你在互联网平台的「喜欢」与「不喜欢」正在悄悄影响整个社会
编辑导读:互联网世界连接着每一个人,即使天各一方也近在咫尺。我们在互联网平台「喜欢」或「不喜欢」的举动,正在悄悄影响整个社会。本文作者对此进行分析,希望对你有帮助。

不要小看你在互联网平台「喜欢」或「不喜欢」的举动,它都在悄悄影响着整个社会。
在这之前,先来了解消费者心理学专家Nir Eyal在《HOOKED》一书中谈及的经典上瘾模型,设计师们设计让用户「上瘾」互联网产品服务的背后,基本原理是通过「触发-行动-多变的酬赏-投入」4个方面来养成用户的习惯。通过连续的「上瘾」循环,占领用户心智,使得用户不断投入。

▲上瘾模型
比如,你这会正无聊(内部的触发),好朋友在微信给你分享了一个有趣的视频(外部的触发)。你点开链接并观看视频,这是你的行动。在观看视频的过程中,里面幽默搞笑的内容刺激多巴胺分泌,顿时你的心情大好,这是看视频获得的奖赏。最后,你对于这种奖赏的渴求会促使你不自觉滑动手机屏幕,开始了下一个视频,这就是继续投入。

▲上瘾模型-示例
在这个循环当中,起初平台还会给你推荐一些你不喜欢的内容。但随着你的继续投入,你会发现它越来越懂你,甚至比你还了解你自己。
关于「科技成瘾」的话题已经有太多的人谈过,我想聊聊在互联网中支持其发展的推荐系统,如何通过你在互联网的表态,影响整个社会。
以下,Enjoy~
一、推荐系统中算法的力量
推荐系统(Recommendation Systems)是一项个性化信息过滤技术,它利用用户的偏好信息自动地向用户推荐符合其兴趣特点的信息对象,能够有效地解决“信息超载”带来的一些问题。
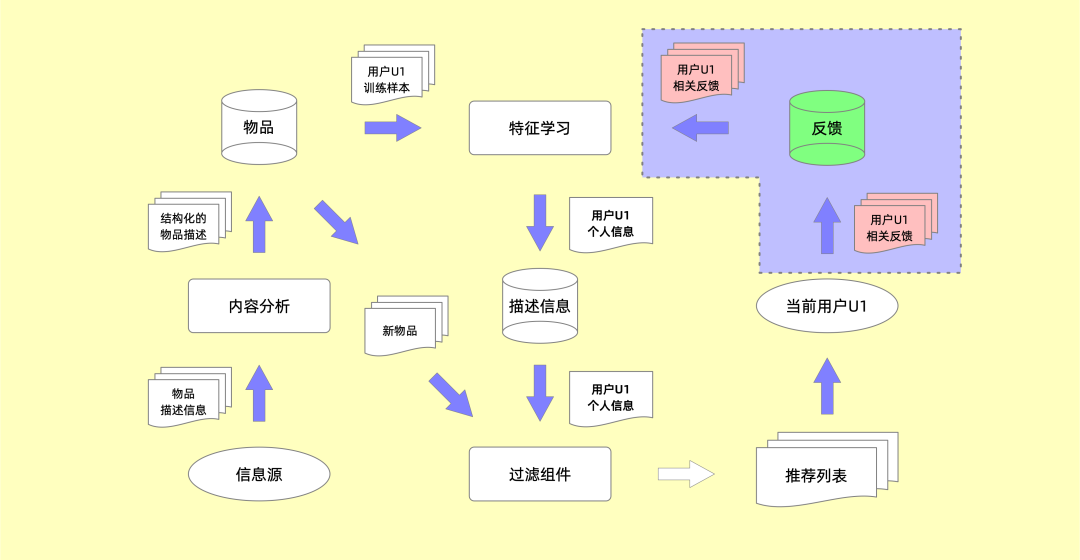
▲ 推荐系统架构| 来自《推荐系统:技术、评估及高效算法》
这个图稍微有点复杂,我大概讲一下。
目前主流推荐系统基本采用的是“基于模型的协同过滤”算法,即不断用数据为每个实体塑造出一个尽可能准确的 “多维向量模型”。通过收集用户的基础信息(比如,年龄、性别、所在城市等)和行为数据(比如,点击“喜欢”、点击“不喜欢”、 浏览时长、收藏、转发分享等),为每个用户建立一个偏好画像。基于这个偏好画像去进行特征学习和过滤,计算相似的用户,得到“近邻”,最后进行推荐。
事实上,你只需要关注右上角的部分就可以。从右上角你可以看出平台给出的「推荐列表」会经过用户的反馈,再次回流到推荐系统的模型学习和训练当中。意思就是,你在平台上的行为无时无刻都会被系统记录、学习,经过分析理解后再从海量的内容中为你产生新的专属于你的推荐列表。
对于上图右上角的反馈流程,推荐系统关键在于区分两种类型的相关性反馈:正反馈(用户喜欢的特征)和负反馈(用户不喜欢的特征)。利用二元化机制可以将推荐列表中的内容划分为“相关”或“不相关”两大类。
在这种机制的长期运行下,人们的生活会被算法的力量,一步步蚕食。算法并无道德可言,它只关心人们感兴趣的内容,而推动它的唯一动力则是商业利益。
正如Elon Musk所说,需要对机器人时刻保持警惕,以免沦为机器的奴役或灭绝。
二、互联网世界的理想国
现在各大平台通过算法通过收集用户的喜好和标签,你越喜欢什么就越给你推荐什么。这种「上瘾」机制浅层刺激的「爽」,是科技公司和多巴胺的一场共谋,是新时代的慢性毒药,让人们深陷其中,无法自拔。
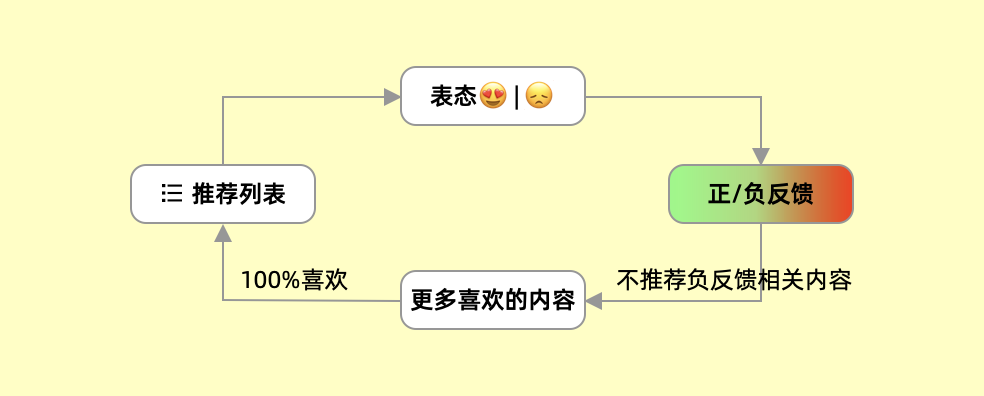
▲推荐-增强回路
今日头条的CEO张一鸣说:“我们不需要主编,有主编就会有倾向性,我们把分发交给算法,用户喜欢什么,我们就推给用户什么。我们不干预用户的喜好。”
对于算法来说,每次互动都是完善模型的有效数据,用户使用得越频繁,推荐的内容就越准确。在极致的情况下,有可能推荐的内容100%都是用户喜欢的。但这种由智能推荐来决定分发信息的方式,最终会使得相近群体的用户无限「趋同」,这个趋同不仅体现在所获取的信息上,还有被信息长时间影响下的思维和价值观念。
算法的设计逻辑是以无限满足人性偏好为标准,当然也包括人性的各种阴暗面都被激活并满足。与此同时,对于一些真正有价值的内容,会被彻底淹没。好比,大街上有位哲学家在演讲,旁边有两个女人在打架,你更愿意去看哪个?
算法实际上垄断了数据的收集和构建方式,以海量的信息构建一个框架,引领和影响众人的决策以及偏好。这种力量如果不加规范,没有任何约束,后果堪忧。如果有一天算法被利用,一而再,再而三给人们推送虚假的信息,那些被算法捆绑的用户,是否能分辨、从而摆脱算法呢?
事实上,这种任由智能推荐发展起来的互联网理想国,我认为急需得当的人为干预,而这种干预要能代表社会的正向价值观。此外,为了避免极端的马太效应,热门的内容越来越热门,冷门的内容越来越冷门。还需有效机制,让分发的内容避免趋同的前提下,带有正向价值观的偏见。
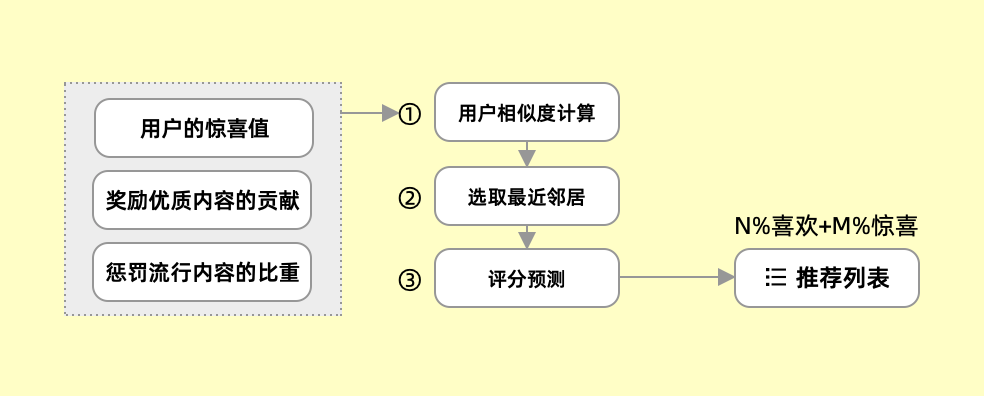
▲推荐-惊喜机制
对于用户而言,就算再喜欢某些内容,也不会只喜欢这类型内容。对于产品推荐的内容,需要在用户喜欢的基础之上,借助人为干预超越已知期望探索「惊喜」。
在协同过滤个性化推荐产生推荐列表的机制下,由于用户评分矩阵极端稀疏等原因,有学者提出了一种基于惊喜度的协同过滤改进算法,算法对于用户的惊喜值、奖励优质项目的贡献、惩罚流行项目的比重,对相似度计算公式进行改进,生成更加合理的邻居用户集,充分权衡推荐内容的惊喜度与准确度。
三、信息茧房的微光
最早在2001年,哈佛大学Cass Sunstein教授在《信息乌托邦-众人如何生产知识》一书中提出,人类社会存在一种“信息茧房”现象。他认为在信息爆炸的互联网时代,人们更倾向于只接受自己感兴趣的信息,长期的信息偏食无异于作茧自缚,久而久之接触的信息就越来越局限,人就像被桎梏在“信息茧房”内,失去对其他不同事物的了解能力和接触机会。
在这个时代看似每个人都可以随意获取信息,事实上却是一个信息牢笼,你以为你想看到的,是别人刻意给你看到的。以为什么都能看见,却越什么都看不见。
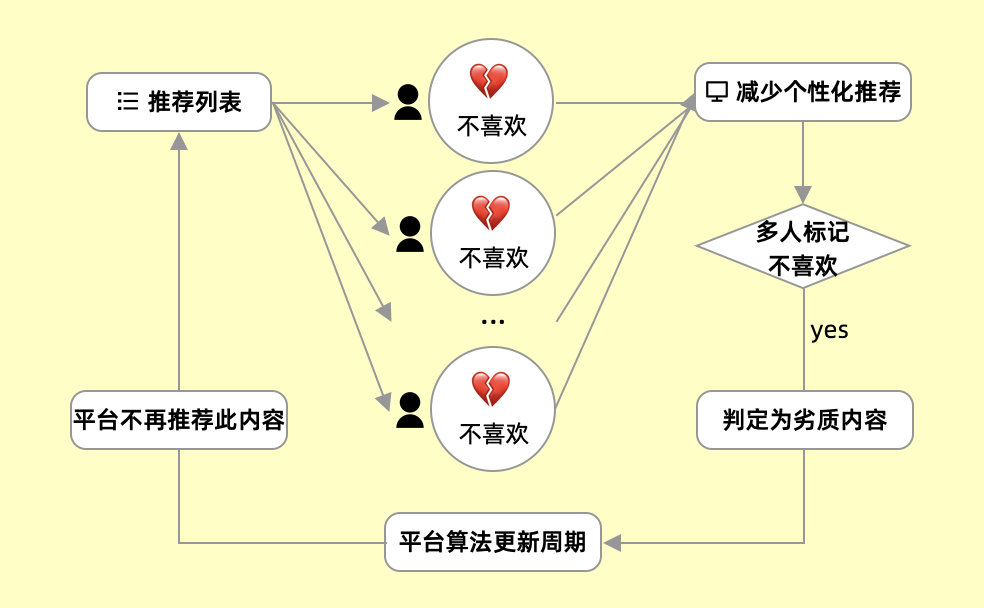
▲负反馈的连锁反应
在前面讨论智能推荐的信息分发,让用户只看到他想看的内容。对于「不喜欢」的内容,系统会根据用户的喜好,减少个性化的推荐,甚至不推荐。「不喜欢」一般来说在算法中的影响是局部的,受到影响的只是单个用户。但了解过推荐系统智能推荐背后“近邻”的逻辑后,你还会认为你的「不喜欢」只是个人行为吗?
对于推荐列表的内容,面对单个用户标记「不喜欢」,并不会对内容的展现有太多的影响。但是多个用户都标记了呢,事实上,在这样的情况下,系统会自动判定为“劣质内容”,在平台算法周期性更新后,此内容将永远不会获得系统的推荐,也就是永远被淹没在信息的海洋。
一开始,我也认为这样的逻辑并无不合理之处。直到有一天坐车,我在汽车电台听到这样一个故事,让我陷入了反思。
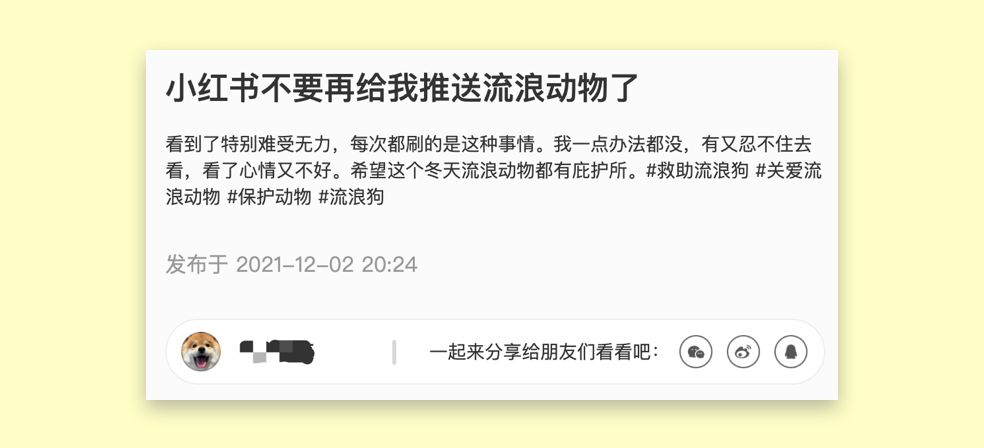
▲用户反馈| 截取小红书
事情是这样的,一位非常喜欢动物的小红书用户,平时会比较关注流浪动物的信息。久而久之,每当这位用户打开小红书,feed流全是这样的信息。这让他非常难过,看到这么多的流浪动物被弃养,无家可归,经常看到这类信息,自己却无能为力。
迫于无奈,发出了「小红书不要再给我推送流浪动物」的动态。如果依据之前的逻辑,这些需要被救助的流浪动物的信息,就是被系统当成「劣质内容」,悄无声息地被淹没,这是一件多么不幸的事啊。
这是被算法支配的世界,系统只会奖励人们想看到的内容。如果大家都点击不喜欢,那么流浪动物的信息能被看到的概率就更小了。
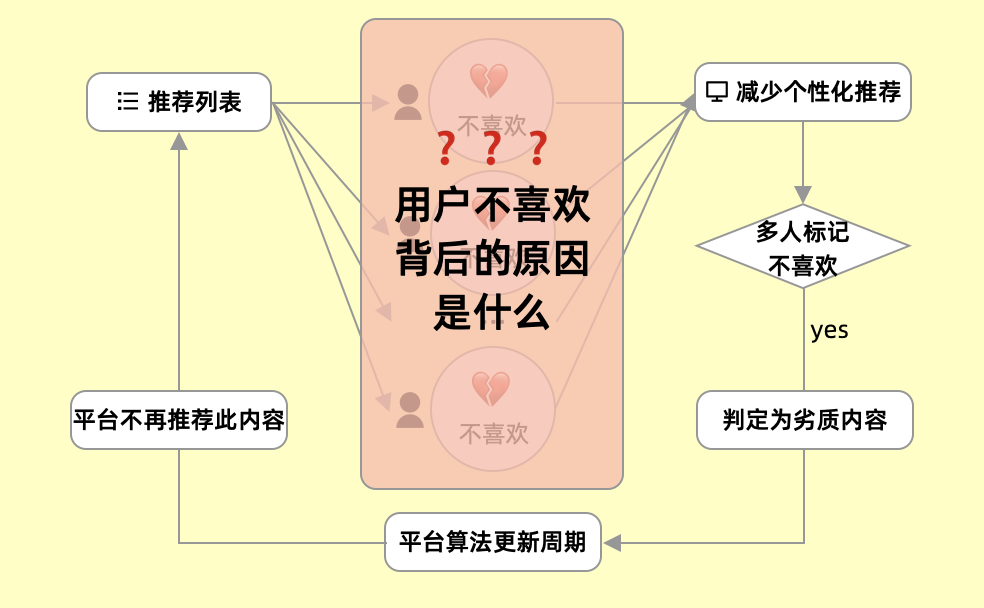
▲负反馈的背后的秘密
对于算法,它秉持的绝对理性或许并不能完成理解用户「喜欢」与「不喜欢」背后的意涵。或许算法需要进步,我们在已然存在的信息茧房中,或许也可以凭借自身的能力做些什么。总不能干等着技术自己去意识问题,自我改善吧。
我在想,是不是下次我面对这样的情况下,点上一个赞,分享转发,评论,又或者在系统多轮多次推荐类似内容的时候,主动告知平台运营团队「不喜欢」背后的深意,即便是微光。
四、总结
最后,不要小看自己在互联网上的小小举动,这就是每天发生在你生活中的「蝴蝶效应」。既然算法的世界不可避免,那有没有与它和平相处的方式呢?算法固然需要进步,那我们呢?
对于推荐系统为社会带来的便利与效益毋容置疑,在系统巨轮之下,可以对个人获取信息的渠道进行优化,把更多精力放在主动获取信息之上。
另外,建立结构化的知识体系,在信息爆炸的时代,探索更有价值的信息,而非完全愉悦自我的内容。
参考资料:
[1] 《推荐系统:技术、评估及高效算法》[2] 专栏 | 推荐系统遇上深度学习,让每一次邂逅都深入人心
[3] 产品分析 | B站-从二次元社区到综合视频社区
[4] 互动与博弈:算法推荐下短视频行业生态与发展路径
[5] 偏见的不自知涵化与助长——算法推荐机制下“过滤泡沫”
[6] 抖音点了不感兴趣还一直推荐
[7] 警惕陷入“信息茧房”
作者:龙国富,公众号:龙国富,分享用户研究、客户体验、服务科学等领域资讯,观点和个人见解。每周原创更新,与你一起探索未知。
本文由@龙国富 原创 发布于人人都是产品经理,未经授权,禁止转载。
题图来自unsplash,基于CC0协议








