打破机器学习技术与业务藩篱——Amazon SageMaker Canvas深度体验
编辑导语:机器学习这一概念并不是人人都懂,也因此,一款可以让用户无需拥有对应经验、即可实现机器学习智能分析的工具便容易让用户感到好奇,例如Amazon SageMaker Canvas。本篇文章里,作者就对这款工具进行了体验测评,一起来看一下。

作为一个曾经干过数据分析、数据挖掘、且目前从事数据产品工作的“数据人”,当听说亚马逊云科技推出了零代码、不需要机器学习经验就可上手的机器学习预测工具的时候,我脑海里条件反射性浮现出当年那个抱着算法啃到哭的少女,以及随之而来鲁豫老师的声音:我不信~~
抱着一颗一探究竟的好奇心,我登录官网看到有两个月的免费体验期后,便马上跟着官方指引注册设置好账户,决定深度体验一下这款产品—— Amazon SageMaker Canvas。
下面,我就以具体使用场景为切入,从“数据分析”、“产品设计”两个角度来分享下这一个多月来我的体验使用感受。
一、业务数据分析场景:用户注册预测
在零售客户营销领域,最重要的管理方式莫过于分类施策。对不同特点、处于不同阶段的客户采取针对性的营销手段,才能在有效的预算范围内最大程度提升营销效果。
比如,我们都知道在客户流失之前对其进行挽留的效果要远好于已经流失后再采取措施、以及如果能预判客户注册产品的可能性,就可以提前采取更为精准的营销方式,等等。
因此,准确预测客户在某种维度上的类别或可能性,提前进行精准的营销干预,对提升投入产出比是非常关键的事情。如何预测?以用户注册预测为例,目前各企业一般采取以下两种方式:
一类是业务部门根据自己的业务经验总结出哪些特征对用户是否注册某产品的影响较大,满足这些特征的便判定为“会注册”。
稍微严谨一点的会给每个特征赋予权重,计算得出注册可能性分数。但选什么特征,如何赋权,很大程度是依赖于业务同事多年对数据的观察总结和业务经验沉淀。
这种方式的优势在于,逻辑简单,业务解释性强;但缺乏对数据的深度挖掘,预测准确率较低,同时非常依赖个人经验。
另一类则是由专业的数据科学团队根据业务部门的预测需求,利用机器学习算法选取特征,训练、验证数据,最后输出一套最优模型进行预测。
由于运用了专业的数学及统计理论对历史数据进行挖掘探索,准确性较第一种方式有了很大提升。不过由于逻辑复杂,专业门槛高,整个过程对于业务同事而言是“黑匣子”般的存在。
相应地,数据科学家在业务经验方面较为缺乏,过程中需要与业务同事高度协作。对于这种“你不懂业务,我不懂算法”的情况,怎么能够高效沟通一直是很多企业在面临的阻碍。
此外考虑到整个过程耗费的人力算力和时间成本,利用机器学习探索数据的方式在企业里一直很难普适性地推广开来。
总之,现状就是业务分析和机器学习模型之间的确或主观或客观都存在着一道隔阂。但Canvas官网的产品优势介绍(图1),仿佛就在说它可以打破这块藩篱。为了印证,我将自己代入为一个不懂代码不懂算法的业务分析角色,切实体验下如何在Canvas中进行用户注册预测。

图1(来自官网)
第一步:数据准备
本次使用亚马逊云科技官网中的数据集,背景为银行业务分析师想要预测哪些客户最有可能注册存款证,数据字段如图2。

图2:银行营销数据集字段说明
首先将数据集拆分为训练集和测试集。因为官网数据集是比较规整的,为了更贴合平时业务分析工作中的数据情况,再将训练集纵向拆分成两张表(trainA、trianB)。
tainA包括了客户的基本信息及目标值(图2中的2-8和目标字段y)、trainB包括剩余的客户活动信息以及宏观经济指标(9-21字段),两个数据集均有客户代码。同时,我将部分字段的值替换为缺失值以更贴合实际情况。
第二步:将训练集导入Canvas
进入Canvas首页后,在dataset(数据集)中选择Import(导入)。可以看到有三种导入方式:
- 本地upload:直接拖拽本地文件上传。
- S3储存桶:从S3云中载入数据。
- 构建链接器从第三方数据源(Redshift和Snowflake)导入。
前两种方式我都尝试了一下。对于3万多行、22个字段的数据,导入用时大约10秒。导入后可立即对数据进行预览。
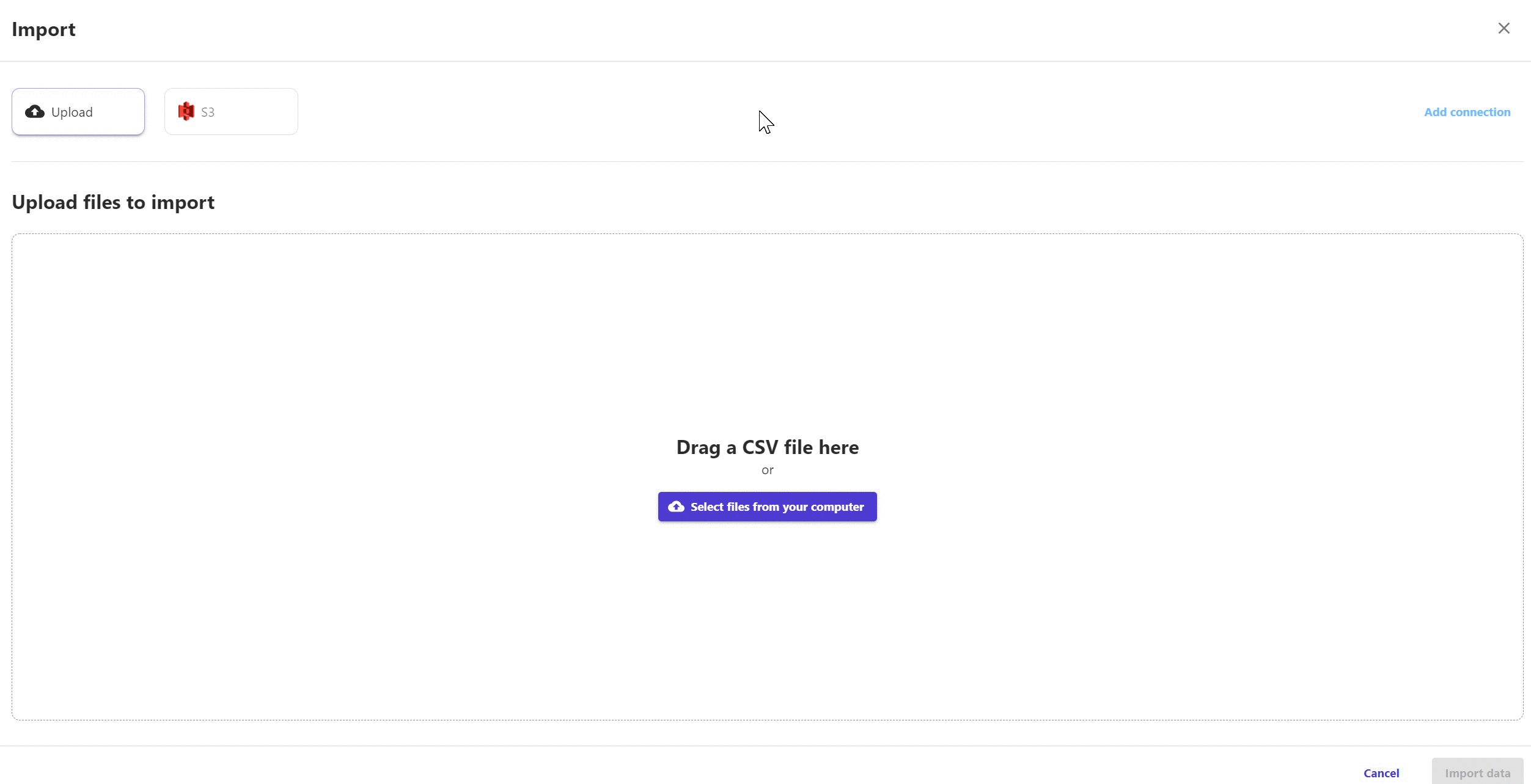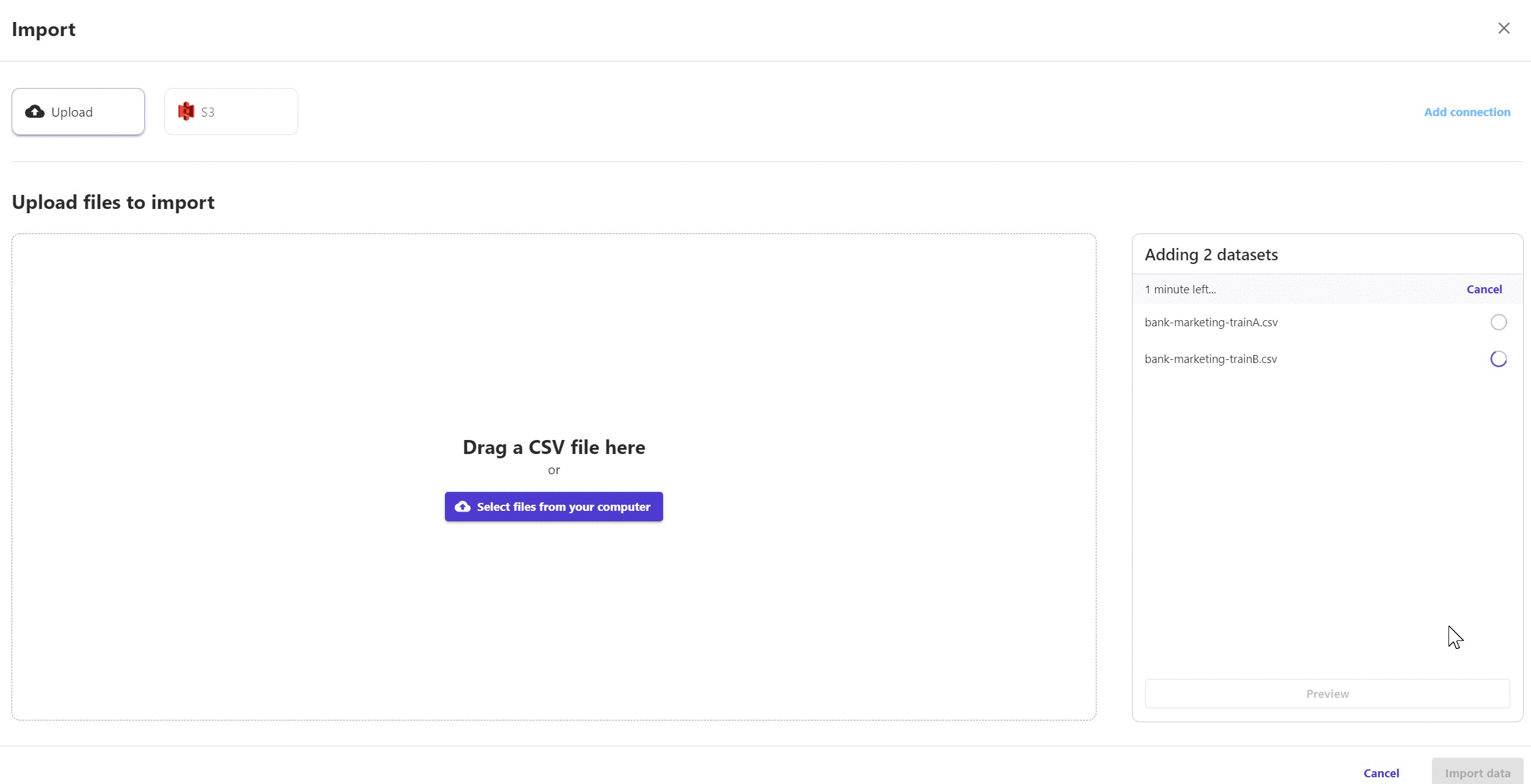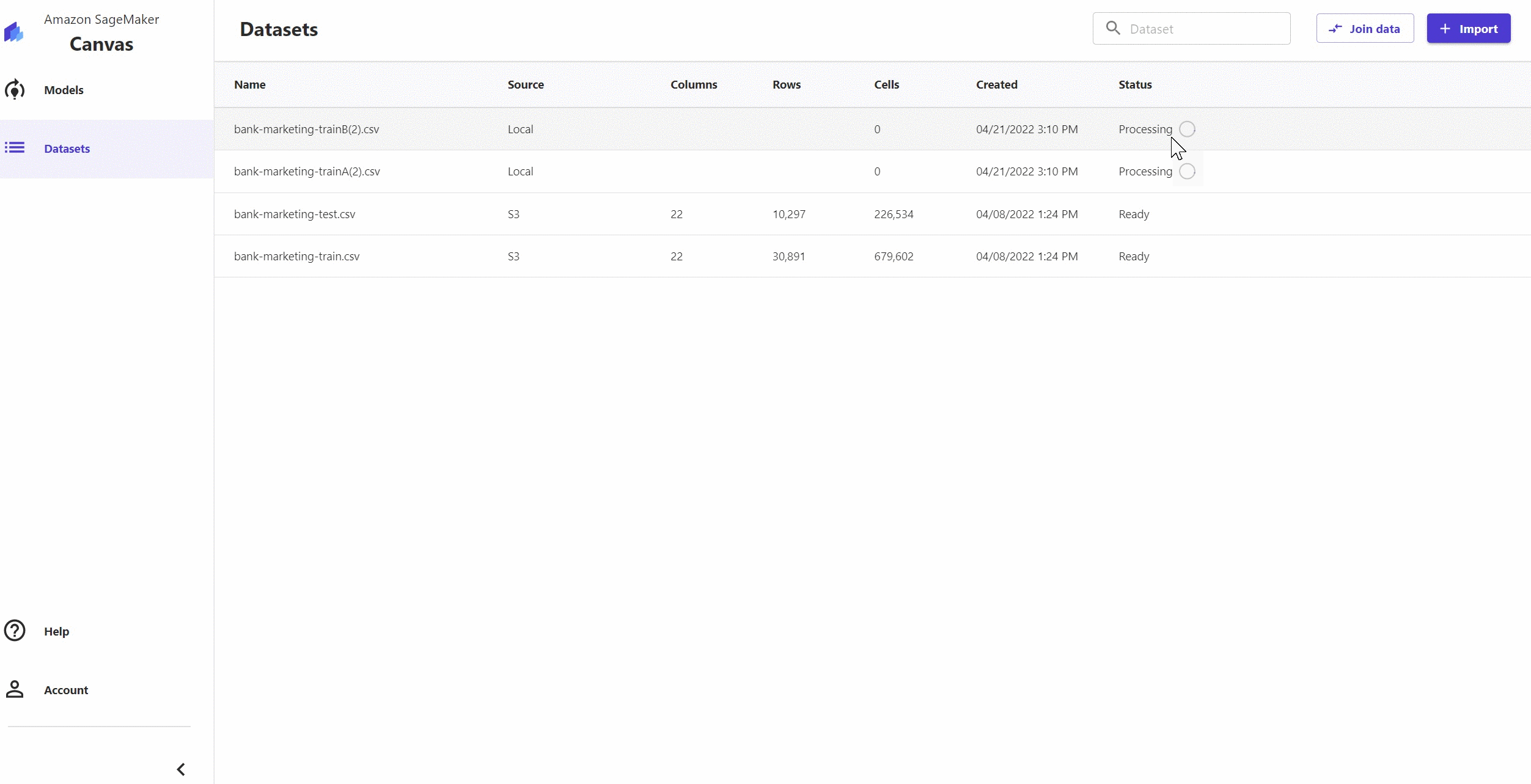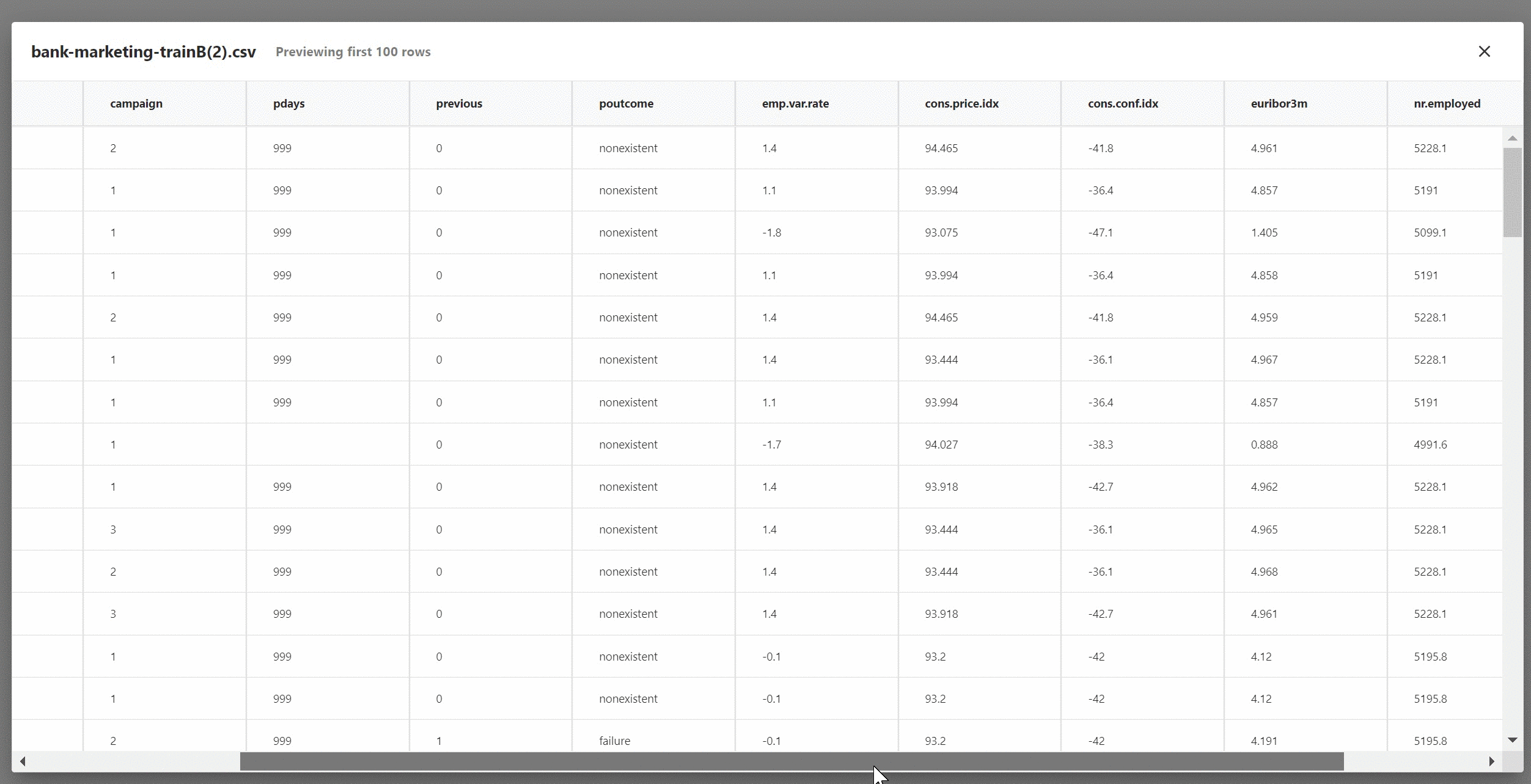
图3
现在需要把导入的两个数据集trainA、trainB拼接成一张具有完整特征和目标信息的表:train。该数据处理过程一般在建模之前会事先用其他工具完成。
但我发现Canvas在导入数据后,就自带了这个数据连接功能:Join Data:用鼠标拖拽想要连接的表,自定义连接方式及连接键,合并为一张表。
虽然最终达到的效果同Excel的Vlookup、SQL的join、以及python的pandas.concat等,但这种可视化的拖拽方式在操作便利度上还是有了极大提高。
至此,我们的训练数据集train已完整导入。

图4
第三步:训练数据,建立模型
首先,添加并命名New Modle:bank-marketing。接下来跳转到的建模页面依次有四个模块:Select(选择数据)、Build(建立模型)、Analyze(分析模型结果)、Predict(预测新数据)。按照模块顺序,我开始照着页面提示进行操作。
1)Select dataset
这一步是选择训练数据集,先前导入及拼接好的数据都可供选择。而且此步骤也可以跳转到第二步从本地或云上导入数据集。我选择了先前导入拼接好的数据集:train。
图5
2)Build
数据集选择好之后,自动跳转到了Build页面。Build页面简洁地分为四个区域:数据集统计概览、目标字段指定(Select a column to predict)、模型类型选择(Model type)、建模(Preview model、Quick build、Standard build)。
① 数据集统计概览区:各字段的统计概览已经自动呈现出来,包括:
字段基本信息(数据类型、缺失值个数及占比、格式不匹配值的个数及占比、去重数统计、均值、众数)。
可以预览到此数据集中存在缺失值,不过Canvas官方介绍说建模时会自动进行缺失值、格式不匹配值自动进行处理。且诸如归一化、数值编码、分箱等特征工程操作,Canvas都会内部自动处理。这对业务人员对所导入数据集的事前处理也降低了要求。
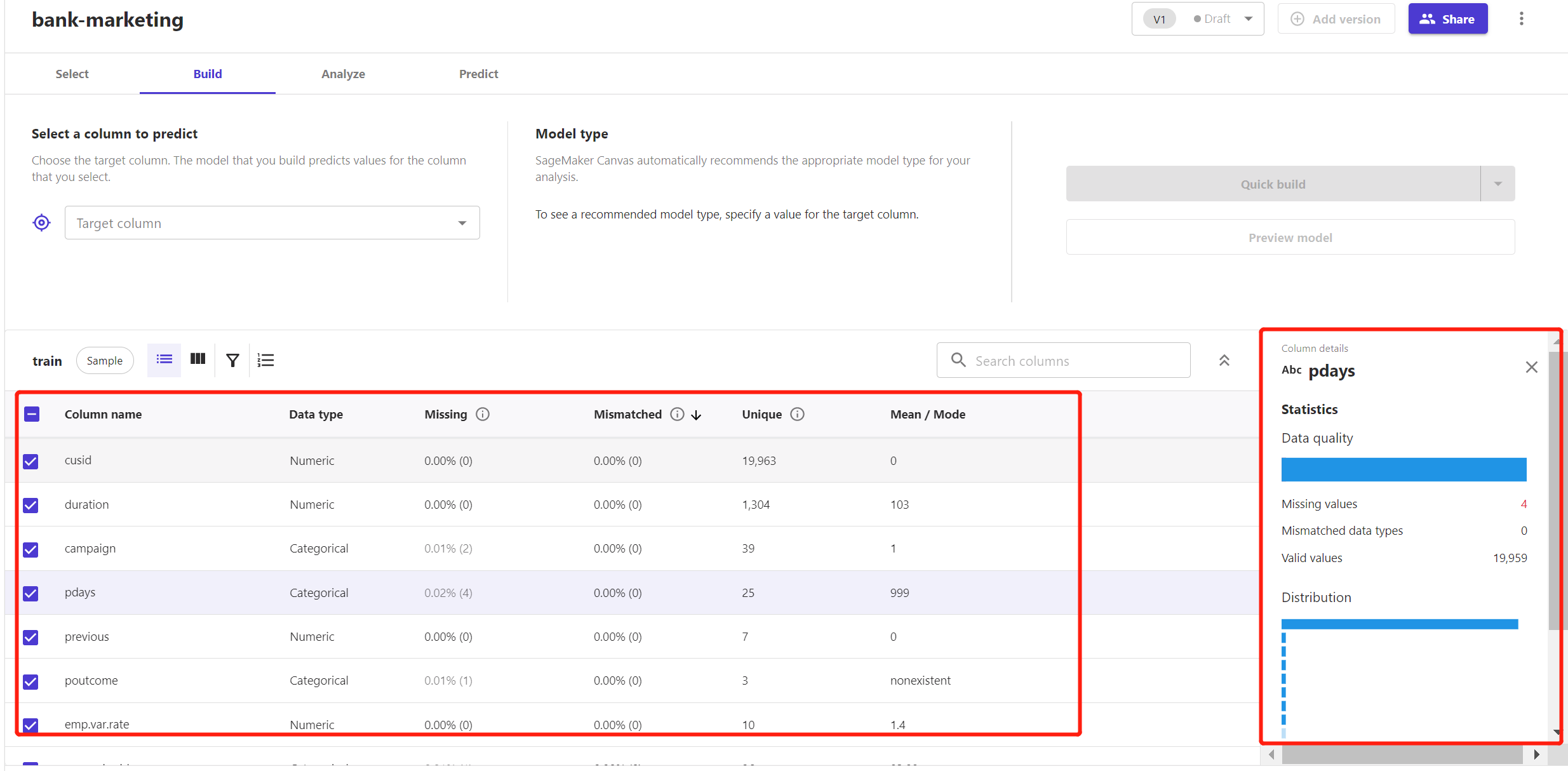
图6
字段分布统计可视化:
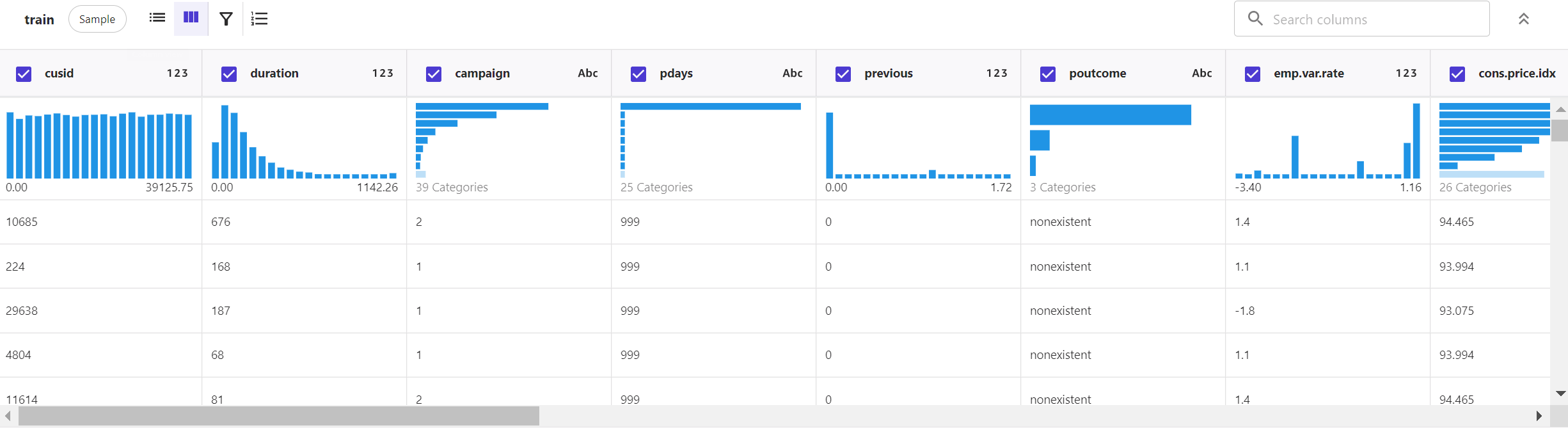
图7
字段筛选查看:
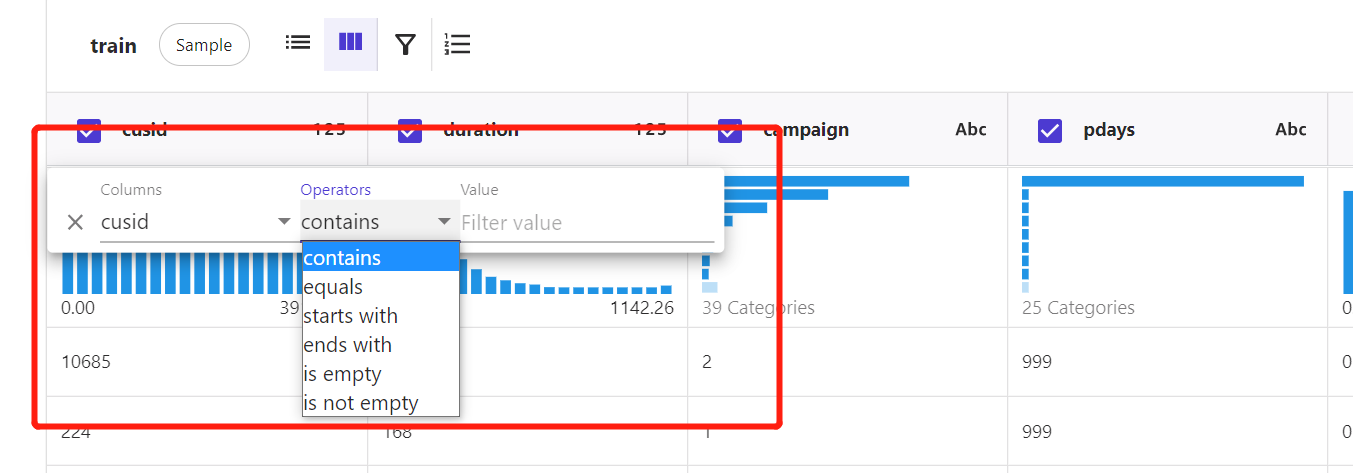
图8
② 目标字段指定(Select a column to predict):需要我们选择模型的预测目标字段:y。
此时,旁边的Modle type(模型类型选择)已经根据我所选择的目标字段快速匹配好了相应的模型类型:二分类模型(2 category prediction)
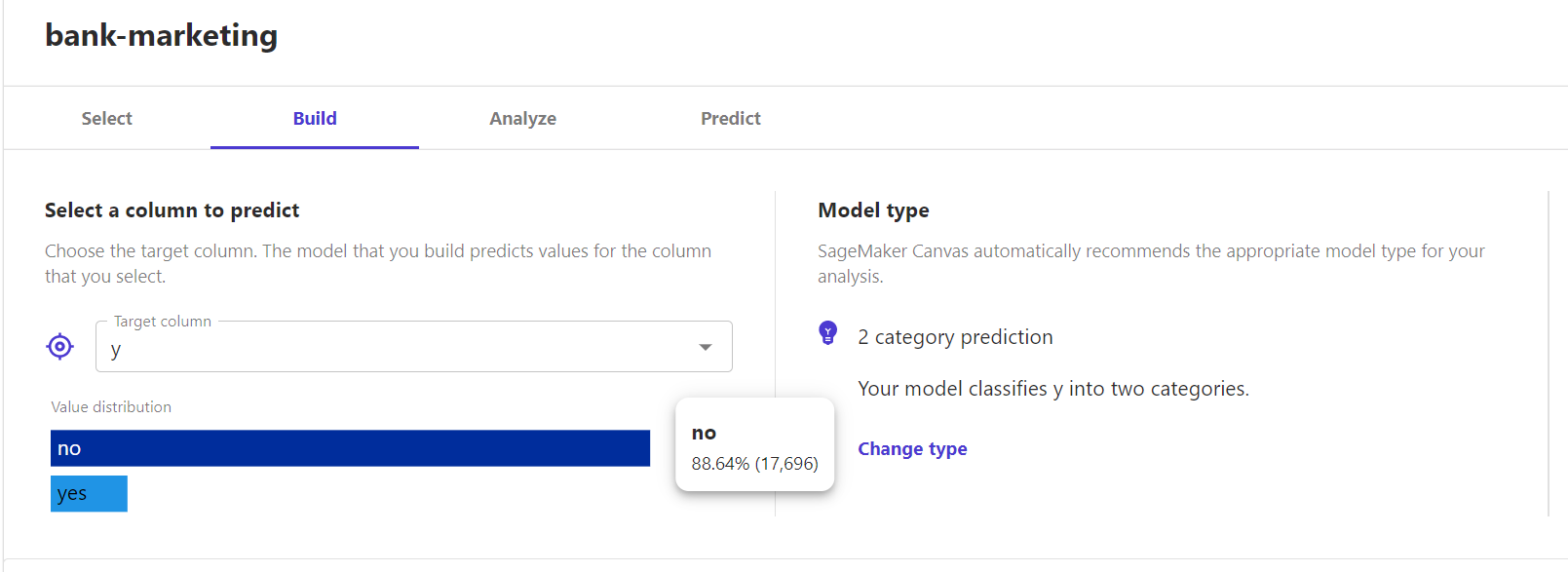
图9
在Model type中,我们还可以自行选择模型的类型。Canvas目前支持的模型类型有(图10):二分类模型(2 category prediction)、三种及以上分类模型(3 +category prediction)、回归模型(Numeric model type)、时间序列预测模型(Time series forecasting)。当我测试导入包含时间列数据集、且选择了一个变化的数据列作为目标,会自动匹配到时间序列的预测任务。
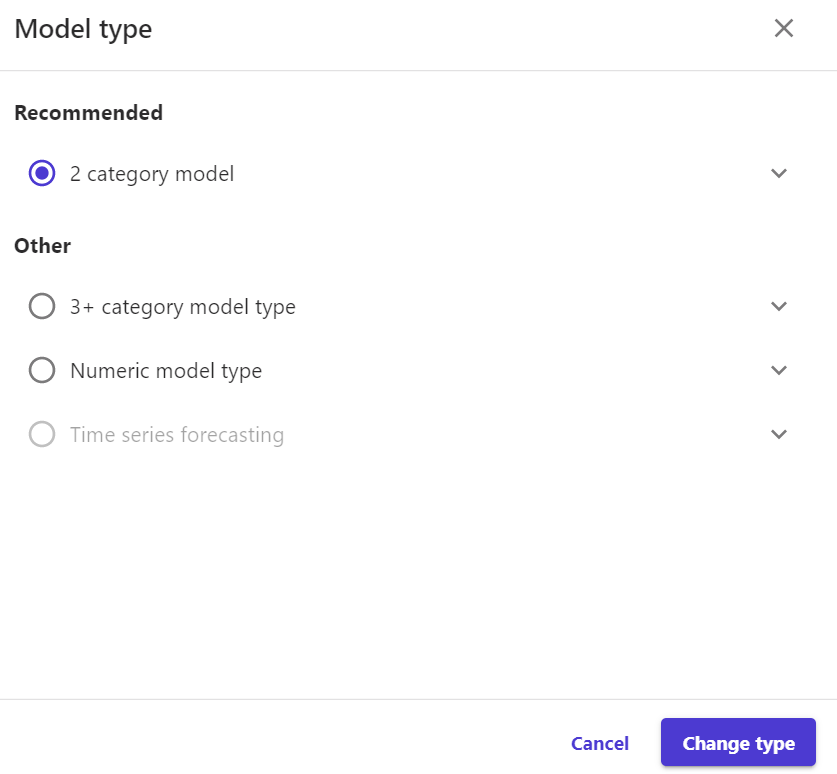
图10
建模区域有正式建模和预建模。预建模( Preview model ) 是正式模型构建之前,Canvas帮我们粗略搭建的模型,通过 Preview model , 我们可以大概了解模型的预测效果、以及每个特征字段对目标值y的影响程度(图11)。
Canvas 初步建立的 Preview model 显示,模型的准确率为91.682%,并且loan对目标值y的影响程度最小。为了减少不重要特征值的干扰,同时提高建模效率,我在正式建模时,没有勾选字段Loan,并且从业务知识我可以知道cusid对用户的是否注册也是没有影响的。因此我去掉了对特征字段Loan、cusid的勾选,并开始正式建模。
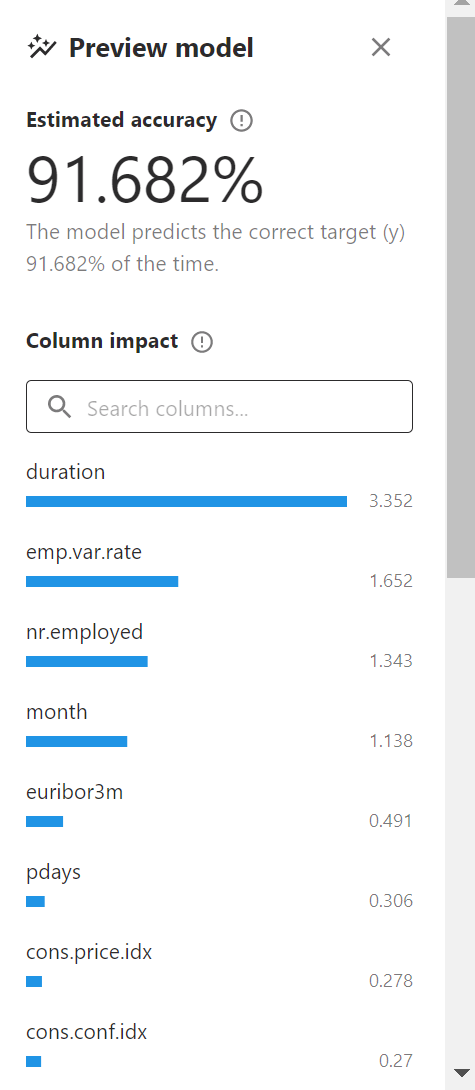
图11
正式建模分为“Quik build”、“Standard build”。前者用时较快(2-15min),后者根据数据集大小不同大约需要耗时2-4小时,但预测准确率更高。可根据模型应用场景的严谨度要求不同进行选择。我选择了”Quick build“进行建模。在等待期间,也是可以正常使用Canvas的其他界面。
第四步:模型分析
2分钟后,我得到了Quick build的最终建模结果。对目标值y的预测准确率为91.649%。
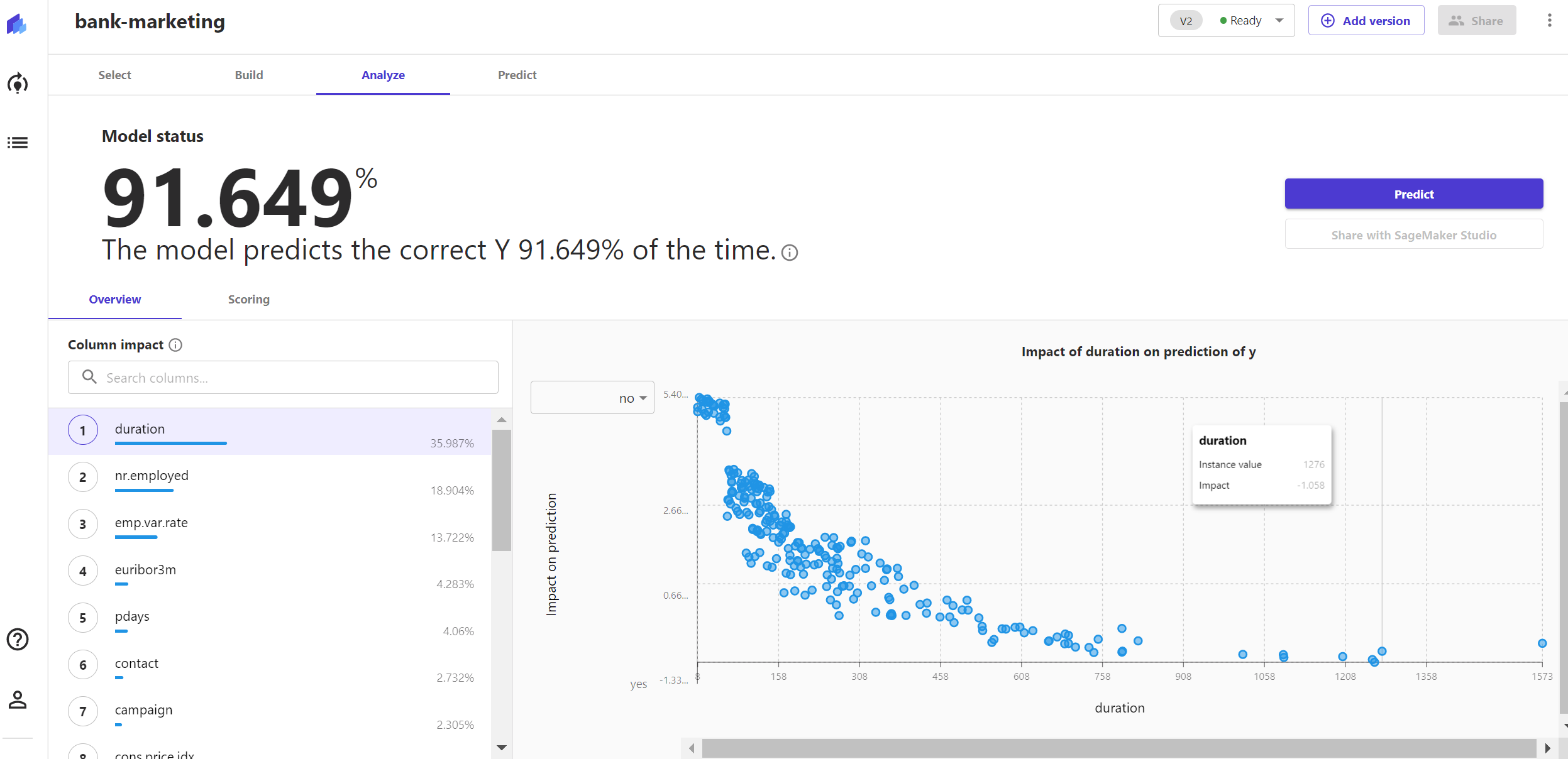
图12
此外,我还得到了更多信息:
1)单特征影响(Column impact)
我可以看到每个特征对客户是否注册的影响程度大小,其中duration,也就是客户上次被联系的持续时间大小对客户是否注册存款证的影响是最大的,其次是就业指数。
并且,每个特征字段的具体取值是如何影响预测目标的可视化分析图也在旁边被清晰地展示出来。例如,通过对比图中contact两类取值的中位线高度,就能看出相比使用座机联系客户,使用手机联系的客户注册存款证的可能性更高。这对后续我们营销客户存款证该采取哪种联系方式有很大的指导意义。
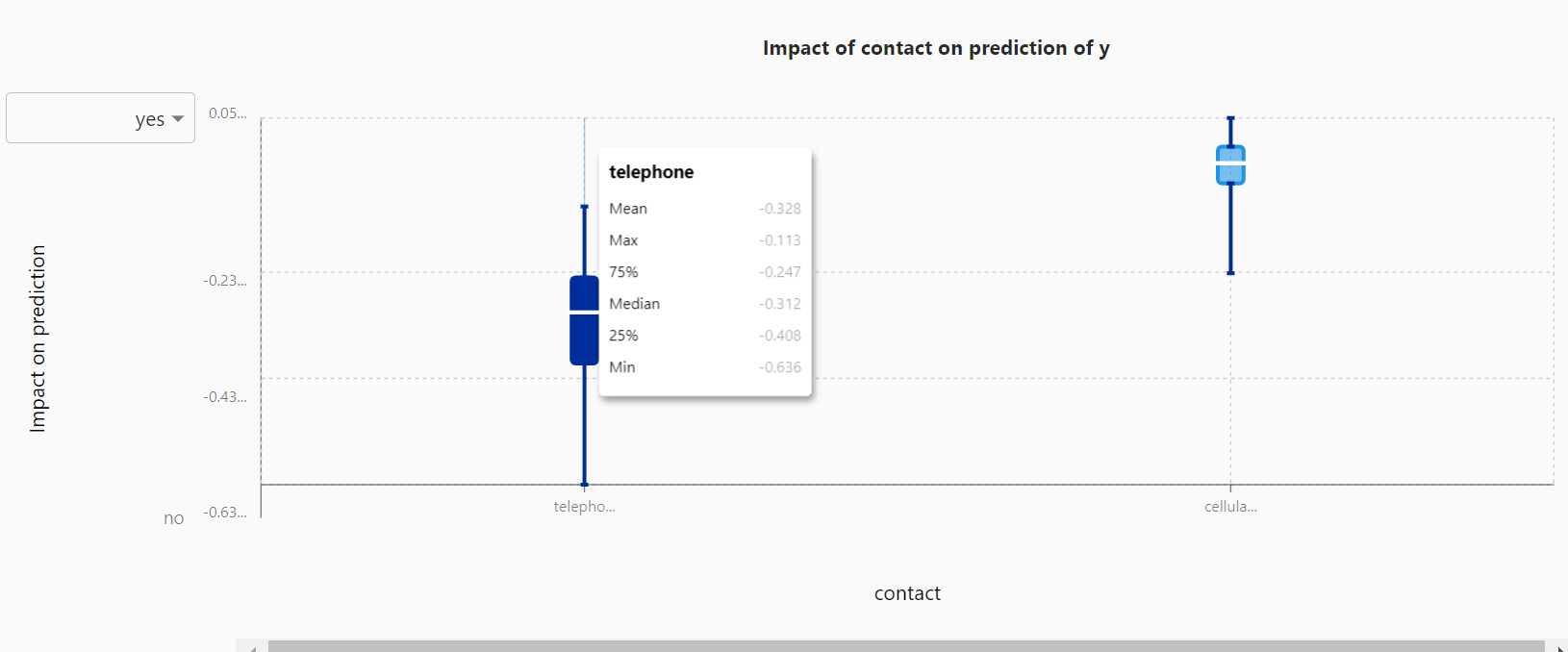
图13
2)模型评价指标
我们还可以看到该分类模型的桑基图(图14)、各种评价指标和混沌矩阵(图15)。
例如,我们看到在真实注册了存款证的客户有570个,其中有375个被模型准确预测到了,这说明准确率precision为65.789%。而所有预测为会注册存款证的客户有696个,其中375个是真的注册了,则模型召回率recall为53.879%。
由于我们在营销过程中,关注重点在于找出那些可能注册的客户(y=yes),如果现阶段的营销策略较为激进,宁愿误判客户会注册,也不愿漏掉一个可能注册的客户,那precison更高的模型就是更符合我们营销政策的;如果现阶段的营销策略较为保守,希望预测会注册的客户中大多都是真的会注册的客户,则应该选择recall更高的模型。
值得一提的是,也许不是所有业务分析人员都能马上理解precision、recall等指标的含义。但桑基图(图14)则能让一个就算完全不懂机器学习的人也能够快速直观地看出分类预测结果与实际值之间的关系。
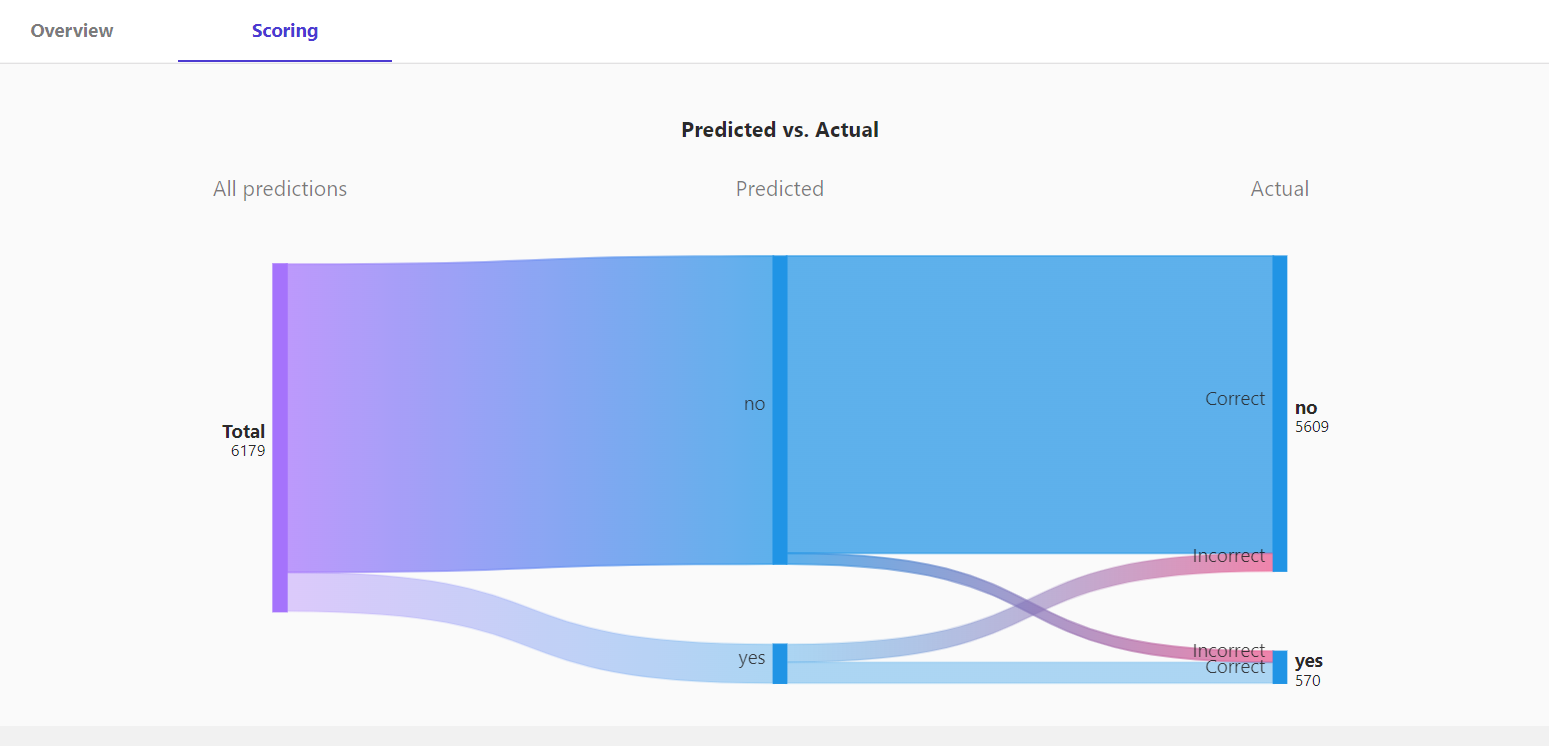
图14
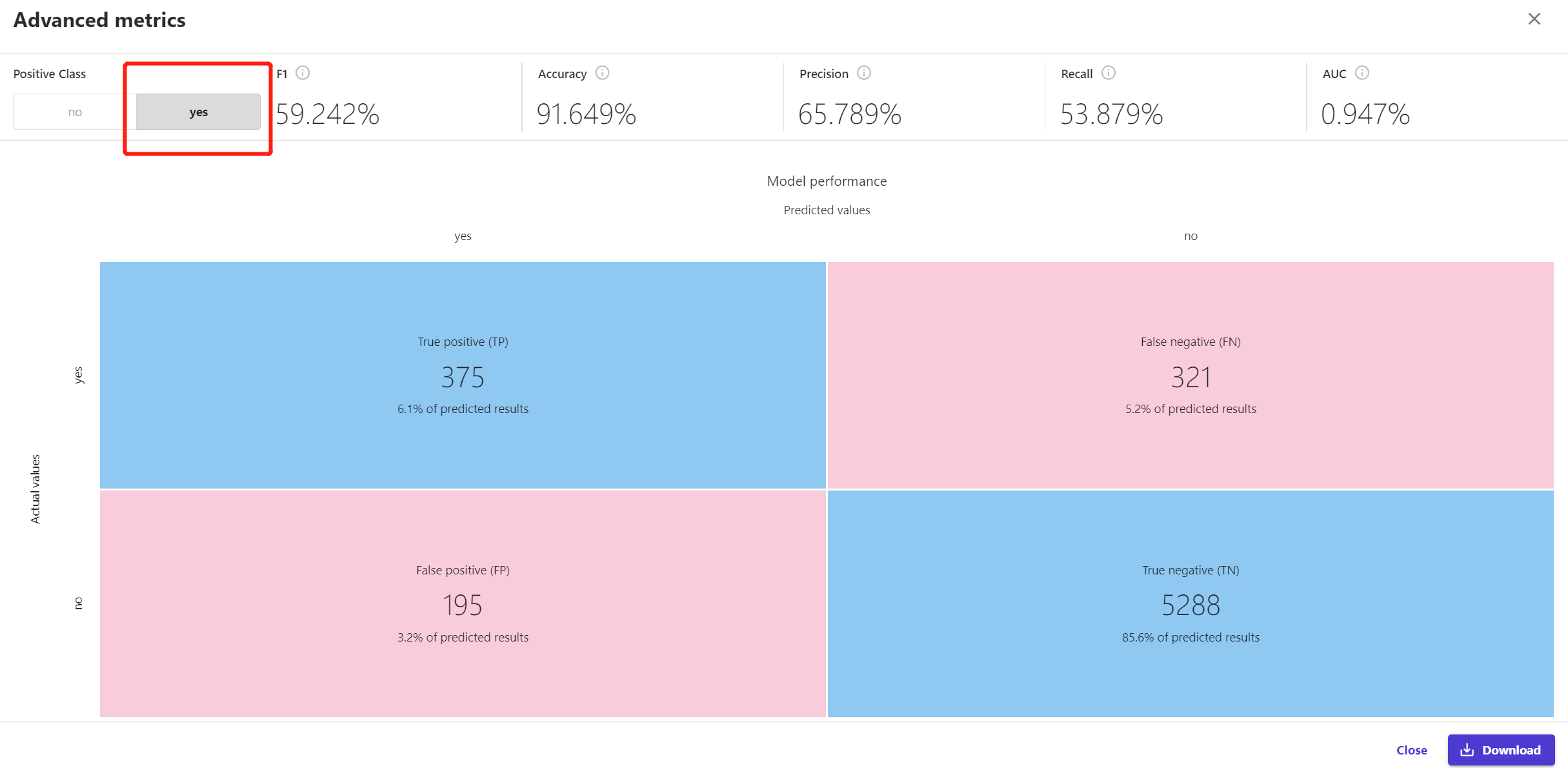
图15
第五步:新数据目标值预测
现在模型已经建立好,并且我们对模型的分类结果也有了直观地了解。接下来就是在实践中检验“真理”的时刻了:对训练集以外的新客户数据进行预测。Canvas的预测方式有:批量预测和单点预测。
1)批量预测(Batch prediction)
我导入了之前准备好的验证数据集,1万多行的数据集在5秒钟之内便得出预测结果(图16)。预测结果中不仅有客户的分类结果(是或否),还有客户被预测为“是”或“否”的概率值。
这样,我们就可以根据预测为“是”的概率大小降序排列,制定不同优先级程度的营销手段,例如为“是”的概率大于80%的客户,将其推送至客服专人电话营销,概率在50%-80%之间的客户,仅通过短信营销。
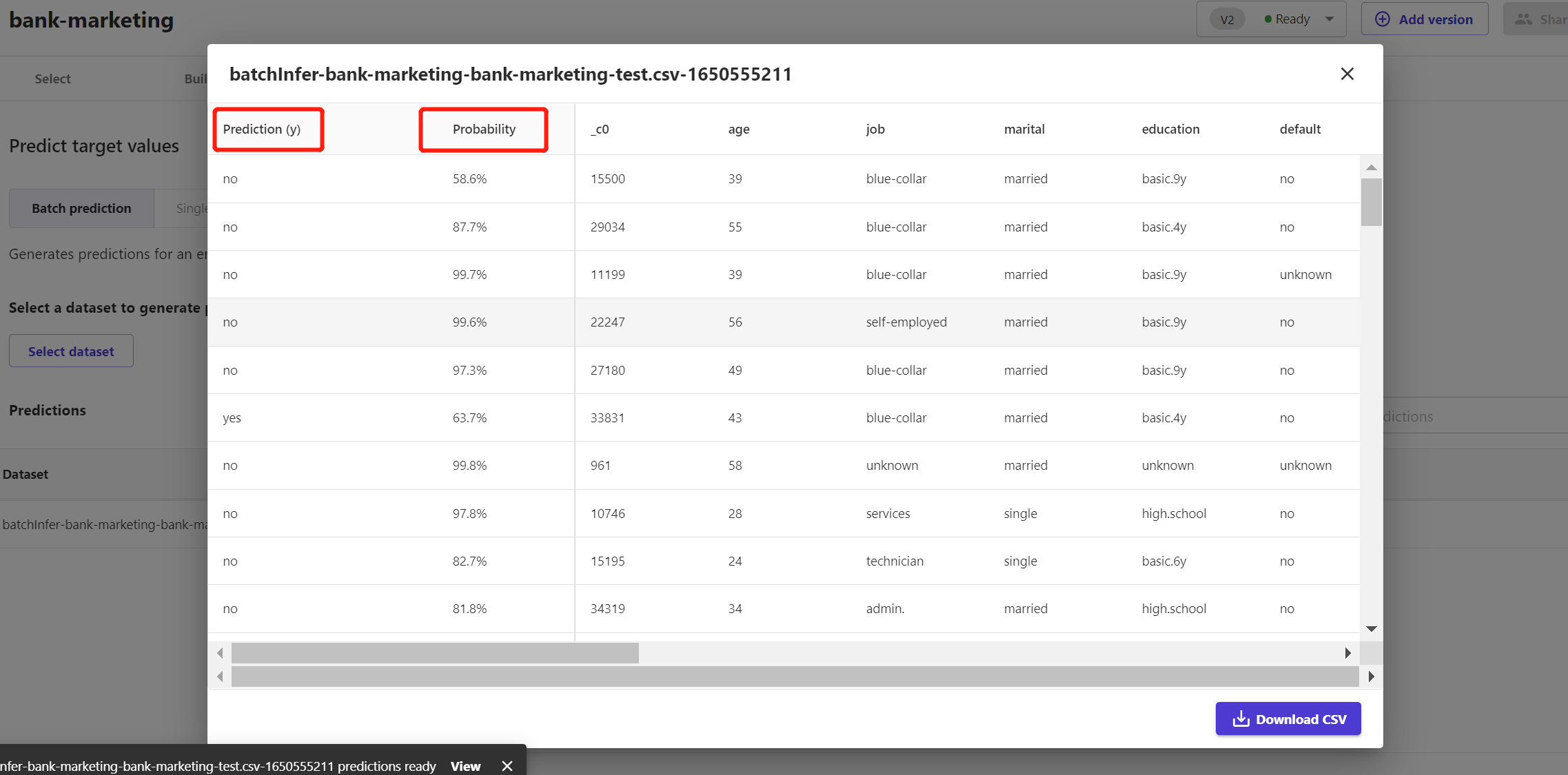
图16
2)单点预测(Single prediction)
这里我录入了单个客户每个特征字段的值,Canvas便预测出这个客户有99.844%的概率不会注册存款证。当我们想要对某个客户进行重点营销或关注时,这样的单点预测便能极大提高便捷度。
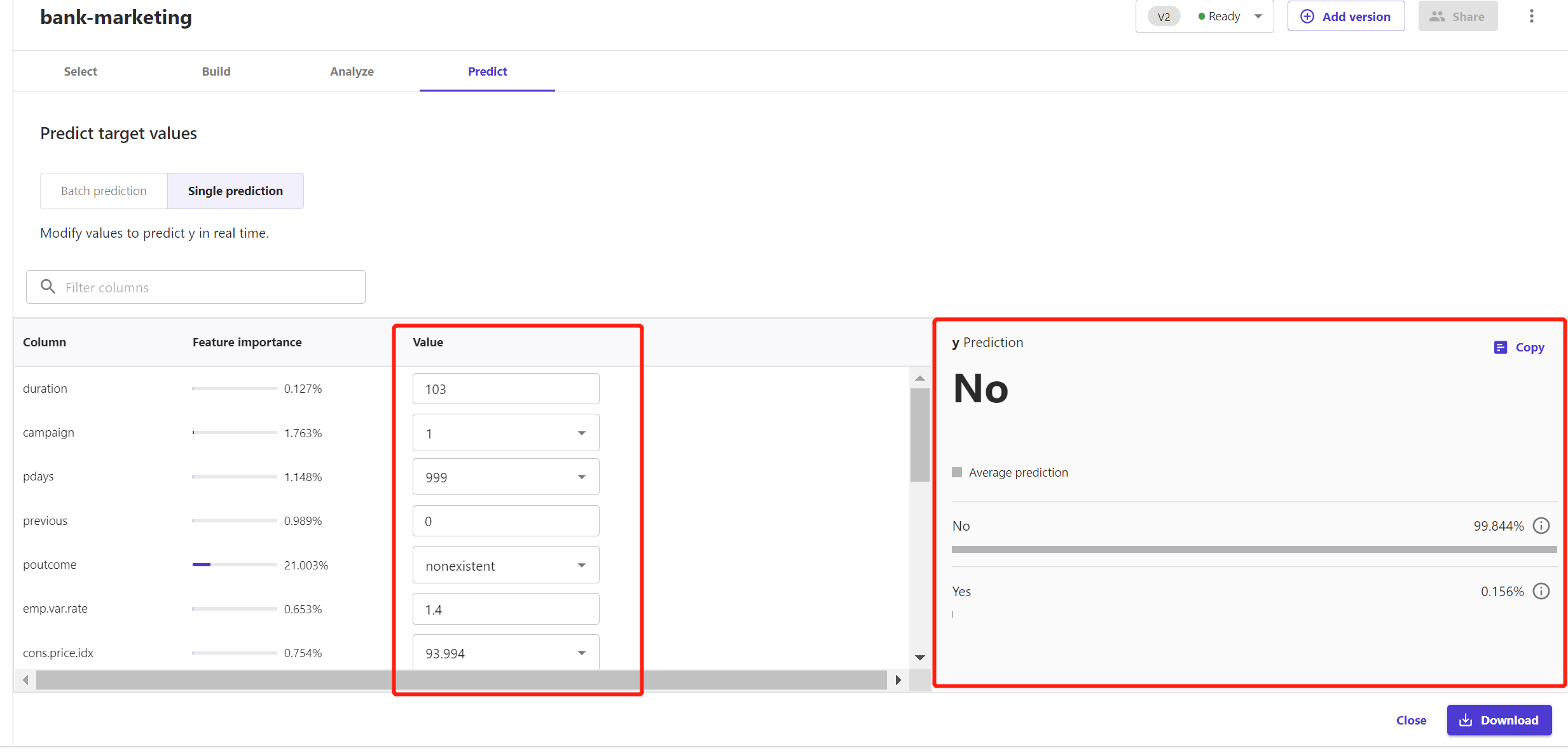
图17
第六步:分享模型给数据科学家
在一些非常重要的业务预测场景下,我们常常会对预测的准确性有更严格的要求或者想要模型在业务中更长期广泛地应用。这时,可以利用Canvas将我们训练好的模型通过Studio Link分享给数据科学家,他们便可以直接对模型的底层代码进行进一步的调试优化、部署等工作。
二、从业务数据分析预测角度看Canvas
Canvas的使用群体定位是不会代码、没有机器学习经验的业务分析人员,那么从业务数据分析工作的角度来说,我体验总结出Canvas的以下应用价值:
1. 适用于各类业务预测场景
包括分类预测、数值回归预测、时间序列预测。例如,精准营销需要对客户的注册可能性进行分类预测、金融风控需要对客户将来是否会逾期进行分类预测;仓储管理需要根据历史情况预测库存需求量(回归预测);零售门店管理需要对具有周期性特点的客流量进行预测(时间序列预测)……
2. 提高了业务预测的准确性、可解释性
从文章开头提到的目前两种业务预测方式可以看出,业务预测的准确性和可解释性通常很难兼得,而Canvas可以让业务人员通过机器学习模型进行预测以及挖掘出的每个特征变量的取值影响,分析结果可以更准确、有依据地应用于业务运营管理决策。且整个过程业务方参与度高,业务可解释性也相应得到很大提升。
3. 提高了机器学习应用的普适性
由于Canvas将机器学习预测的能力产品化、无代码化。企业人员使用机器学习的门槛大大降低,一方面能解决传统业务分析方式下对个人分析经验极度依赖的情况;另一方面能使得机器学习在企业内得到更普适广泛的应用。
4. 极大降低了业务分析人员与数据科学家的沟通成本
Canvas可以将业务同事建立的模型分享给数据科学家,便于其对模型代码进一步优化。双方在业务和技术的对接上直接通过Canvas形成了共识,使得业务与技术的沟通协作更加高效。
三、从产品设计角度看Canvas
1. 产品定位清晰且直击痛点
Amazon Sagemaker Canvas的用户定位为无代码及机器学习经验、但有通过数据来进行业务预测需求的群体。这恰好瞄准了企业数据分析现状的痛点,很大程度上弥补了业务分析与机器学习应用之间的隔阂。
此外,Canvas在使用过程中可以与亚马逊云科技的其他产品搭配使用,例如与Amazon S3、Amazon Redshift的数据对接、与Amazon SageMaker Studio的底层联动,清晰界定的产品范围及搭配方式也让用户的使用体验更加高效。
2. 功能结构化繁为简
我将Canvas的功能模块结构梳理如图18 。其中最主要的模型建立部分包括四个步骤:选择数据(Select)——建立模型(Build)——分析模型效果(Analyze)——进行预测(Predict)。整个过程看似简单,却囊括了机器学习的全流程,在化繁为简的同时,能充分满足业务人员的分析预测需求。
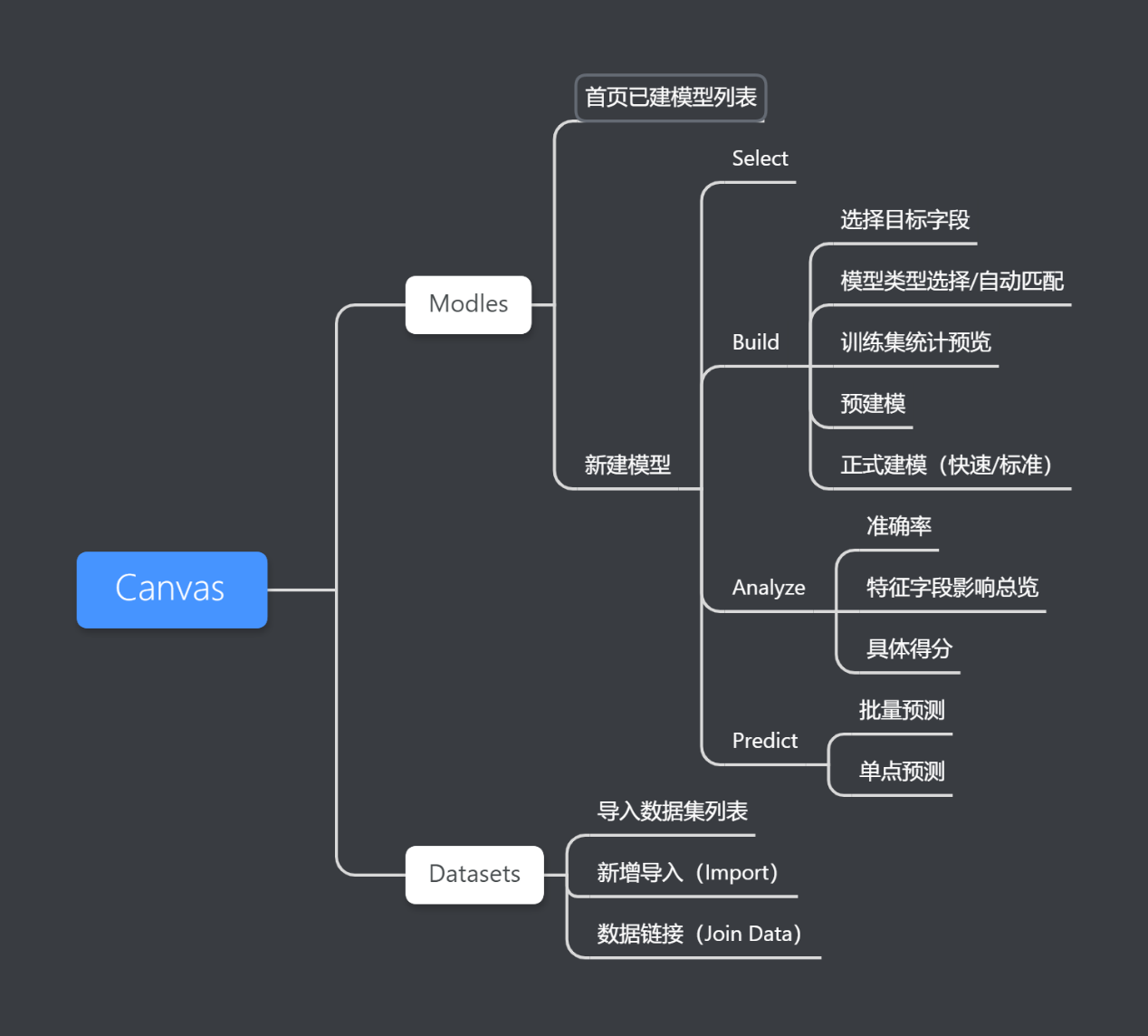
图18
3. 交互操作简洁易懂
首先从界面上来看,Canvas的UI风格及配色上都非常简洁(图19),每个界面的要素都是必要且最少;在我操作的过程中,只需要跟着功能菜单的顺序和提示一步一步进行即可,并且操作都是点击、拖拉这样的简单方式。
数据的展示及模型评价分析时,大量采用可视化图表,直观易懂。的确是不需要写一行代码、机器学习零经验的人也能快速上手使用。
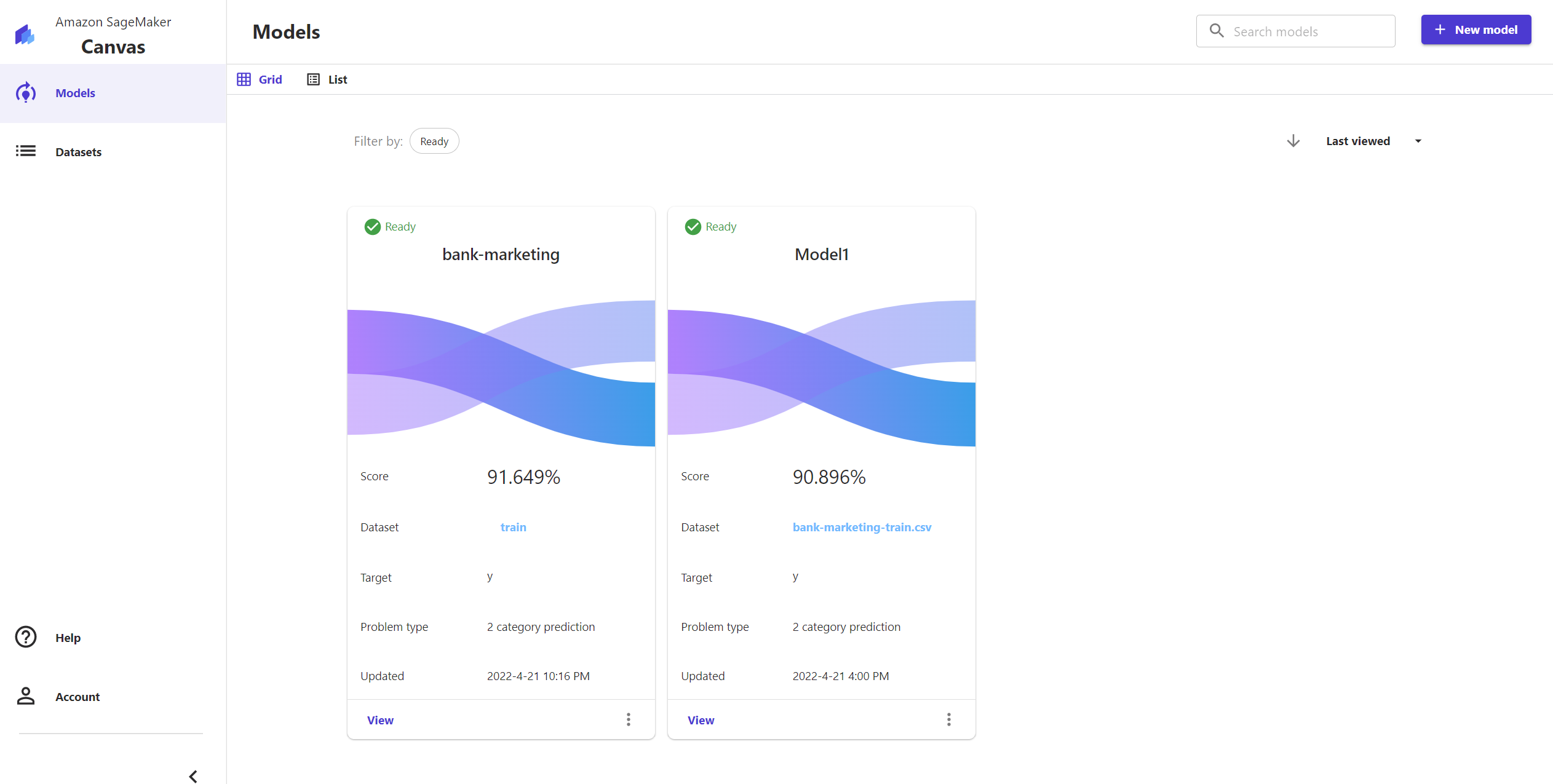
图19
四、体验感悟
因为我自己以往的工作中在业务部门做过数据分析,也在技术部门做过数据挖掘,经历过不懂代码不会机器学习却必须要给业务做预测分析的阶段,也经历过后面花大量时间学习写代码和机器学习算法转岗数据挖掘、但却离业务越来越远的阶段。
Amazon Sagemaker Canvas 巧妙地打破了这两者的壁垒,其无代码也体现出产品背后强大的技术支撑,毕竟功能开发需要深刻场景理解及技术积淀。
在使用过程中我多次联想到当年计算机从Linux迈向图形交互界面所产生的里程碑式的影响。
Amazon Sagemaker Canvas表面上是一个无代码机器学习预测服务平台,但其实本质更体现出一种“科技普惠”的理念,让机器学习技术能够被更广泛的、有需求的人应用。而这种“科技普惠”所带来的质量和效率提升、资源成本的节约,正是当前各企业数字化转型过程中最重要的价值。
本文由 @离子烫电台头 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Pexels,基于CC0协议