大数据/反作弊/圈层化——在线问卷市场的竞争与进化
在数据导向成为下半场常态后,主打调研功能的在线问卷市场将再起波澜。

人口红利见顶后,国内互联网行业的发展抓手逐渐从消费端转向产业端。无论是进入存量竞争的前者,还是强调垂直方案的后者,都将进一步狠抓用户数据的精准性。
从底层逻辑来看,互联网行业正在经历一个从流量思维向用户思维转变的过程。一方面付诸组织能力,以更高的运营效率压死对手;另一方面,发掘用户需求,不断以时间窗口开辟新战场。
随着增长逻辑的转变,在线问卷也将随之进入下半场。
01 转型中的在线问卷
在今年以前,在线问卷赛道可以说一直保持着风平浪静。放眼全球,有在线调查三巨头:SurveyMonkey、Qualtrics、Confirmit;国内则处于问卷星、问卷网、腾讯问卷三分天下,麦客、表单大师、金数据、番茄表单等瞄准细分市场的战国格局。
但在线问卷市场正在起变化。
先是问卷网于 6 月 22 日宣布完成由方广资本、元禾控股、中亿明源,三家联合投资 1.4 亿元人民币 C 轮融资;随后,猎聘又于 8 月 26 日宣布战略投资去年寻求融资失败的问卷星,8.2696 亿元,持股 66.6%。
从两笔交易中不难嗅到未知的气息:问卷网的上一次的融资,还要追溯到 2015 年初的 550 美元 B 轮;而最早进入在线问卷赛道的问卷星,哪怕号称手握 4000 万用户也难逃卖身的命运。
正如 SurveyMonkey、Qualtrics、Confirmit 三巨头早已定位为“服务供应商”,而非单纯的工具平台。国内在线问卷也正在兴起从工具属性向服务属性的转型升级。
而对于在线问卷产品,样本库不仅将成为向服务供应商转型的抓手,更会成为洗牌并最终决出胜负的关键。在我们看来原因无非三点:圈层化的需求、B端市场的需求以及对于黑产的应对。
02 符合圈层需求很重要
在那本《圈层效应》中,哈佛客座教授托马斯·科洛波洛斯提出了“圈层效应”的说法。它由“Z世代效应”延伸而来,源自于社会从 95后一代诞生开始,逐渐出现了技术“隐形化”加深的趋势。以往的圈层边界逐渐消失,不同年龄、教育背景、社会阶层的人,都可以通过同一种技术消费同样的内容,独立个体也更容易被聚拢起来。
消费趋势也随着圈层化的不断深入发生了变化。
最好的例子是过去几年日化巨头宝洁的失速。数据显示,其 2006 财年全年销售额为 682 亿美元;而到了 2017 财年其销售额反而下跌到了 651 亿美元。
核心原因便在于宝洁所面对的消费者(样本)产生了变化。
宝洁定位大众,但信息传递的进一步碎片化、社交化,使得大众分化为特征更为鲜明的圈层,小众品牌凭借独特气质、特殊功能有机会赢得消费者心智。
如果企业无法与圈层内部沟通,其便会面对转化低、变现难的窘境。反映到调研中,则是分层抽样的“粒度”进一步缩小。
所以,在当下的市场调研中,样本库必须满足两大要求:其一,样本量;其二,垂直度。我们不妨以此为脉络横向对比三家产品。
问卷星
作为国内最早的在线问卷平台,问卷星样本库最大的特点是来源随机,其目前主要来源是用户口碑推荐、在线用户随机邀请、以及填写过问卷并且自愿接收邀请继续填写的用户。
优势:样本量大,可指定多种要求;
样本量方面,问卷星凭借拥有 260W 样本库成员,平均每天超过 100W 人在问卷星平台上填写问卷有一定优势。其投放时可具体到性别、地区、年龄、学历、工作经验、行业、职位、收入状况等多个维度,能为有精准投放需求的客户提供支持。
劣势:垂直度不足,圈层覆盖狭窄;
问卷星通过在线考试功能在校园市场方面培育了大量用户,后续被猎聘收入囊中算是延续其向企业用户转型的路线。但从问卷星到猎聘,本质是将样本来源从“在线问卷用户”,拓展到了“HR用户”,在样本覆盖上依然较为单一,全面性不足。

问卷网
脱胎于爱调研旗下 iSurveylink 系统的问卷网,主要样本由 2008 成立的在线任务参与平台爱调研提供,此外还在今年 1 月相继牵手华为、今日头条,由后者提供持续的技术与数据服务。
优势:样本结构更合理;
相对于问卷星与猎聘的组合,问卷网一方面有稳定的、相对素质更高的样本;另一方面,有第三方丰富样本人群,使其样本结构相对更全面。
劣势:样本量存在天花板,成本高;
问卷网样本主要由在爱调研社区参与任务,赚取奖励的用户组成,其全面性由第三方提供。这意味着其需要投入更高成本保证样本的稳定,价格也会被进一步抬高。
腾讯问卷
作为后起之秀,腾讯问卷优势在于腾讯已经在社交市场已经成为基础设施,无论是获取用户、上手门槛,还是后续占领用户心智都有着较强的品牌优势。
优势:免费、自然分布的样本结构
腾讯社交能触及几乎所有网民,这使得腾讯问卷的样本库不仅贴近中国网民,且在各个圈层覆盖较全面,实现了 20 多个细分维度筛选,在丰富不同属性的样本时,腾讯问卷的边际成本会更低。
而问卷星、问卷网的收费方式是按照属性收费,这意味着你希望圈定越精准的群体,问卷的成本便越高。
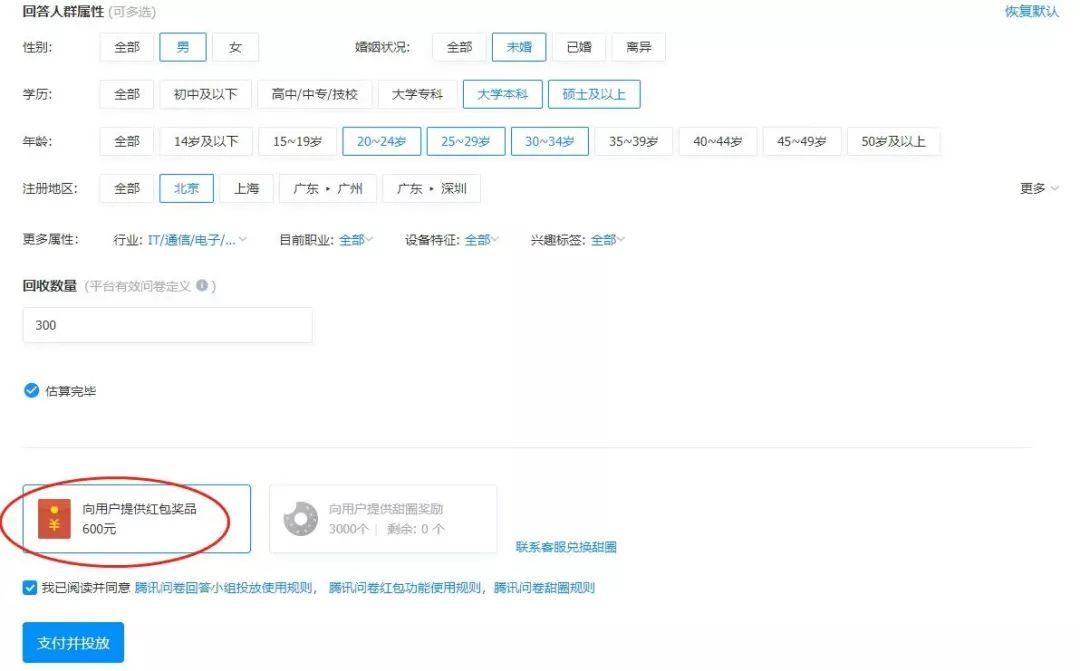
比如我这份问卷,圈定在男、未婚、大学本科及硕士以上学历、20~34岁、北京、IT/互联网行业六个维度,在问卷星就已经需要在基础价格上增加 10 元/份

在问卷网上,上文提到的成本高非常明显。属性还没选完的情况下,估价就已经高达 18 元/份:
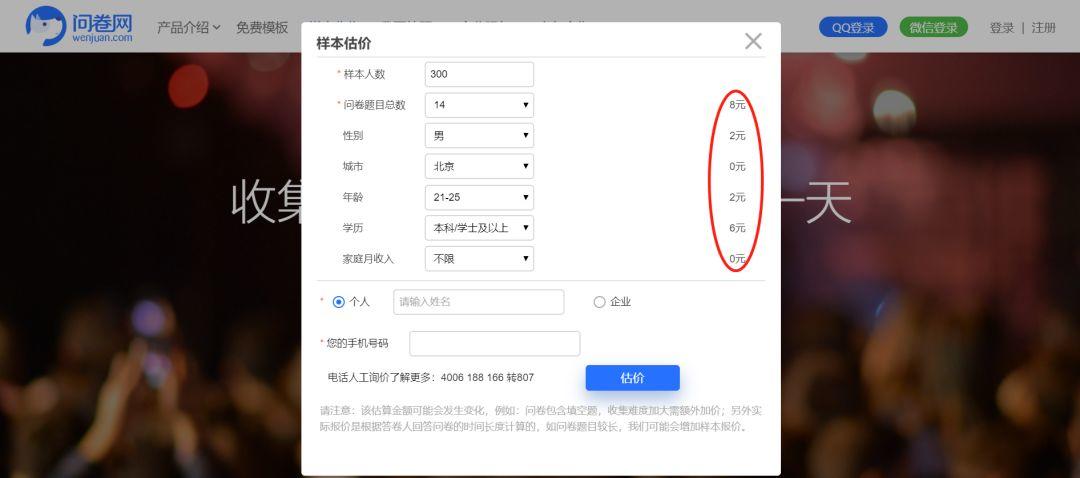
腾讯问卷则是以题目数量评估费用。同一份问卷,无论是对样本完全没有要求的基础价格,还是圈定在男、未婚、大学本科及硕士以上学历、20~34岁、北京、IT/互联网行业六个维度,价格都只需要 600 元,也就是每份仅需 2 元。
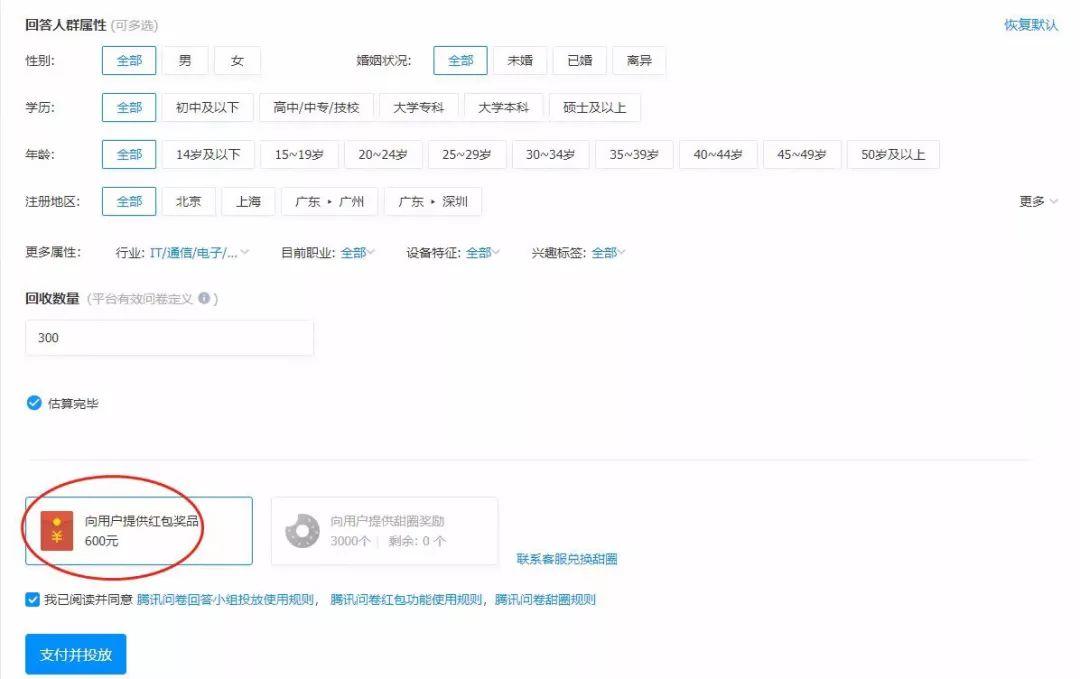
而值得注意的是,问卷星、问卷网的重要收入来源之一便是样本库,所以投放者将样本服务费用给到平台,后者会抽成后再给到答题者;
但腾讯问卷则“没有中间商赚差价”,投放者的红包和甜圈(回答小组的专属奖励)将全部发放给合格回答者。
劣势:样本量较小
不过目前来说,作为后起之秀的腾讯问卷样本量仅为 100 余万,相较于问卷星与问卷网存在劣势,目前以主动报名加入为主。

但其为样本群体都给出了清晰的利益点,比如在校学生能获得相对更高的奖励,企业管理者能优先获得腾讯问卷的行业报告,自由职业者则亲自参与产品优化与迭代。
03 更完备的安全机制
“吃黑巧克力减肥”其实是一个彻头彻尾的谎言。
起因是两位德国电视记者发现,有不少减肥食品公司会雇用专家“带货”。于是,他们便与《科学》杂志撰稿人与博安农合作,动手成立了“垃圾膳食研究”。
他们将 15 个志愿者分为三组。其中对照组维持正常饮食,实验组 1 实行低碳水饮食,实验组 2 也实行低碳水饮食,并每天加一条黑巧克力。
他们凭空造出了实验数据:对照组体重不变,实验组体重都轻了 5 磅,且使用黑巧克力的一组速度快了10%。不仅其投稿了 20 家期刊并被大量发表,媒体们也纷纷报道。其中,欧洲发行量最大的报纸《德国图片报》最先上当,随后爱尔兰、美国、澳大利亚等众多媒体纷纷报道。
为什么能骗过期刊和媒体?
因为他们利用了统计学的小把戏:针对小样本测量大数据,几乎一定得到“统计上显著”的结果。他们在 15 个对象身上,测试了多达 18 项数据。
在数据导向的下半场,快速迭代、灰度测试等手段被更加重视。这意味着以往小样本、多维度的调研将极大限制产品团队后续的调整与研发。
解决之道在于,为其赋予大样本调研的能力。随之而来的是两个必须跨越的门槛:其一,更强的承载能力;其二,更强的反作弊能力。
前者源于,更加短、平、快的开发节奏,意味着市场的调研需求有着总量大、高并发的特点。比如,小米路由器智能硬件部总经理唐沐就曾在评价腾讯问卷时表示:“事实证明百万的问卷数据承载毫无压力”
这某种程度上成为了,依靠学术研究、中小企业起家,承载量普遍不过数万级别的问卷星、问卷网们深挖 B端市场所面临的困境。
更强的反作弊能力,反映在调研结果将远超人工审核的控制能力。如果数据遭到污染,则可能导致产品策略出现偏差。调研领域,以“信度”衡量调研的可靠程度,指采取同样的方法对同一对象重复进行测量时,其所得结果一致程度。
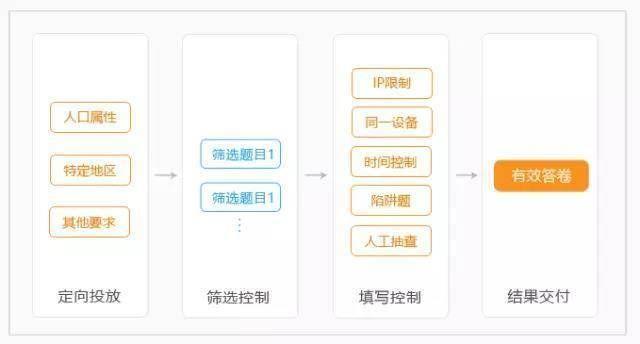
问卷星强调“严格按照有效样本来计价”。
简单来说,问卷星的样本控制有 4 个环节。首先依照客户需求定向投放给回答者,通过筛选题目筛出复核要求的样本,再通过 IP限制、同一设备识别等机制限制羊毛党等污染数据,最终以有效样本计价。
但只要有利益的地方就少不了羊毛党。
在知乎上便有大量数据被羊毛党污染的案例。其中一位便是,在问卷星投放的问卷被恶意刷走了 3000+份问卷,拿走了 3500+ 元红包,峰值时每分钟提交多达 300 份,哪怕设置了单台设备只能提交一次也没能奏效。
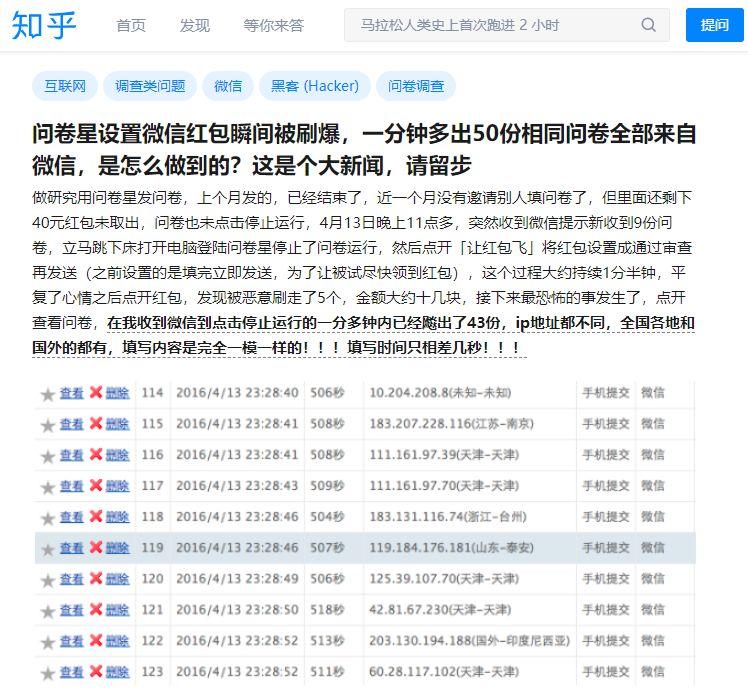
不难看出,一旦问卷投放回收的总量过大、时间过紧,就很难避免被恶意刷走奖励。
显然,在数据精度需求不断提升,调研逐渐密集的的下半场,传统质量控制机制已经力不从心。
这一方面,问卷网也暂未提出更先进的方法,主要还是依靠筛选去除答题时间过短的问卷、为问卷链接增加追踪参数,监控用户是否认真答题。

腾讯问卷的解决方案则是试图以 AI 技术作为第二道保险。
一方面,腾讯问卷正在开发自动识别标记无效问卷(胡乱作答、伪装作答)程序。通过跟踪用户全程答题行为时间分布,结合 AI 技术依靠用户行为序列进行筛选,以此保证回收问卷的有效性,提高样本的质量。
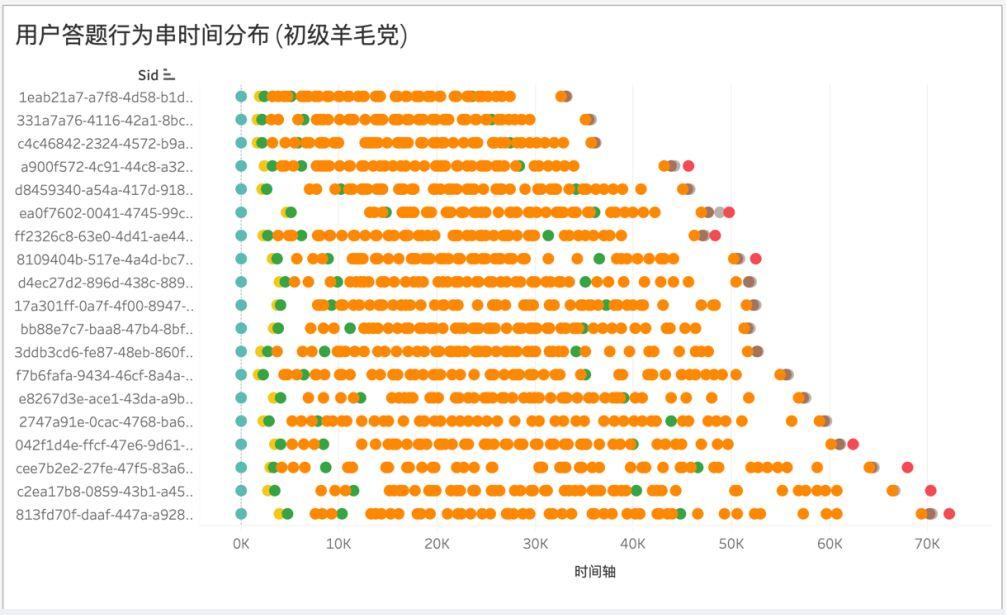
另一方面,建立回答小组成员的信用机制,通过对一个成员多次答题行为的合并计算,判断成员的信用情况,把不诚信和虚假用户逐渐清洗出回答小组。
04 更高的问卷效率
以揭露销售员、专家、记者或者广告撰稿人以调研结果“行骗”,而畅销全球 60 余年的统计学普及著作《统计数字会撒谎》中,作者列出了日常统计中最常见的 8 中误导方式,其首先便从 1949 年的一篇报道说起。
报道显示:“1924级的耶鲁毕业生,平均年收入为25111美元。”这在当时可谓是不菲的收入,自然会营造一种将孩子送进耶鲁走上人生巅峰的感觉。
但事实是,25 年后,能取得联系已然只是小部分人,而这其中许多人更不会如实回答涉及隐私的问卷,这一统计的样本自然是有偏向性的。
这反映出,调研很难在效率与质量之间取得平衡。要保证样本多样性,回收效率往往难以保证,就像上文提到的耶鲁毕业生,触达成本极高;而如果要保证高回收效率,必然要长期维持较大的样本库,这势必导样本质量被影响,比如互答社区等模式。
另一个例子可以从侧面说明,高效率对于质量的巨大影响。
中国社会学奠基人费孝通的著作《江村经济》诞生后,开弦弓村摇身一变成了田野调查圣地。在多年来吸引了大批中外社会学人、媒体、机构团队、学生组织前往朝圣的影响下,当地人早已有熟练应对。“江村”也再未诞生有影响力的社会学作品。
对于数据导向的下半场而言,势必需要解决触达效率与成本的桎梏。
问卷星与问卷网走的是传统路线。
两家都开发了 App,但重点都放在了问卷的创建与管理,触达样本库的回答者依旧采用短信、邮件等方式,相对较为低效。
腾讯问卷则走的是基于社交的高粘性路线。
腾讯问卷的样本库通过组建“卷叔填填圈”公众号作为接收问卷任务和奖励的渠道,简化了投递与回收的路径,形成了更高效的放者和回答者的连接。
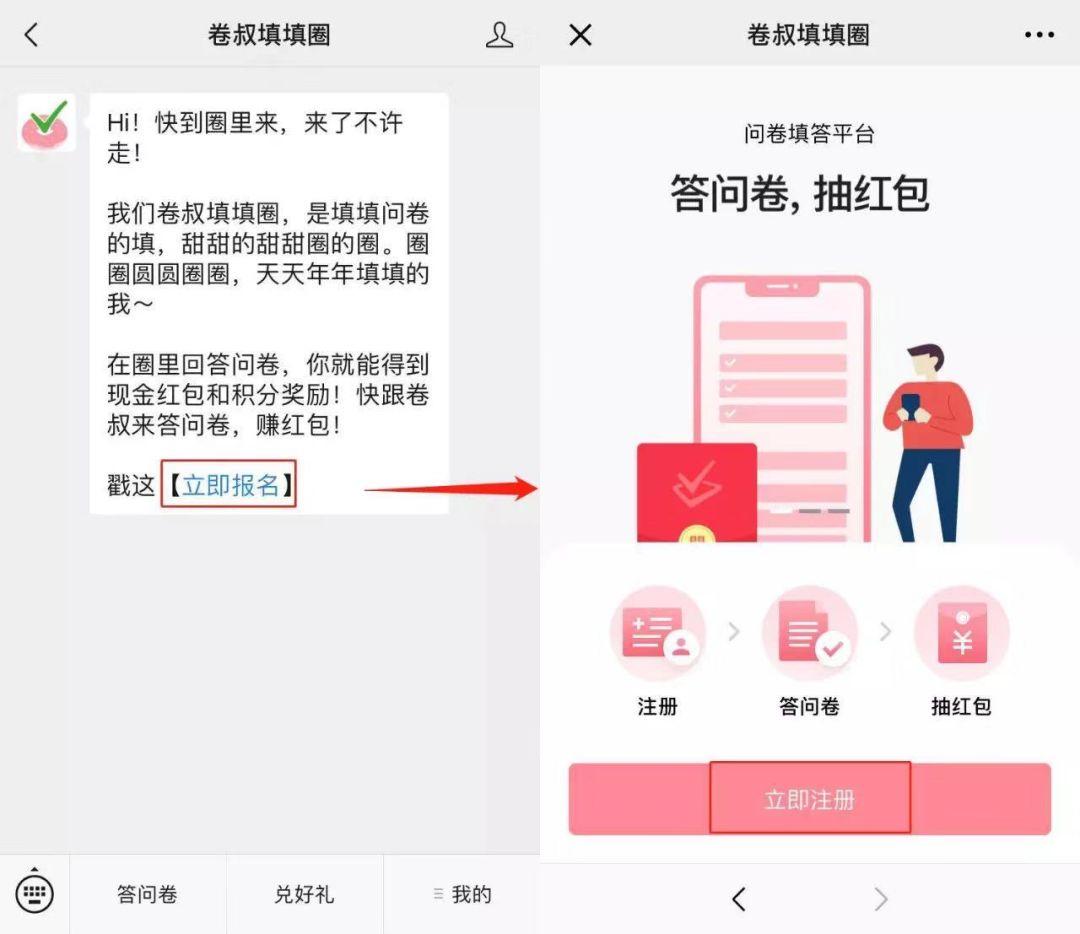
在提交了详细的个人信息注册成功后,每当有符合标准的问卷,样本库的回答者都会在第一时间收到“卷叔填填圈”服务号的微信推送:
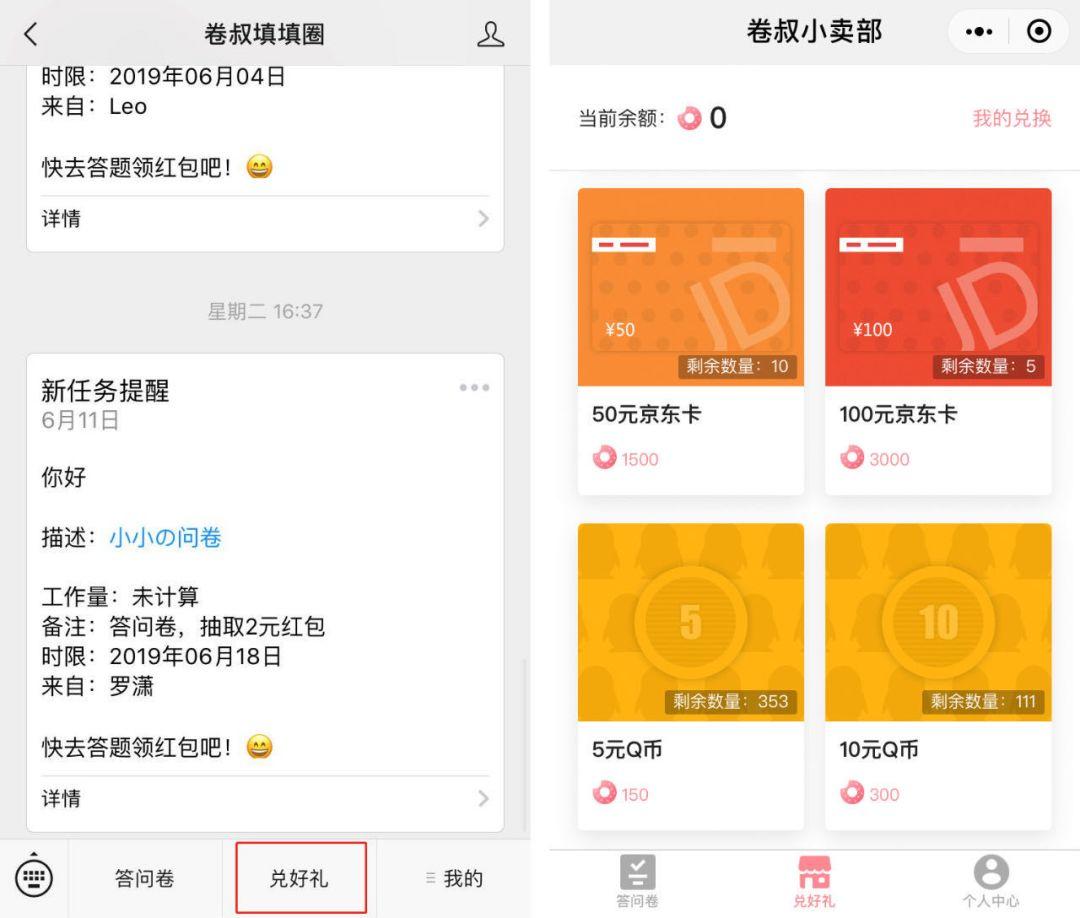
这一机制下,不仅问卷回收效率有不小的提升,腾讯问卷还通过定期发布的红包奖励、填圈排行榜,在样本库回答者中形成了激励机制,反过来形成良性循环。
值得一说的是这个“填填圈”。因为微信红包“没有中间商赚差价”,所以无法提供报销发票,导致公司项目的调查经费较难直接使用和报销。
所以,腾讯问卷还增加了甜圈投放方式,答题者可以使用甜圈兑换礼品,为投放和回答者双方提供了便利。
05 最后
正如开头所说,在数据导向成为下半场常态后,调研必然将更广泛地介入各个生产环节。对于投放者而言,在相同调研预算下,更精准的、更大的样本量,更高的回收效率,以及更纯净的数据,都无疑会成为选择在线问卷产品的金线。反过来,这也将会推动逐渐不再平静的在线问卷市场再起波澜。
作者:科技唆麻;公众号:科技唆麻(ID:techsuoma),科技唆麻,不飞不快。
本文由 @科技唆麻 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0






