新闻的个性化推荐机制
本文从内容画像、用户画像、召回和排序、推荐策略四方面分析了新闻的个性化推荐机制。

关于个性化推荐,我的理解是:按照每个人的喜好,在合适的时间、合适的场景、把合适的内容以合适的形式呈现在用户面前,满足用户的需求。 那么这里就涉及到了三部分,用户——算法和策略——内容。
下图是一个简单的新闻推荐组成部分:

新闻推荐简图
我们的“人”和“物”都是复杂的,需要用我们理解的符号去把他们描绘出来,让我们的程序理解。
一、内容画像
1.1 新闻文章来源
做新闻,我们首先要有文章源。文章的来源,一般有三部分:
- 机器在各个资讯网站抓来的文章。
- 公司编辑自己写的文章。
- 入驻作者写的文章。
1.2 内容分类体系介绍
有了文章,我们需要把文章分门别类的放在一个内容池子里。
那么该如何分门别类呢?这里就涉及到了内容分类体系。
在我们逛淘宝的时候,会有各种物品的分类,比如家居,比如图书,比如衣服。
同样的,文章也会有分类。当我们打开一个资讯app,比如头条吧,就可以看到导航栏有:“军事”“历史”“时政”等等。


京东和头条的前台分类
这是我们在前台可见的,其实在它的背后,有一套庞大的分类体系,下面我们来说一下。
分类体系一般有三种形式:结构化,半结构化,非结构化。
- 结构化的分类: 层级分明,有父子关系,分类间相互独立,比如科技-互联网-人工智能。
- 半结构化的分类: 具有结构化的形式,同时也有一些不成体系的分类,我认为知识图谱算是一种半结构化的分类体系。
- 非结构化的分类: 分类比较灵活,没有明确的父子关系,如独立的关键词标签。
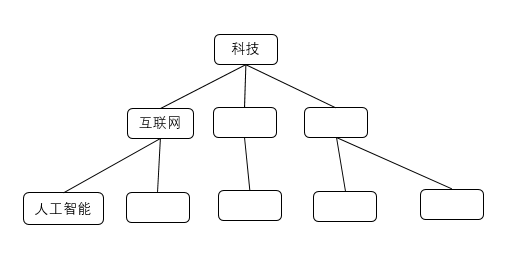
结构化分类体系
知识图谱
1.3 常见问题和分类原则
- 一级分类=二级分类的情况:如美食,宠物的一级二级分类名称相同。
- 二级分类不够全或分的较粗:如历史被分为“古代史,近代史,现代史”。
- 一些分类较杂:如“科学探索”分类下可能各种内容都有。
- 一些二级分类归属不够合适:在有一级分类“职场”的情况下,“职业培训”被放在了“教育”。
- 一些文章没有好的归属,如办公软件的学习类文章没有归属。
- 人工智能分类下的文章有一些是玩偶。
在做分类的时候我们会遵循一些原则,这里我来说一下结构化分类体系搭建的原则。
- 相互独立:各分类间内涵应当相互独立。
- 完全穷尽:各分类应当完全穷尽列举,下一级分类可以组成上一级分类的全集。
- 命名应当短小易懂。
- 命名应当准确无歧义。
- 命名具有内容代表性。
- 分类粒度应当适合,不能较粗或较细。
- 每个分类下三级分类不能过于庞大。
- 释义应当相对简单明了,不应长篇大论太过专业。应当从c端用户角度考虑,使标注的人可以一下子理解分类的内涵,而非必须具有专业知识才可分辨,否则不符合用户思维习惯。
1.4 构建分类体系
那么接下来我们该如何去做分类体系呢?有两个思路:
1)让程序根据站内用户浏览记录,抓取出浏览比较多的一些关键词,我们按照这些关键词去整合分类。
但从实际操作来看,用户的兴趣分层是:(一二三级)分类——主题——兴趣点——关键词的层级,
举个例子: 科技(一级)——互联网(二级)——人工智能(三级)——智能办公(主题topic)——语音助手(兴趣点poi)——小爱(关键词)
如果我们根据关键词往上汇合分类,会比较难实施。
2)人为的定义出一二三级分类。具体操作步骤如下:
- 了解每个一级分类内涵,查阅大量相关网站,如搜索历史垂类网站,查看网站内容和分类。②根据网站分类,逐一列举,从日常用户兴趣角度出发列举三级分类粒度的分类词。
- 从三级分类合并二级,以及从二级分类拆分三级分类双向进行整理。
- 对分类给出释义和边界,以便标注人员区分。
那么我们如何保证三级分类下的文章充足?以及如何保证人工分类的准确性呢?
我们采取了两个措施:
- 针对问题1:我们把三级分类词,如“人工智能”放到研发的文章召回系统,进行搜索——可以看到以“人工智能”为关键词可以召回的文章内容及数量,以此来判断此三级分类是否文章充足,进行调整。
- 针对问题2:因为一部分的文章首先要经过标注团队的人工标注,在标注的时候,标注员会反馈具体某个三级分类存在的问题以及不合理性。此环节产品,运营,编辑都会介入,对于不合适的三级分类会进行修改。
1.5 人工标注和机器学习
当分类体系完成后,接下来是标注环节。
标注团队标注一定数量的文章,算法团队的工程师会用算法对人工标注的样本,进行有监督的机器学习,把剩余的文章用程序给它标上对应的分类。
负责这部分工作的工程师,会用多种方法来对文章进行机器学习,比如有ABC三种。用三种方法对新的文章样本进行分类。
然后让标注员对算法标分类的文章进行校验,从而得出三种方法为文章分类的准确性,公式如下:
标注员分类和机器分类相同的文章数量/总的文章数量=机器标注准确率
之后算法工程师会对标注不准确的文章继续进行学习,不停的迭代优化算法。
针对外部抓取的文章,算法工程师也会用这套方法对他们标记分类。到这里,我们的文章就可以分门别类的被放在内容池的不同地方了。
二、用户画像
2.1 什么是用户画像
当有了内容的画像,我们也需要用户的画像。那什么是用户画像呢,我认为是对用户这个客观实体的描募。
比如我对自己进行一个总结:男,175cm,65千克,产品经理,26岁,月薪25k,无车……等等。
这就是我的用户画像。
那么为什么做推荐需要用户画像呢?
是因为 只有当我们了解了一个人,才能把她最想要的给她。
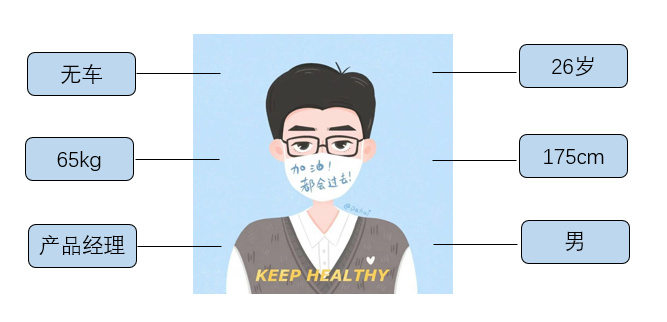
用户画像
2.2 用户画像要基于业务存在
做用户画像第一步要基于业务,也就是说用户画像是要对具体业务场景来服务的。
比如个性化推荐,精准营销,数据分析,活动运营等等。
所以第一步需要了解业务场景以及各岗位的同事对画像的需求。
2.3 搭建用户画像体系
在了解之后,我们会开始搭建画像特征的体系,这里说明一下,特征是一点点获取、建立和利用的;但特征体系在一开始需要搭建出来,尽可能的囊括各业务场景的需要。
虽然某些特征可能在初始阶段还没有建立,但需要根据业务需求先列举出来;以便在做画像平台功能框架搭建的时候,不会因为没考虑到某类特征,而使后期画像平台的功能框架无法兼容。
以下我从: 基本信息、兴趣爱好、行为特征、社交和心理、消费与模型 这5个方面做了一个简单的新闻资讯用户画像体系。
一般来说在建立特征体系的时候, 应该包含以下表头:一级特征分类、二级特征分类、特征描述、特征字段、特征值类型、特征来源、特征时效、最近更新内容、特征示例。
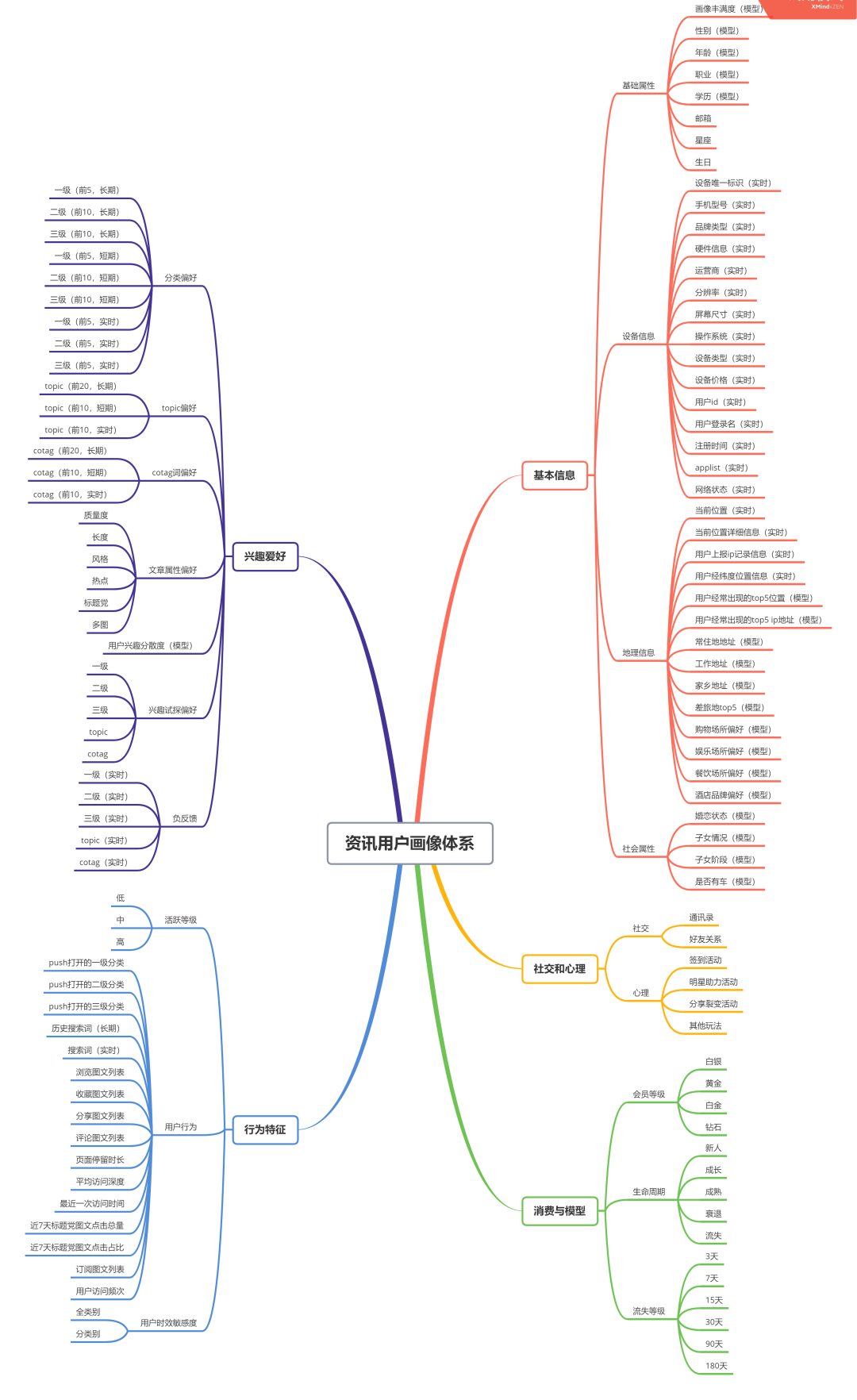
资讯用户画像体系
2.4 画像特征介绍
用户画像主要有两块:事实特征和模型特征。
事实特征是用户的基本信息,以及他在app内产生的行为:如用户的设备信息,地理位置,主动填写的性别,年龄,以及在客户端浏览文章中产生的点击行为等等。
模型特征是我们基于用户的事实特征,制定一些规则建立的:如用户流失等级,用户消费等级,用户满意度等。
从时效性上来划分,画像特征分为长期,短期,实时。
长期特征如:用户基本信息里面的一部分特征,性别,年龄,生日,账号,设备等等。
短期特征如:用户的兴趣爱好和行为特征,当然这里要说明用户的兴趣爱好也分为长期和短期,但这个是相对的,兴趣爱好仍然被我放在短期特征内。
实时特征如:用户的实时地理位置,实时网络状态等等
2.5 画像特征获取
那么画像的特征数据要怎么获取呢?
①事实特征里的一部分,是我们通过用户主动填写或埋点来获得的,比如用户主动填写的性别,比如埋点获得的用户浏览时长。
②另一部分是根据业务指标来对事实特征进行复合计算,如:用户文章平均阅读时长=用户阅读的总时长/用户阅读的总文章数。
如果用户没有填写某些信息,或者我们获取不到怎么办呀?
一般我们有两种方式:
- 引入第三方数据补全用户画像特征。
- 算法工程师会把填写了性别的用户作为样本,按照男女分别进行有监督的机器学习,从而对性别特征不完整的用户进行模型训练,得出这部分用户的性别,但这里是一个概率值,比如A用户性别:男70%,女30%。
说完了事实特征,我们来说模型特征。
模型特征则需要我们去制定一些规则,为我们的业务场景服务,比如用户流失等级,运营可以针对不同流失等级的用户上不同的运营策略。我们规定:
- 3天未打开新闻客户端的用户,流失等级为A;
- 7天未打开新闻客户端的用户,流失等级为B;
- 15天未打开新闻客户端的用户,流失等级为C;
- 30天未打开新闻客户端的用户,流失等级为D;
- 60天未打开新闻客户端的用户,流失等级为E;
- 90天未打开新闻客户端的用户,流失等级为F(流失了)。
2.6 用户画像平台
搭建好用户画像特征体系之后,我们需要有个可视化的平台,用户画像平台。在功能上一般应分为四部分。
- 群体画像: 我们可以通过特征圈选人群。比如用性别这个特征,分男女去看,不同的用户群体,喜好的文章一级分类有什么区别。
- 单用户画像: 当我们输入用户的id,可以看到这个用户所有特征的详细信息,同时也需要有个用户画像丰满度的总评分。
- 场景赋能: 比如我们可以圈选一部分目标用户,对他们进行广告投放,看这批用户后期在每一个环节的转化。
- 权限和特征管理: 画像平台应当对不同岗位的员工设置不同的权限,同时也需要对用户画像的特征进行管理,支持增删改查的操作。
三、召回和排序
3.1 什么是召回
首先我来解释一下什么是召回,通俗易懂的理解就是: 根据用户的一些“条件”把符合这些“条件”的文章从广阔的内容池里召唤出来,放到一个小的池子里。
3.2 文章的信息抽取
在召回前我们会做一些准备工作。
第一步是信息的抽取,文章是由html语言编写的,有<title>有<head>有<body>,是成对出现的,都是半结构化的数据。
程序对文章进行信息抽取的时候,也是按照这样的结构,用深度优先遍历,按照栈结构先进后出的特点来抽取的。
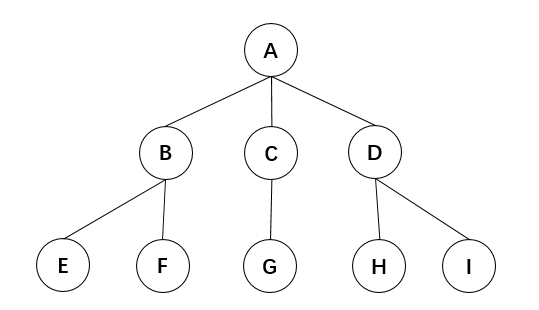
深度优先遍历 这里我来说一下,如果是学计算机的同学,在《数据结构》这门课程中会学到。
如下图是一个树结构,我们需要把每个节点都走一遍,“深度优先”顾名思义就是纵向最深,那么我们按照从左到右深度优先的规则,走一遍。
得出的顺序就是:A-B-E-F-C-G-D-H-I。
那么为什么抽取文章信息的时候,要用深度优先遍历呢?
就是因为上文提到的文章的结构是有标题有正文,在html语言中代表标题和正文的标识在每个部分的前后出现,相互一层层嵌套,采用深度优先遍历,抽取出的信息结构不会混乱。
树
抽取后,程序需要识别出哪些是正文,哪些是广告。对于我们人来说,可以轻易辨别;但是对于程序而言,需要一些规则去让程序识别出来——
比如我们用投票方法来对文章文本块进行打分。
规定文本块的位置:在页面中间的为3分,在页面左右两端的为1分,在页面底部的为2分。
再比如我们规定文本块的长度:不同的长度给不同的分值。
3.3 文章的分词
抽取信息之后,我们要对文章内容进行分词,对于我们人来说,我们可以根据学习经验对文本进行断句,但机器却并不知道。
所以这里我们也有一些方法,下面来介绍3种。
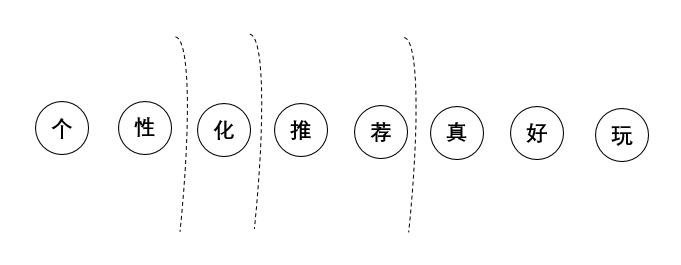
1)字典-最大前缀
首先我们有一个字典集,这个里面包含我们所有的词语,当机器“读”一句话的时候,例如“个性化推荐真好玩”
按照字典里面存在的词语去从左到右进行匹配,“个性”是一个词,做个记录,继续往下。“个性化”又是一个词,再做个记录。“个性化推”不是一个词语,继续向下“个性化推荐”是一个词语。
直到找到最大的词组。
2)N-gram分词
这个N代表的就是对这句话用几个字去拆分,比如N=3,原句就会被拆分为“个性化”“性化推”“化推荐”……。
3)基于统计学的分词
如贝叶斯,根据语料库的历史信息,分析当一个汉字出现时,另一个汉字出现在它后面的概率,从而进行分词。
字典-最大前缀树
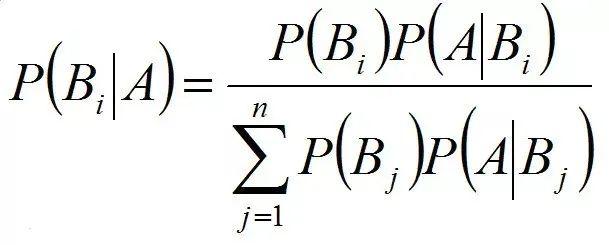
贝叶斯公式
3.4 文章的过滤与排重
分词后我们会进行一波过滤:敏感词过滤、低质过滤、排重。
敏感词过滤:会根据既定的一些敏感词列表,把包含这些敏感词的文章过滤掉。
低质过滤:会根据机器学习的历史低质文章算法,加标注人员标注的低质文章,对文章进行过滤。
排重:这里要对相似度较高的文章进行去重。我们来介绍两种方法:
1)I-Match算法
假设有A和B两篇文章,分词后,我们首先统计出两篇文章的高频,中频,低频词。去掉高频和低频词。比较A和B两篇文章中频词汇表的相似度,卡一个相似度的阈值。
2)Shingle算法
假设有A和B两篇文章,A是:我困了晚安我睡了,B是:我累了晚安我睡了。
shingle会把A文章拆分为“我困了,困了晚,了晚安,晚安我,安我睡,我睡了。”;B文章拆为“我累了,累了晚,了晚安,晚安我,安我睡,我睡了。”
两篇文章的相似度=重复词汇量/(A文词汇量+B文词汇量-重复词汇量)=4/(6+6-4)=50%,卡一个相似度的阈值。
对相似度达到阈值的文章进行过滤,仅留一篇,比如按照发表的先后顺序留,或者按照文章质量的判定留等等。
3.5 文章的召回
召回
1)基于人口属性的召回。
如根据用户的地理位置召回的文章。
2)基于用户兴趣的召回
如根据用户对各分类文章的兴趣程度进行召回。举个例子:我们选取用户近7天内点击的文章所属的三级分类下的文章,按照当下点击数由高到低的选取30篇文章进入这路召回的集合。
3)基于用户行为特征的召回
如根据用户在站内的行为特征来进行召回。举个例子:我们规定用户对文章有以下行为就代表了用户的行为特征,对某篇文章点赞(1分),评论(2分),转发(3分)。
我们选取出这个用户近7天内,得分最高的5篇文章,所在的三级分类下的30篇新文章,进入这路召回的集合。
4)基于协同的召回。
空间向量模型 在说协同之前,我们先介绍一个空间向量模型。
我们把每个用户表达成了一个个的标签特征,我们想象每个标签就是一个坐标轴,每个特征的分值,就是这个特征在坐标轴上的长度。这样我们可以在一个多维坐标轴上,用一个向量来描述一个用户,代表不同用户的两个向量的夹角越小,就表示两个用户越相似。
两篇不同文章的相似度计算也是一样。具体的公式如下:

余弦相似度公式
协同
1)基于用户的协同
比如A用户和B用户向量化后很相似,那么我们认为B用户喜欢的东西,A用户也会喜欢,于是我们把B用户喜欢的东西推荐给了A用户。
2)基于内容的协同
比如A用户喜欢甲文章,甲乙文章向量化后很相似,那么我们认为乙文章A用户也会喜欢,于是我们把乙文章推荐给了A用户。
3)基于整体的协同
比如有ABC三个用户,A用户喜欢甲乙文章,B用户喜欢甲乙丙文章,C用户喜欢甲文章,于是我们认为喜欢甲文章的用户都会喜欢乙文章,于是把乙文章推荐给了C用户。
3.6 文章的排序
每路召回形成的是一个基于每个用户的文章集合,我们需要把多路集合作为输入集灌入到我们的排序模型中。
排序模型会通过模型对用户和文章的众多特征,每个特征的权重进行计算。
常用的排序模型有:LR(逻辑回归),GBDT(决策树),FM(因子分解机)等以及他们的复合变种。
经过排序之后,对于每个用户,会输出一个新闻的信息流按照排序的规则(由高到低)。
四、推荐策略
下面我们来说一下重排序,也就是上产品策略的阶段。
4.1 常见策略
我接触过的部分策略如下:
- 新用户兴趣试探策略
- 兴趣打散策略
- 本地化推荐
- 网络状态推荐
- 分时段推荐策略
- 搜索行为策略
- 负反馈策略
- 分场景策略
- 热点事件策略
- 通勤场景策略
- 季节性策略
- 流失召回策略
4.2 策略的目标
在工作中,我们都会有一个目标,为一个目标服务。比如:新闻的个性化推荐看重,uv点击率,次日留存率,用户的平均阅读时长等。
对于新用户来说:我的理解是要尽快发现他们的兴趣,把他们留下来,然后提升点击。
对于老用户来说:我的理解是要发掘他们更多的兴趣,提升他们的点击和阅读时长,减少流失。
4.3 策略案例
这里来分享1个案例:分网络状态推荐策略。
需要说明的是:这里只进行思路简述,实际策略方案会比这个更加严谨和复杂。
4.3.1 猜想与调研
猜想
从实际体验出发,当我们在无线网络下,会更肆无忌惮的去点视频图文观看,而在有线环境下会更少一些。
如果用户的行为符合这个猜想,那么在不同的网络状态调整不同类型文章的占比,可以提升用户的点击。
调研
为了验证这个猜想,我们可以做一个竞品调研。比如我们的新闻客户端是A,调研BCD三家新闻客户端在有线和无线状态下,前100条资讯,首页信息流中纯视频的数量(广告除外)
假设我们得到的结果如下图。我们发现竞品确实也做了这样的策略,那么我们需要做个ABtest来看下效果:

4.3.2 实验设计
1)网络状态:
实验组和对照组按照要求处在不同网络状态下。
2)人群划分:
圈选20w人群,多维度均匀选取等量分为4组,使4组用户同质。
3)变量控制:
只有首页信息流视频出现的比例不同这一个变量。
4)用户要求:
每个组的5w用户,只有当此用户当日有分别在有线和无线网络下浏览新闻的行为,才会被计入统计。
对照组1: 5w用户保持线上逻辑,有线和无线网络状态,首页信息流推荐视频比例相等。
对照组2: 5w用户保持线上逻辑,有线和无线网络状态,首页信息流推荐视频比例相等。
(说明:AAtest,保证实验组和对照组的变化,不是由于人群包切分或其他因素造成不同。)
实验组1: 5w用户在无线网络下推荐视频比例与对照组相同,有线网络状态下首页信息流降低5%比例的视频。
实验组2: 5w用户在无线网络下推荐视频比例与对照组相同,有线网络状态下首页信息流降低10%比例的视频。
实验组3: 5w用户在无线网络下推荐视频比例与对照组相同,有线网络状态下首页信息流降低15%比例的视频。
4.3.3 实验结果评估
1)观测指标
各个分组(按日):人均曝光量,人均点击量,人均点击率,人均阅读时长,次日留存率等。
2)实验数据观测
亲自体验线上情况,同时观测每个对照组和实验组的数据表现。
3)策略复盘
实验设计是否合理,是否引入了其他变量,策略是否在线上生效,数据是否符合预期,用户对此需求的真伪,策略总结。
#专栏作家#
大鹏,公众号:一个数据人的自留地。人人都是产品经理专栏作家《数据产品经理修炼手册》作者。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议