例子,我们把规则简化成三点,错别字,加精,点赞数这三个指标上。
用户输入「黑客帝国」这个关键词进行查询,他会得到如下结果。
- 如何理解《黑客帝国》? (无错别字; 已加精; 点赞数:611)
- 《黑客帝国》里面,为什么最后是尼欧赢了? (无错别字; 未加精; 点赞数:3077)
- 为什么《黑肯帝国3》在IDBM才不到7分?(2个错别字; 已加精; 点赞数:2647 )
- 还好当年没让小李子演《黑客帝国》(无错别字; 未加精; 点赞数:531)
- 多年以后,才真正看懂黑各帝国(1个错别字; 未加精;点赞数:797)
给予精华更高权重。精华一般是网站管理员手动添加的,是管理员根据当下情况判别的。这种精华标记,通常情况下应该大于用户投票行为的指标(比如点赞数)。
错别字是判断文档重要程度的一个纬度,如果文档中有错别字,有一定概率说明文档的质量有些问题,在排序上应该降低权重。
我们将用户投票行为放在关键词相关性之后(有时候点赞数甚至是不可信的,针对搜索引擎作弊行为最先想到的就是刷点赞数。所以搜索引擎能自定义更多纬度的判别属性,是他是否在细节上能足够精准的关键,这个问题有机会单开一篇讲)。
以上是这个案例的策略,如果我们对这个例子的排序结果不满意怎么办?只需要调整属性权重(顺序)即可。比如我们觉得错别字没什么问题,不应该降权太多,那只需要把「错别字」这个属性放到后面即可。
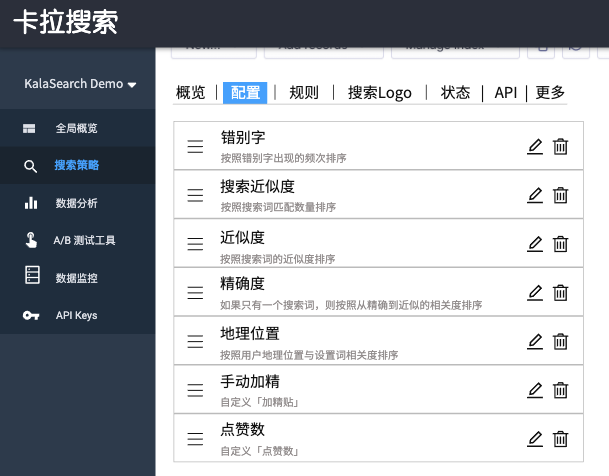
国内站内搜索解决方案「卡拉搜索」策略设置后台,只需要用鼠标拖动就可以改变属性权重。
五、站内搜索优化总结
对于媒体内容站、电商、SaaS服务等B端企业来说,增加「站内搜索」功能来帮助自己的用户快速找到心中所想的内容是改善用户体验,降低跳出率,促进用户转化率的最好方法。
另一方面来说,站内搜索也是帮助B端企业快速收集用户真实想法的好工具,用户每一次搜索和点击,都是对自己网站内容的反馈,特别是无结果的搜索词,更是帮助我们改善网站的至关重要的一手资料。
- 对于媒体内容站、电商、SaaS服务等B端企业来说,增加「站内搜索」是降低跳出率,促进转化率的最好方法。
- 「站内搜索」是帮助站长理解自己用户心中所想最好的工具,特别是收集无搜索结果的搜索词,有助于更好的改进网站内容。
- 「站内搜索」不需要使用系数或任何形式的加权平均值方式来判别排序权重。使用复杂的公式不如使用产品策略来调整搜索结果。
- 添加更多纬度的数据给搜索引擎,让他能更好的识别并根据这些指标来排序。
搭建「站内搜索」其实很简单,国内比较好的站内搜索SaaS只需要一行代码即可部署,我将在下一篇文章中讲解如何快速部署站内搜索。欢迎留言提问,下一篇一并解答。
本文由 @卡拉先生 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。