化繁为简用户研究:维度、关系、洞察
用户研究复杂程度众所周知,本文分析了用户研究的维度、关系、洞察,使得用户研究程序化繁为简。

“东关联、西牵扯的,用户研究太难了呀 ToT!”
无论是生活还是做项目,凡涉及人的事,都非凡事。
最近在做一个对棘手群体做需求挖掘项目,对我的小脑瓜是一个不小的挑战,接下来将按照维度→关系→洞察的顺序,分享下我的心得。

- 维度: 总结了一些日常项目所涉及的维度,在研究规划时可以做点参考。
- 关系: 对多层维度间的关系进行了部分解读,在制定用研材料或结果分析时,可以参考关系图来整理思路。
- 洞察: 讲述了我对如何分析用研结果的一些思考,学生时期还是有些经验壁垒,之后尽力修改扩充。
一、维度
在数据世界重建用户。
“测不准”和“意识鸿沟”这两层雾霭,让我在数据世界中重建用户时,经常惶恐是不是在闭门造车。
一旦开始了描述,我就再也接触不到真正的用户。
所以能做的就是,尽可能让数据堆砌的骨骼完整、健全,避免缺胳膊少腿。
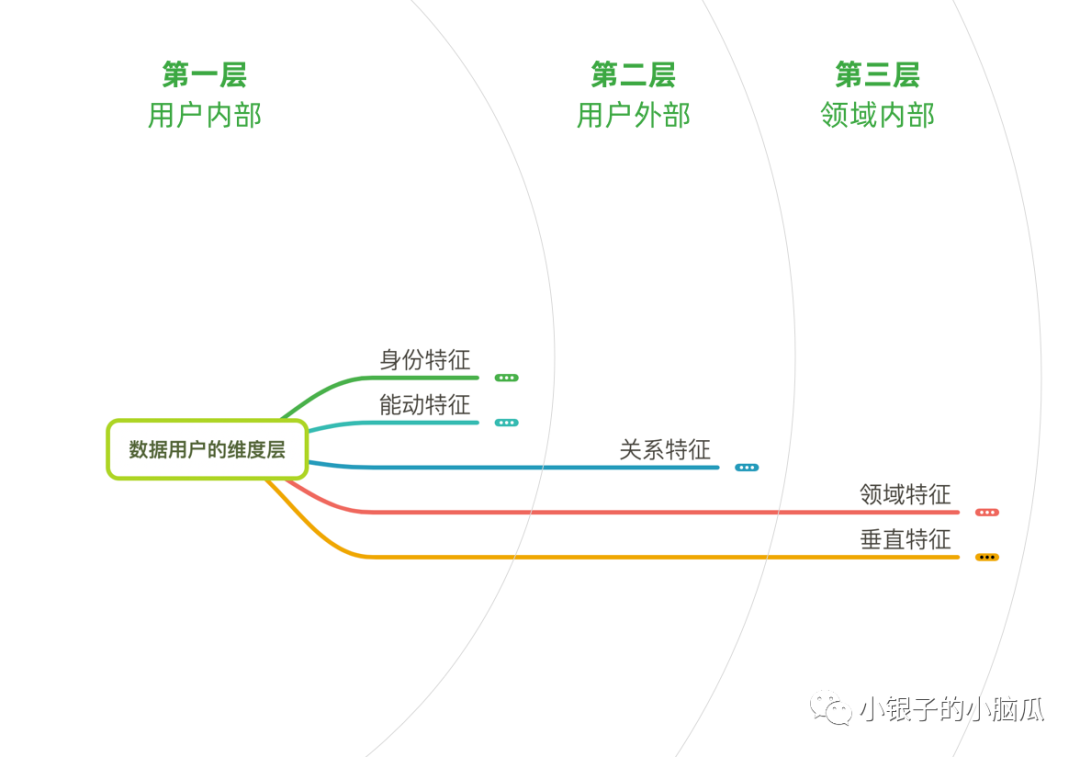
遵循着MECE法则,我将数据维度分为以下五类(不同业务领域的涉及维度可能会有差异),由上至下,用户的数据维度逐渐与业务逼近。
为了方便描述,我将平常研究中的行为、心理、意图等方面归结为能动特征:
- 身份特征:他是谁?他什么样?他在哪里?
- 关系特征:他和谁关系密切?和谁利益相关?在什么组织?
- 能动特征:他在想什么?感到什么?做了什么?想做什么?
- 领域特征:在相关领域他有什么特点?经验如何?
- 垂直特征:与产品强相关的属性、行为、意图等。
如果身份特征是数据用户的昵称,那么能动特征是他的灵魂和心脏,关系特征是他的存在影响力,至此就完成了他的基本组建。
不过接下来才是重点——领域特征和垂直特征:领域特征一般会在问卷设计中进行调研,通过大数据分析渠道、竞品、经验、体验,来寻找产品的机会缺口;而垂直特征比较复杂,大体上和能动特征类似,以此来收集需求、方案所需数据。

二、关系
用户的数据关系层次,如果说维度是他的骨骼,让他健全;那关系就是他的组织,让他可以行动站立。
前面提到了五类用户数据维度,实际上它们的相互关系也是有亲疏差别的,简单的将它们分为三层关系单元:用户内部层、用户外部层、领域内部层(如果业务需要特别复杂的用户模型,也可以考虑领域外部层,即其他相关领域的用户经验、体验等)。
接下来我将结合一点面向儿童群体的项目经验,进行关系的示意分析。项目背景是挖掘儿童群体在某些领域内的需求,寻找语音交互的介入契机。
1. 用户内部层
【身份】与【能动】是用户内部特征,也是很多关系源起的地方。
儿童的身份实际上包含了两层:个体身份与家庭身份——这是因为实际场景中,儿童经常以家庭单位进行活动。
【身份】会影响他的行动、思考、感知、意愿,也就是【能动】;同时会影响儿童与其他组织单位的【关系】,如学龄儿童可能参与某些培训课程,与培训机构就建立了联系。
进一步来说,处于头部城圈的群体,接受外教辅导的可能性也会提高。后面会介绍如何从错综复杂的数据中提炼洞察。
既然身份分为了两层,那么相应的【能动】也将分别从个体和家庭视角描述。这层分析直接导向【垂直】痛点/需求推导、方案可行性基础等价值,可使用诸如用户旅程图、任务分析网格、触点分析等方法。
2. 用户外部层
【关系】本身就蕴含了不同单元间的关系,属于用户外部特征,多元用户关系可能会急剧增加需求场景和任务设计的复杂度。
需求场景
前面提到了儿童身份的双/多重性,强调的是最终使用者和体验者。实际上,儿童/用户在不同场景被赋予或主动扮演着不同角色:在家庭的孩子、在学校的学生、在朋友中的孩子王…
不同角色具有各自的【能动】特征,是导致【垂直】场景和需求的分化的一大原因。设计时可以区分用户身份、场景角色、任务环境来进行需求的整理,如:儿童-身处家中-作为学生-在做作业-准备查询相关知识。
任务设计
双/多重身份除了增加了需求视角,也引入了一种特殊的任务设计——多角色交互。
这表示用户所在组织的其他人员也牵扯进了产品使用场景中,此时的设计就需要考虑不同角色的【能动】,以及在与【垂直】产品交互后的一系列联动反应,可以通过设置多泳道来提高流程图的适应性。
3. 领域内部层
【领域】和【垂直】是限定语境中的用户剖面,并且部分特征是在“测量”后才显现出来,如用户对某方案的认可度、对某功能的卡诺评价。
虽然这部分数据对业务有直接指导意义,但如何保证准确度和时效性,除了我们平常的解决方案——绿野仙踪、单/双盲实验等外,从数据用户的多维框架中也可以略窥真相。
综上,根据我目前的项目经验,绘制了各层内/间的主要流动关系,如下图。
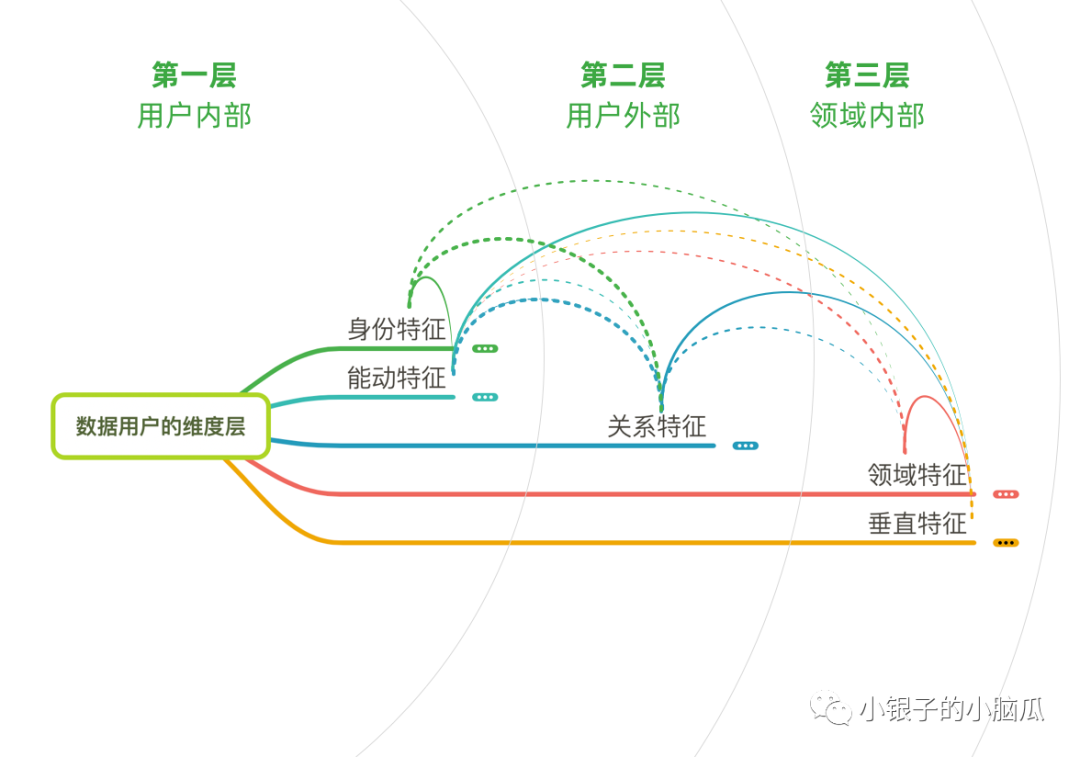
在具体研究中,我认为需要在“测量”后进行链路影响分析,比如身份→关系→能动→垂直→能动→关系→……甚至可能形成闭环链路。
具体来讲,比如方案落地后,需要定期更新用户研究数据;并且对比短期和长期的差异之处,以验证研究的时效性,防止“蝴蝶效应”引来的巨大偏差。
三、洞察
从02关系可见用户真是一个难以捉摸的小妖精——他由我创造但是,独立且变化多端。
这节将具体谈谈如何从调研数据中得到价值洞察。
1. 单维度数据:分布与区分

01维度中各维度经过转化处理均可进行值分布的观察。简单的如性别、地区、年龄;需清洗数据的如心理/意愿,将末端数据归纳为具有趋势性/代表性的几个值——接受型、抵抗型、主动型…
分布
对数据分布的观察,除了比例分布外,还有地理分布、转移分布(随着时间或条件变化,值的相互转化)、均衡分析(值数据的极化倾向)等。
区分
得到了维度值的集合后,可以分析不同值所对应的其他维度数据是否呈现区分性,如分析不同年龄段儿童的【关系】有什么区别。
2. 多维度数据:近似与关联

涉及到多维多层的复杂结构,可以试图从近似和关联的角度分析。
近似
上文提到对单维度数据的区分性观察,如果在多维数据的观测范围中,发现单维度的几个值区分性较弱。比如3~4岁儿童和4~5岁儿童在【能动】和【领域】上几乎一样,那么就称这几个维度的值具有近似态,可以合并处理。
当发现某一近似态需要多个维度值的约束。比如上一个例子中,除了儿童年龄,性别也是重要的影响因素,这样就能提高结论的力度和准确性。
关联
数据并不是孤立存在的,作为数据的载体——用户,将多维度数据粘合绑定在一起。不同的值赋予了用户千姿百态,而总有一些值就像好哥们一样,有你就有我。
打个比方来说,儿童调研中发现很多男孩喜欢车,他们也更容易购买/下载和车有关的产品,【身份】就和【垂直】有了关联,但是这个结论需要限定在特定年龄段的条件下。
实际分析中,可以先洞察关联性的维度,再完善条件来提高效力。
3. 数据源用户:聚集与差异
数据毕竟是冷冰冰的,用户才是产品的上帝。
上帝(Persona)有几个?怎么区分他们?可以满足全部上帝吗?谁才是帝中之帝?
聚集
说实话我没有看过很多用户画像的教程,因为我认为在实际项目中,我才能真的理解应该怎么区分用户,也可能是因为没看教程,所以我苦恼了好一阵子:
- 按人口学属性?
- 行为习惯?
- 或者痛点需求?
- 还是方案偏好?
最终得出了结论:按照项目诉求和项目阶段,视情况而定。
就像我最近做的一个项目,已经上市了,但是需要继续挖掘需求,并且指导产品设计(最好可以直接开干的那种);那么就以需求类型和方案偏好来区分用户。
这一个大坑,需要我有更多经验和文章篇幅,这次就不展开啦。
差异
既然分类好了用户,那么差异是显而易见的,根据前面的框架可以细细道来。
棘手之处在于如何在突出核心/细碎差异的前提下,概括几类用户,我想这块就需要结合强大的可视化能力了——不过我目前还做的不够好。
以上就是我从小就感兴趣的话题,但直到现在也是有些懵懂。
用户研究涉及的内容太多太杂,这样写下来,很多地方囿于我的经验知识,都比较“空虚”。
所以,诚请建议哦。
数据的荆棘密林
可能会勾破行者的衣衫,甚至皮肤
我尚未在森林中驰骋
暂且将这些被小树丛扇开的伤疤
称为勋章
勉力前行——《森林》
作者:c.🐾,微信公众号:小银子的小脑瓜
本文由 @c.🐾 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自正版图库 图虫创意








