在线教育大数据营销平台实战(一):大数据平台构建实战
编辑导读:企业每天生产众多的数据,这些数据要经过分析才能对业务、运营等产生价值。而大数据平台就是了满足企业对于数据的各种要求而产生的。如何构建一个大数据平台,取决于企业的数据化程度和面临的数据问题。本文作者将以在线教育为例,分析如何从0到1构建大数据平台,与你分享。

第一篇文章,按照惯例先做个自我介绍。本人目前在一家在线教育公司担任大数据营销产品负责人,由于一些机缘巧合,我同时负责了数据产品线和营销CRM产品线,因此给了我更多的机会去思考和实践如何把数据与营销业务深入融合,将大数据的势能赋予营销平台,从而实现业务的精细化运营和数据驱动。
接下来,针对在线教育业务场景下的大数据营销平台实战,我会用一个系列的文章进行系统化阐述。文章可能会涉及:大数据平台搭建、用户画像服务体系、CRM线索动态评分模型及分配算法、数据产品实施推广方案、客户数据中台(CDP)等多个方向。
本篇主要来讲解如何从0到1构建在线教育业务场景下的大数据平台。
一、企业数据问题诊断
产品是为了满足需求,是否需要构建大数据平台?以及构建什么样的大数据平台?取决于企业的数据化程度和面临的数据问题。因此在构建大数据平台之前,需要进行充分地调研,找准问题才能对症下药。对企业数据化程度的评估方法,可以参考下图所示的数据管理能力成熟度模型(DMM)。

通过前期的调研和分析,我们公司当时处于L2等级,面临的主要数据问题如下:
1)数据源分散
- 不利于多数据源之间关联分析
- 不利于数据资产价值的进一步挖掘
- 数据孤岛严重
- 无统一数据平台、数据资源得不到汇总沉淀,数据无法高效支撑业务
2)数据指标不统一
- 不同业务部门分而治之
- 准确性、权威性受到质疑
- 不利于公司各业务部门KPI考核
- 指标统计口径需要标准化
3)数据分析效率低
- 各业务部门占用部分精力数据分析工作
- 对于数据的需求往往需要从原始数据开始
- 对数据分析师的支撑不够
- 无成型完整的数据分析工具
4)数据管理问题
- 无统一数据字典
- 缺少数据地图
- 无元数据管理
二、大数据平台业务架构及Road Map
上一部分已经对企业内部数据问题进行了全面诊断和问题剖析,接下来我们针对这些问题给出解决的架构方案和路线图。
1. 数据服务体系蓝图
从业务视角给出了如下的数据服务体系蓝图,数据服务体系的规划需要满足三点:数据服务体系需要覆盖完整的公司业务、贯穿业务的各个阶段、伴随企业发展。

在此数据服务体系中,处于核心环节的是数据整体建模和数据资产管理,也就是我们熟悉的统一化数仓建设。结合在线教育业务特点,数仓建设需要满足三个核心数据体系建设:
- 用户数据体系:用户分析应用、用户标签、用户行为数据,用户基本信息主数据等;
- 营销数据体系:营销分析应用、营销分层标签、渠道特征数据、营收转化相关的主数据等;
- 学习数据体系:学习分析应用、学习偏好标签、学习行为数据、学习素材基础数据等。
2. 数据仓库架构
数据仓库的层次划分采用业界通用的层级划分方式,包括:ODS、DWD、DWS、ADS层,如下图所示:
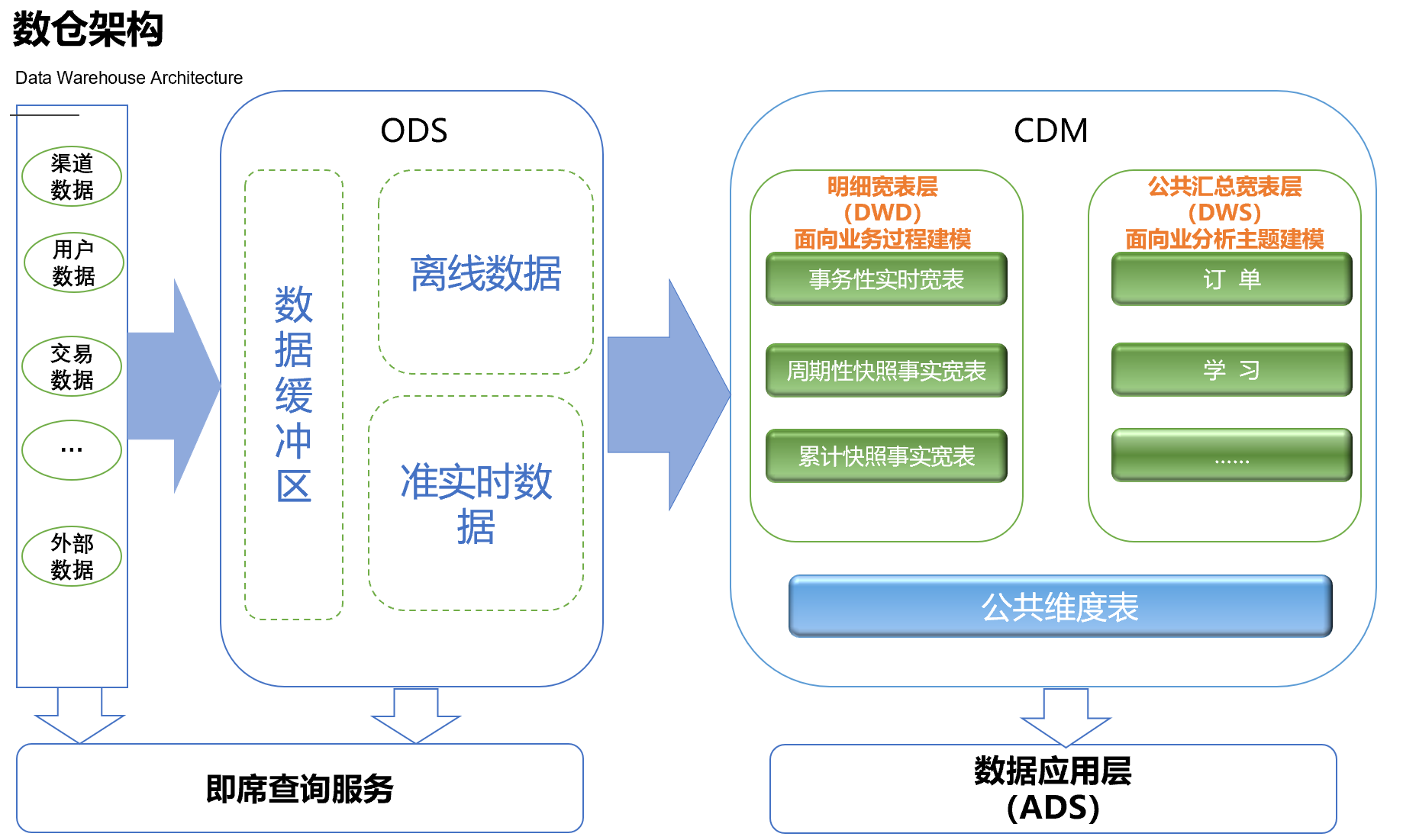
1)ODS层
- 数据同步:结构化数据增量或全量同步到数据仓库;
- 结构化:非结构化(日志)结构化处理并存储到数据仓库;
- 累积历史、清洗:根据数据业务需求及稽核和审计要求保存历史数据、数据清洗;
2)CDM层
- 组合相关和相似数据:采用明细宽表,复用关联计算,减少数据扫描。
- 公共指标统一加工:基于OneData体系构建命名规范、口径一致和算法统一的统计指标;建立逻辑汇总宽表。
- 建立一致性维度:建立一致的数据分析维表,降低数据计算口径不统一的风险。
3)ADS层
- 个性化指标加工:不公用性、复杂性(指数型、比值型、排名型等)
- 基于应用的数据组装:大宽表集市、横表转纵表、趋势指标串。
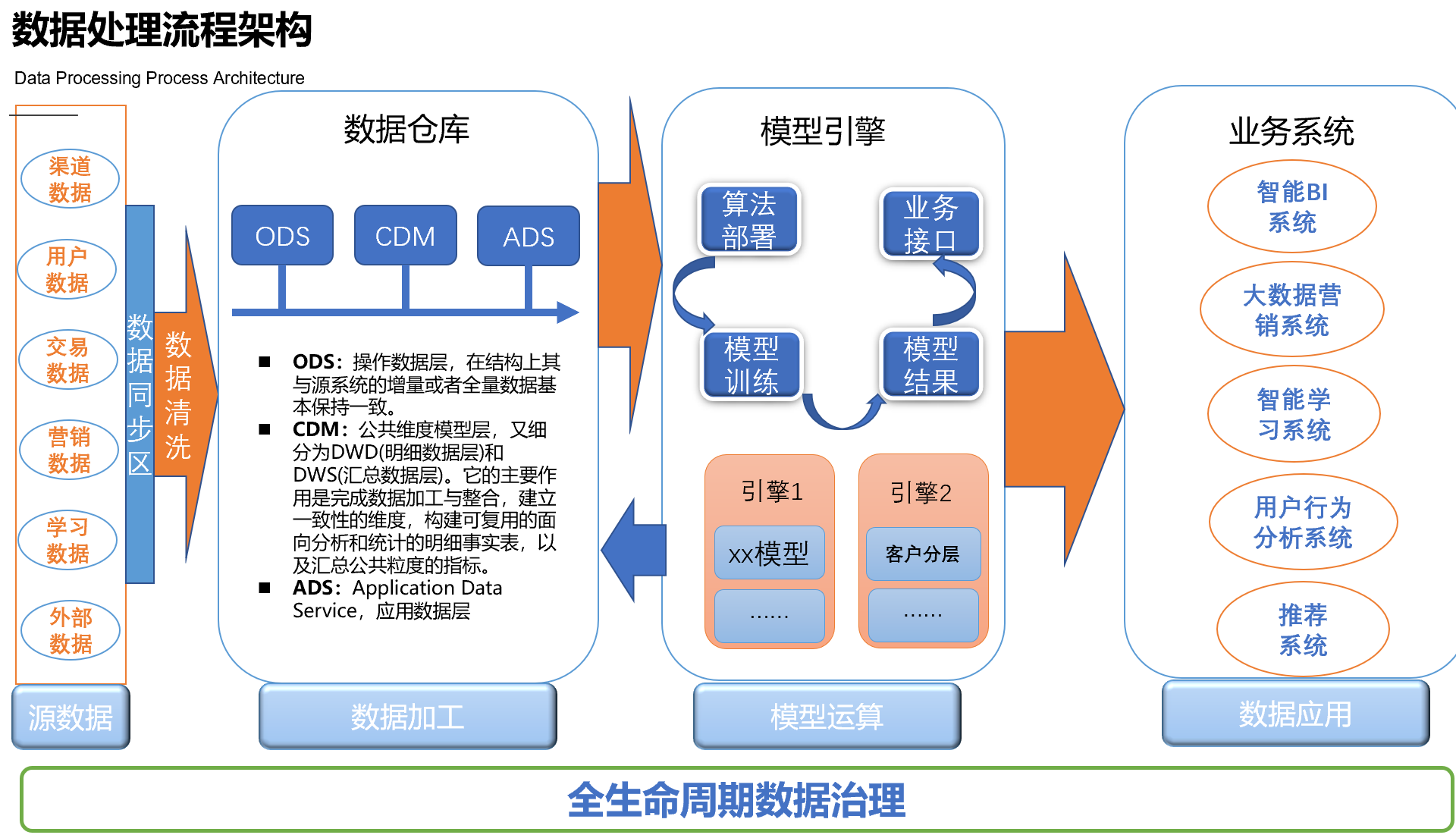
3. 数据处理流程架构
数据处理流程主要包括源数据同步清洗、数据处理加工、模型运算和数据应用。基于在线在线教育公司的业务特点,源数据主要包括:渠道数据、用户数据、交易数据、营销过程数据、学习数据、外部第三方数据等。
模型引擎包括离线计算引擎和实时计算引擎两类,需要满足算法(或规则)部署、模型训练和上线、以及对其他业务系统提供接口服务的能力,比如为CRM系统提供多算法的线索实时分配、用户画像分层等服务。在数据的汇聚、加工生产、应用的全流程中,全生命周期的数据治理不能忽视,因为数据的准确定、完整性、一致性直接影响业务对数据系统的可信度。
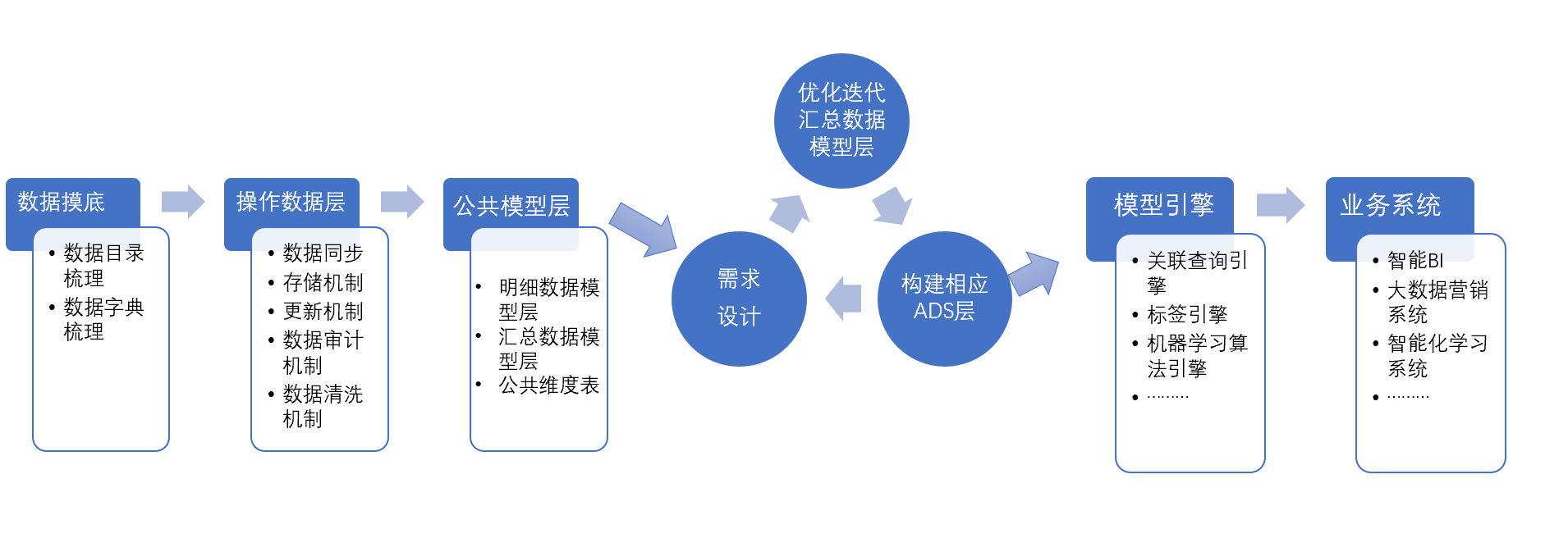
4. 从0~1构建大数据平台的Road Map
笔者结合自身在推进大数据平台建设过程中的经验,给出以下路线图供大家参考。
三、数据建模及设计规范
1. 数据模型选型及举例
维度建模常见的模型有星型模型、雪花模型和星座模型三种,数据仓库设计一般采用星型模型。
星型模型是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。事实表的非主键属性称为事实(Fact),它们一般都是数值或其他可以进行计算的数据。
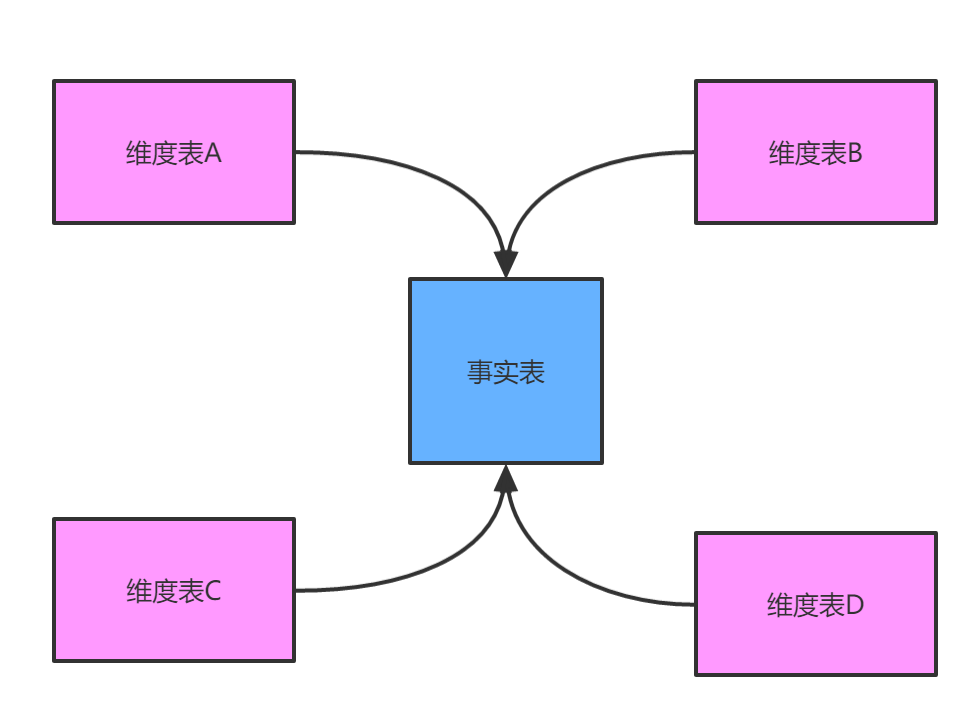
事实表:表示对分析主题所属类型的描述。比如“昨天早上张三在环球网校花费1000元购买了一个一建零基础畅学班课程”。那么以购买为主题进行分析,可从这段信息中提取三个维度:时间维度(昨天早上),地点维度(环球网校), 商品维度(一建零基础畅学班课程)。通常来说维度表信息比较固定,且数据量小。
维度表:表示对分析主题的度量。比如上面那个例子中,1000元就是事实信息。事实表包含了与各维度表相关联的外码,并通过JOIN方式与维度表关联。事实表的度量通常是数值类型,且记会不断增加,表规模迅速增长录数。
2. 数仓表设计规范
1)表命名规范
数仓各层表命名规范如下图所示。

2)字段级规范
新增指标的命名参考已有字段命名方式,避免出现同一个字段,10个人有10个命名方法。
字段分类包括:明细,维度,指标,时间,代码,标志位,命名规范如下:
- id结尾表示编号,部分维度编号对应含义需关联数仓相应维度表获取含义;
- name结尾表示名称,多与id对应,解释其含义,独立的以name结尾的字段;
- code结尾表示代码字段,对应含义部分可在文档直接查看,部分需关联数仓代码表获取;
- time结尾表示时间字段,格式为yyyy-mm-dd hh:mi:ss,从源系统获取,不作处理;
- money结尾表示金额,都为系统相应交易金额;
- is_开头表示标志字段,此字段只有0,1,含义:1是,0否;
- 除以上规范字段,其他字段根据中文含义对应生成英文字段,多为一些属性字段,意义不大。
四、大数据平台技术架构及模块简介
在大数据平台的建设过程中,笔者和公司大数据架构师共同研究探讨后给出的技术架构如下图所示。
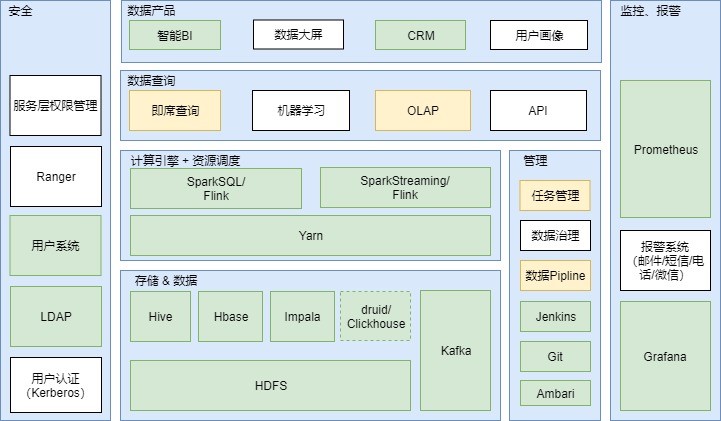
1)安全模块
作为数据平台来讲,保障数据安全始终是第一要素。 安全体系的建立主要包含以下几个方面:
- 数据安全规范、安全等级制定
- 用户系统
- 基础组件层权限管理
- 服务层权限管理
- 用户认证
- 秘钥管理
- 流程审批
- 数据加密脱敏
- 审计
2)监控模块
数据安全之外,服务的稳定性算是平台的第二级指标。好的监控体系可以帮助预测风险定位问题。例如:
- 提前预判磁盘容量
- 定位内存、CPU资源问题
- 发现异常任务
- 节点宕机等问题
- 查看该各服务负载,评估资源
3)存储模块
存储模块属于基础组件模块,主要采用hadoop生态系统的相关组件。面向不同的应用场景选择一种组件,例如:
- hive: 离线数仓
- HBase:KV存储,可用于高度聚合后的固定指标,应对有较高并发请求的场景
- Druid:面向OLAP场景,能够提供亚秒级、较高请求量且需要钻取能力的OLAP功能
- Impala: 在数仓数据基础上提供更高效的查询分析能力,适合即席查询场景,但是并不能处理更高的请求量。
4)计算模块
Yarn做统一资源管理,Spark或者Flink都可以作为统一流、批处理框架。或者阶段性允许两者并存。
5)管理模块
数据治理: 数仓管理数据的主要平台,包括:
- 元数据管理
- 数据质量管理
- 血缘关系管理
- 数据安全、权限管理
任务管理:
离线任务管理、调度:
- 包含管道任务、SQL任务、Shell任务等形态,数仓场景中SQL任务占整体任务的绝大多数
- 需要基于SQL自动生成任务之间的依赖关系,并且按照任务之间的依赖关系和优先级调度任务
流式任务管理:
流式任务发布、监控、重启等操作
五、写在最后
致此,在线教育大数据营销平台实践第一篇文章已经结束,下篇文章笔者会阐述在大数据平台建设的初期,如何将数据仓库和神策分析系统(sa)相结合来快速满足运营人员对数据分析的需求,开启数据化运营战略落地的序幕。
本文由 @Tigerhu 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。












