通过文本挖掘,我们发现了国家公务员考试的这些秘密
笔者以一个旁观者的视角,通过一些语义分析技术去发现近八年(2011~2018)国考行政职业能力测验(以下简称“行测”)考了哪些内容,看能否有一些规律性的发现。

据中国新闻网报道,2020年度中央机关及其直属机构公务员招考笔试有超143万人报名,涉及中央和国家机关86个单位、23个直属机构,而计划招录2.4万人,通过资格审查人数与录用计划数之比约为60:1,在报名期间出现多个竞争超“千里挑一”的职位也就不足为奇了。
虽然笔者没参加过国家公务员考试(以下简称“国考”),但本着“内行看门道,外行看热闹”的心态,笔者想一个旁观者的视角, 通过一些语义分析技术去发现近八年(2011~2018)国考行政职业能力测验(以下简称“行测”)考了哪些内容,看能否有一些规律性的发现。
数据来源
为保证分析的时效性,笔者仅搜集了2011-2018这八年的国考行测试题(将地市级和副省级试题进行合并),仅提取文本中的题干部分,不包含选项。
为了能直观的了解这8年的考题讲了啥,笔者首先从整体上提取其中的关键词。
“行程计算”类考题是重轴戏
以下是经过关键词提取得到的TOP150关键词的词云分布图,其中词汇大小反映的是词汇的重要性程度。

从上图中可以直观的看到, “速度”一词在近8年的国考试题中出现频率较高,说明“行程问题”在国考的试题类型中占较高比重 ,从如下示例中可以看出:
- 小王步行的速度比跑步慢50%,跑步的速度比骑车慢50%。如果他…问小王跑步从A城到B城需要多少分钟
- 甲、乙两人计划从A地步行去B地,乙早上7︰00出发,匀速步行前往,…,为了追上乙,甲决定跑步前进,跑步的速度是乙步行速度的2.5倍,但每跑半小时都需要休息半小时,那么甲什么时候才能追上乙
- 如右图所示,甲乙两人从A、B两点同时出发,朝不同方向沿小路散步,已知甲的速度是乙的2倍。问以下哪个坐标图能准确描述两人之间的直线距离与时间的关系
权重较高的还有“数量”、“里程”、“价格”等关键词,也都反映出国考行测中的计算类型考题较多, 国考行测中的数学运算部分,整体难度不大,通常用普通方法都是可以得到答案的。但相对而言,速度比较慢,而借用一些良好的技巧,则可以快速的得到答案。
此外,近些年公务员考试中计算问题考侧重考查考生对常见方法技巧的理解、掌握与灵活运用。常用的方法有凑整法、尾数法、分组或消去法公式法和估算法。
小贴士:
上述关键词的提取主要考虑以下4个重要因素:
- 词频:一般词汇出现的次数越多,它的重要程度越高;
- 位置:句首、句中还是句末,一般来说,句中的词汇权重会高一些;
- 词性:名词、动词);
- 词长:词汇的长度,一般来说,词汇的长度越长,好汉的语义信息越丰富,给的权重也更高一些。
尽管上面的关键词云图能抓住主要词汇,但是各词汇之间的关联性被忽略了,孤立的对某些关键词进行解读有时很难发现一些有意义的洞察。
那么,有没有一种方法能够既捕捉到关键信息(即发掘关键词),又能直观的反映出词汇之间的关联性?
答案是有的。
通过词汇关联图挖掘试题侧重点
词汇关联图是上述关键词云图的拓展和延伸 ,增加了语境这一维度,也就是将经常出现在同一个上下文的词汇的关联性表达出来。
基于自动聚类形成的词汇关联图,能自然的反映试题题干文本中的语义特征和潜在结构,由此能准确且清晰的知晓近八年国考行测的出题侧重点。
对于生成的可视化结果,可以这样解读:字体大小表示词汇的权重值大小,原理同上,能反映词汇在评论中的重要性,不同的颜色代表不同的话题。
词汇之间距离越近,说明它们在同一语境中出现的频率较高,越具有语义相关性, 比如“速度”、“执法船”、“行驶”、“小时”和“骑车”等词汇挨得很近,我们能迅速联想这些关键词跟试题中的“行程问题”有关,而不是跟政治、物理或者汽车有关。
下图是自动聚类出来的结果,自动聚为8个主题(点击下方图片可查看高清大图):

上图中,按照词汇及其簇群的重要性程度(字体大小、主题词数量)甄选出有意义的主题,根据其中的关键词可以推测这八年国考行测的4个热门考点,依次是:
- 行程类: 这类题一般涉及到路程、速度、时间三者的变化关系,主要反映在紫色系的词汇簇群中,从“速度”、“行驶”、“距离”、“骑车”等词汇可以看出;
- 生物医学常识类: 这类题主要考察应试者对于生物和医学相关常识的知识覆盖面,主要反映在深蓝色的词汇簇群中,从“抽搐”、“浮游植物”、“悬浮质”、“海水”等词汇可以看出;
- 财政学类: 这类题主要考察应试者在宏观经济相关指标的简单计算能力,主要反映在土黄色的词汇簇群中,从“交易规模”、“总额”、“水产品”、“同比增长”等词汇可以看出;
- 场景计算类: 这类题从应试者的生活、工作场景出发,考察应试者的基本计算能力,主要反映在青绿色和宝石蓝两个词汇簇群中,从“培训”、“部门”、“单位”、“平均年龄”、“概率”、“定价”和“余额”等词汇可以看出。
以上4类是笔者能够直观看出来的,其他的类别可能有过国考经历的小伙伴能识别出来,欢迎大家在留言区发言告诉我~
小贴士:
此处的词汇关联图基于HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)实现。相较于传统的聚类算法(K-means、Spectral clustering、Agglomerative clustering、DBSCAN等),它有如下3大优良特性:
- 不需要设定聚类数,有算法自动算出来簇群数
- 可以较好的处理数据中的噪音
- 可以找到基于不同密度的簇(与DBSCAN不同),并且对参数的选择更加鲁棒(Robust,模型更加健壮)
最后,笔者还想看看历年的国考行测考题是否存在较大变动,可以将其抽象为一个文本挖掘任务——度量历年国考行测试题之间的相似度,这可以通过 对应分析 实现。
近八年各年份试题的相似度度量
按照上述提取关键词的方法,分别提取近八年的国考行测试题题干中的TOP200关键词,这些关键信息足以代表该年份国考行测试题了,有了这些数据就可以进行对应分析。
最终得到下图(点击下方图片可查看高清大图):
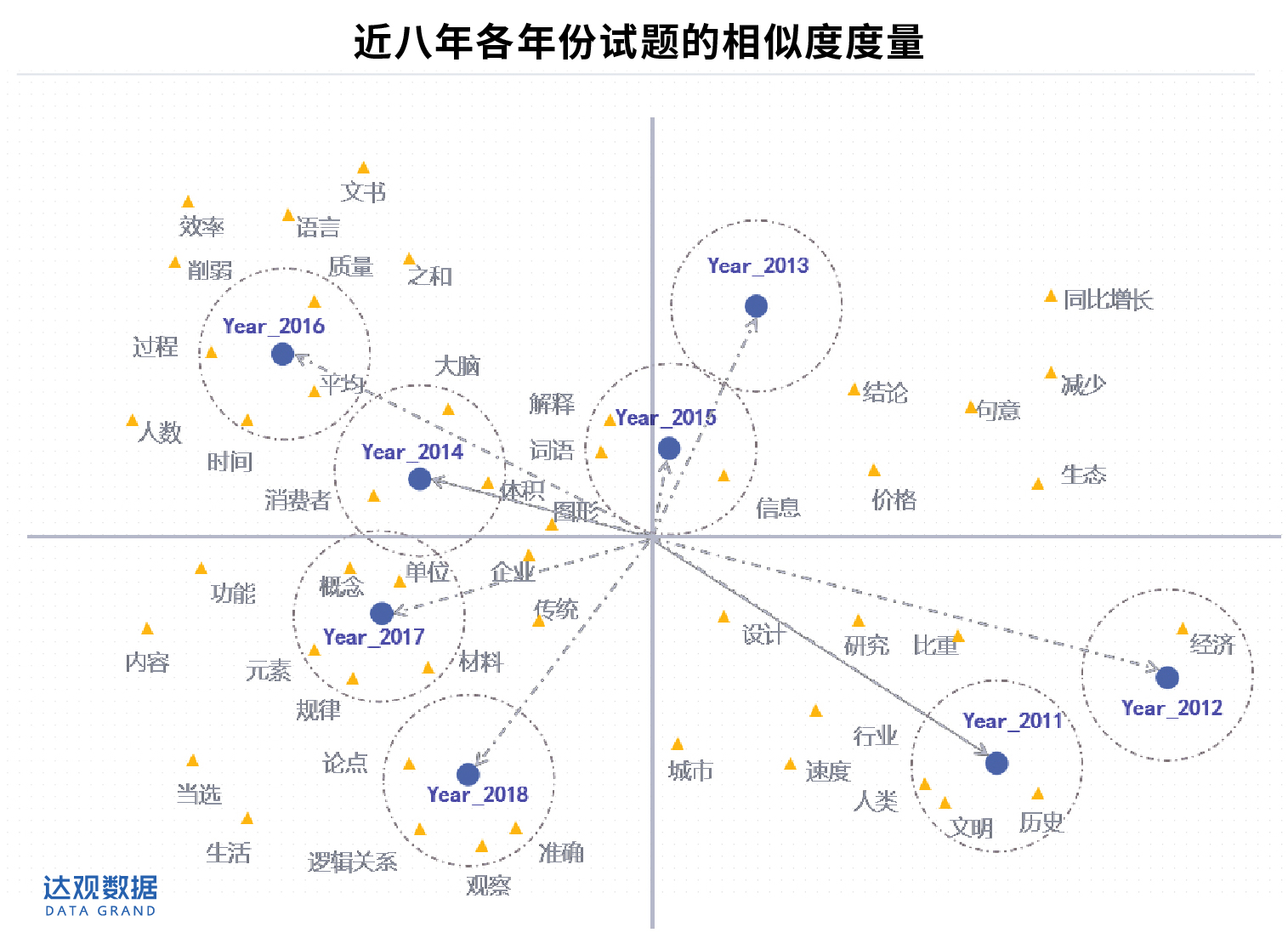
对于上图的可视化结果,可以这样解读: 夹角越小的国考试题,代表试题内容相似度越高; 其次,每个年份考题附近的关键词汇,离得越近,说明关键词在该年份试题中的重要性程度越高,也就越能代表试题的特征。
由此,我们可以得到两个分析角度:
- 从历年的考题内容相似度来看,2011年和2012年、2017年和2018年的试题内容相关度较高,也就意味着出题结构的连续性较好,以此类推,2013年度、2014年度、2015年度和2016年度的试题连续性也较好。与之相反的是,2012年度、2013年度的出题内容相似度较低,出题内容有一定的跳跃性。 总体上来看,国考试题在出题内容上的连续性较好,只是偶尔出现变动。
- 从历年试题的特征来看,2011年的人文特征较为明显,2018年的经济方面的试题较多,2018年的逻辑测试较突出,2015年的语言学方面出题较多,2016年的偏计算,其他年份的特征不甚突出。
小贴士:
对应分析法可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。比如不同年份的试题是不同类别,关键词汇是变量。对应分析图谱可以将这8年的试题相关度情况通过视觉上可以接受的定位图展现出来。
以上就是作为国考“外行”的笔者做的一些分析,由于仅提取出题干文本,文本数据量较少,难免会出现一些纰漏,而且对于有过国考经历的小伙伴来说,分析的结果可能还显得粗轮廓。
在这里,笔者想要对参加“中华第一考”、努力奋斗的中国考生们表达一下敬佩之情,特 以“金榜题名”为主题(不是藏头诗 )让机器赋诗4首,聊表敬意:

#专栏作家
苏格兰折耳喵(微信公众号:Social Listening与文本挖掘),人人都是产品经理专栏作家,数据PM一只,擅长数据分析和可视化表达,热衷于用数据发现洞察,指导实践。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议