如何做好互联网内容安全的音频审核?
编辑导语:当下互联网内容的存在形式越来越多样,为了保证互联网内容安全,内容审核这一流程就显得愈发重要。那么,就音频领域而言,其内容安全审核应当如何操作?本篇文章里,作者就如何做好互联网内容安全的音频审核做了总结和梳理,一起来看一下。

一、背景
随着《互联网信息服务管理办法》《网络安全保护法》《网络信息内容生态治理》等法律法规颁布,且网信办及其他监管部门对互联网信息内容管理的专项也愈来愈多,目前互联网信息形态主要为文本、图片、语音、视频。
如何让这些信息中没有违规内容,这将会对于所有将要通过互联网进行信息露出的单位和平台提出挑战。下面我将分享一个实现好互联网内容音频审核的思路,供大家参考指导~
二、目标、场景及流程分析
1. 目标分析
音频内容审核的实质是要完成高效精准发现违规内容,由于数据量大,高效的主要是通过机器完成需要算力资源及风控模型准,而精准则要抽检审核到位,对抗强度大。

2. 场景及流程分析
目前互联网上的有关语音审核的场景主要为IM通讯、音频点播、音频直播、多人音频互动等,主要流程为语音生后,由于数据处理量大,目前业界的方式是会经过机器审核(实时系统)结合人工运营审核的方式,以达到审核目标。
实时系统中由于数据量大,目前会内置关键词表+简单策略+简单特征模型进行过滤的方式;人工运营中由于人工成本有限,要达到人进行大数据量审核也不太现实,所以一般会采取数据抽检+前台巡查+蓝军对抗的形式。
具体流程如下图:

三、实现路径
1. 实时系统——相关技术流程
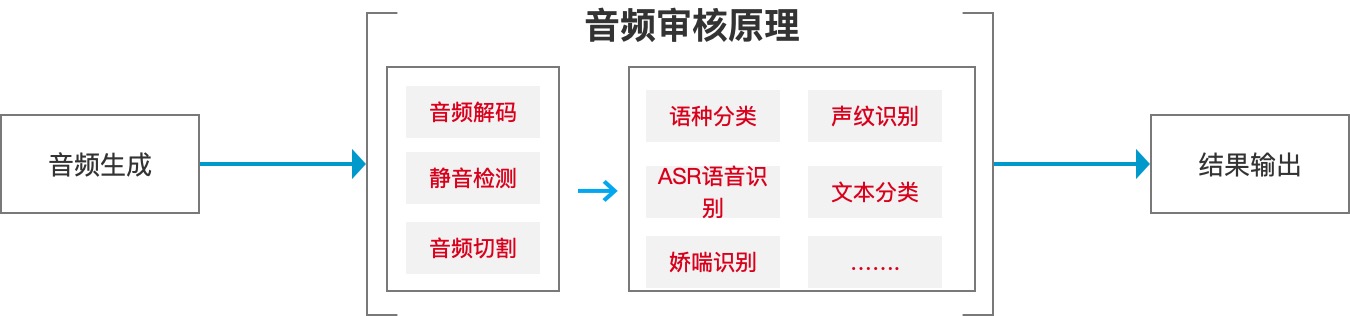
由于音视频和互联网文本的区别,所以在相关技术识别上有一些出入,基本流程为用户语音生成后,经过音视频解码、静音检测、音频切割后,再进行相关算法及模型的运用进行内容判定。
主要有对音频进行语种识别的语种分类、对声纹的识别区分是什么人物的、语音识别、文本分类为对语音识别后的文本进行分类、最后还有对娇喘类语音的识别,经过这一系列相关算法及模型的判断后,最后得出音频信息的正常与否。
下图为基本流程:
2. 运营支持方式
1)数据抽检
关于对音频数据的抽检,这一项工作分成常规的和非常规的。
常规的主要为通过随机抽样算法(如分层抽样、水塘算法、随机和欠采样等)进行数据的抽查,以感知整体数据的健康质量;非常规的则为专项,针对特定主题的特定数据进行巡查,以提升数据在特定主题下的审核程度,具体主题选取主要根据监管动向及业务需求来定。
关于抽查数据需要注意的点:由于违规信息有严重程度区分,所以对于重点人物的数据以及重点账号,会提升巡查的力度。
具体巡查流程为:

2)前端巡查
前端巡查主要指站在用户视角进行巡查,流程为根据巡查目标,进行内容审阅后,并对结果进行记录。
3)蓝军对抗
蓝军对抗的目标为测试目前系统和运营的健康程度,一般会以模仿真实用户的方式产生数据,以测试实时审核系统及运营流程的健康程度。
3. 运营支持流程
专项流程:
专项的流程为根据运营支持的反馈分析,开始启动专项,随后对专项数据进行解读和提炼(关键词、规则策略、模型特征积累),第三步为对第二步进行提炼出来的内容进行灰度测试,最后为上线至实时审核系统。
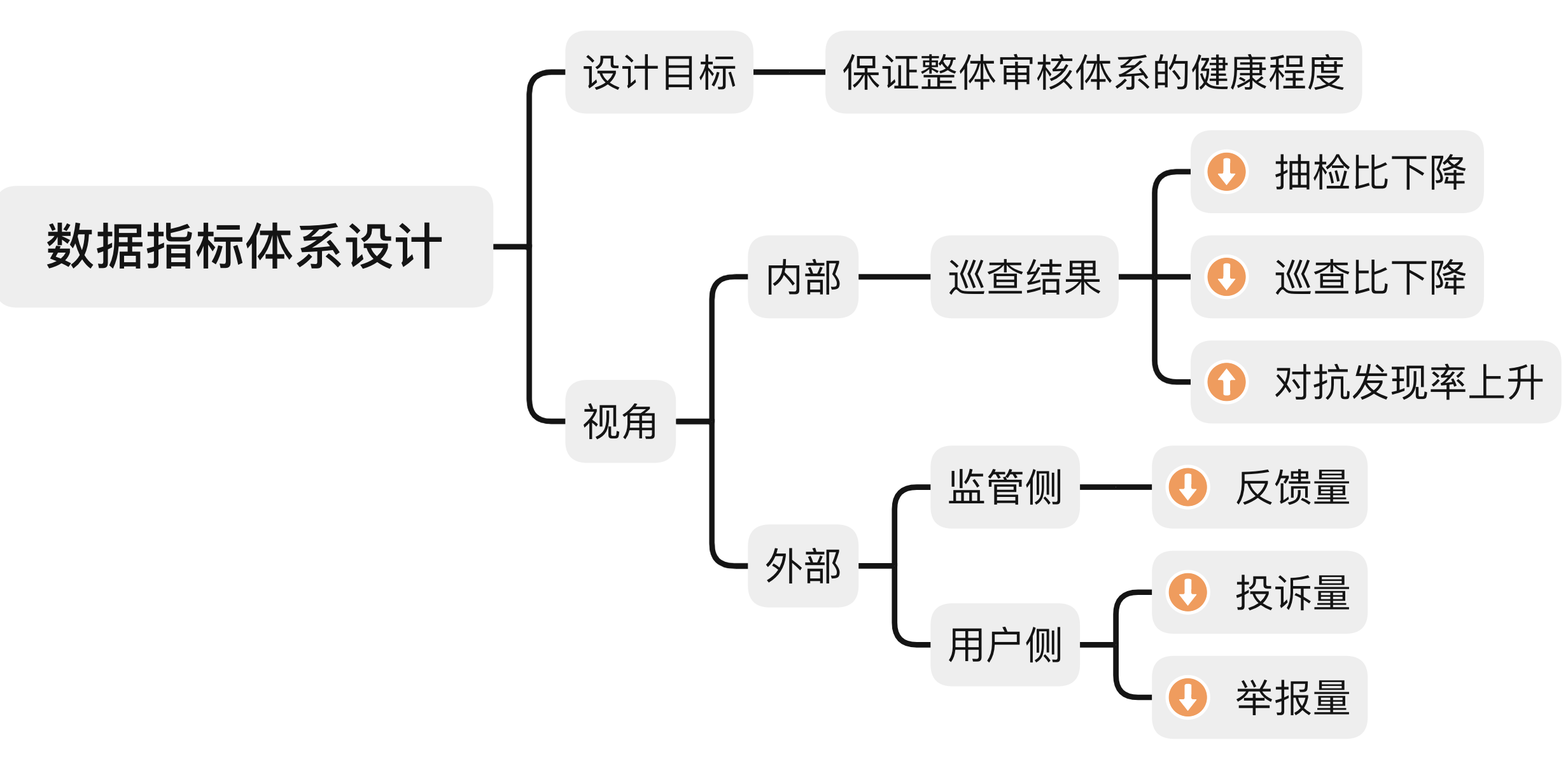
4. 内容安全的有效性指标体系设计
1)指标设计目标
保证整体审核体系的健康程度。
2)设计视角
设计分成内部和外部视角,内部主要根据抽检比、巡查比、对抗发现率几个指标,外部视角主要根据监管侧的反馈和用户侧的投诉及举报数量去判断。
四、总结
对于音频审核的主要是以人机结合的形式进行,系统审核主要以关键词表、简单模型、简单策略形式,运营审核主要是以抽检的形式进行,为保证整体审核体系的健康程度,要注意数据指标体系设计。
本文由 @贤锋_Blue 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议






