如何从0到1进行KANO模型分析
编辑导语:产品经理在日常工作中会用到KANO模型分析,KANO模型主要是对用户需求分类和排序, 通过分析用户对产品功能的满意程度,来对产品的功能进行升级,从而确定产品实现过程中的优先级;本文作者分享了关于如何从0到1进行KANO模型分析,我们一起来看一下。

KANO模型是一种常用的产品需求分类及需求满意度调查的分析模型,但产品经理如何使用该模型?具体实操时又有哪些注意事项?
遍历百度和谷歌,目前这些问题都只有一般性的答复和解读,深入的细节往往不得而知;本文通过分享本人多次从0到1的KANO模型分析经验,希望能为产品同行及有学习需要的朋友们提供力所能及的帮助。
一、关于KNAO模型
KANO模型的诞生背景及详细介绍本文将不再赘述,需要的朋友请自行百度。这里仅简单介绍KANO模型中的两个核心概念:
1. 需求属性分类
通过对需求的满意度、具备度二维分析,KANO将需求划分为 必备型、期望型、魅力型、无差异型、反向型 五类,分别以英文字母 M、O、A、I、R 表示。
- 必备型需求(M):需求满足时,用户不会感到满意。需求不满足时,用户会很不满意。
- 期望型需求(O):需求满足时,用户会感到很满意。需求不满足时,用户会很不满意。
- 魅力型需求(A):该需求超过用户对产品本来的期望,使得用户的满意度急剧上升。即使表现的不完善,用户的满意度也不受影响。
- 无差异型需求(I):需求被满足或未被满足,都不会对用户的满意度造成影响。
- 反向型需求(R):该需求与用户的满意度呈反向相关,满足该要求,反而会使用户的满意度下降。
2. better-worse系数
Better系数=(期望数+魅力数)/(期望数+魅力数+必备数+无差异数)
Worse系数= -1*(期望数+必备数)/(期望数+魅力数+必备数+无差异数)
Better系数越接近1,表示该具备度越高该需求对用户满意度提升的影响效果越大 。 Worse系数越接近-1,表示具备度越低该需求对用户满意度造成的负面影响越大 。
二、KANO模型分析的全流程
介绍完上述两个核心概念后,接下来讲述KANO分析的全流程。KANO模型分析始于问卷设计,终于分析报告,从始至终经历问卷设计——问卷评审——问卷发放——问卷回收——数据分析——产出报告共6个环节。
1. 问卷设计
KNAO问卷一般包含三部分内容:
1)问卷说明
一般通过问卷背景、花费时长、信息保密三方面来展开。
2)题目介绍(产品功能点介绍)
主要对每个问题题干中的功能点及使用场景进行补充说明。例如我们想了解医生对“电话随访”功能的看法;但医生根本不了解“电话随访”什么意思,那么使用场景和功能说明就是很必要的。
示例:
Q1: “电话随访”功能:
“帮助您对于离院一周或15天的患者,通过语音电话的形式,自动对患者进行随访,并提供随访结果给您,帮助您来掌控患者的康复情况”
3)题目选项
通常采用矩阵量表的形式让用户对功能进行正面和负面评价,评价分为五个程度“我很喜欢”、“它理应如此”、“无所谓”、“勉强接受”、“我很不喜欢”。
示例:

问卷的设计可采用excel、word等办公软件设计,也可以直接使用问卷星等在线问卷工具进行设计。
问卷设计时要充分考虑答卷人的角色、身份,需要覆盖目标用户画像中的所有人群 。
2. 问卷评审
问卷设计完成后可以组织内部评审,对文案、界面、题目排列逻辑、答卷人角色等进行讨论。
3. 问卷发放
KANO问卷发放至少遵循三个原则:
1)线上线下相结合
线下发放的优势在于样本质量可控,可结合面谈的形式来完成问卷的填写,且获取的信息充足。缺点在于大规模样本的获取挑战较高,需要考虑时间、空间问题(如预约时间、跨地域访谈等等)。
线上发放的优势在于速度快、流量准、回收效率高、成本低。缺点在于问卷结果的质量无法得到有效保证。
2)样本角色周全
问卷发放之前需要对样本人群根据关系链、决策链等角色关系进行切割、划分。特别是针对B端产品时,往往不同环节的决策者对同一问题的看法不尽相同。如一款B端医疗产品在搜集医院对某项功能的满意度时,就需要关注院长、科主任、医生、护士、患者等角色的不同诉求。
3)样本量足
统计学上一般默认30个重复、且有2组平行试验得出的数据为有效数据。按照该项原则,假如我们要搜集医院对某项功能的满意度时,通过划分院长、科主任、医生、护士、患者5种角色,每种角色至少有30个样本重复,且进行2组平行试验,那么样本总量至少需要30*5*2=300个。
问卷正式发放之前可进行小规模的预发放,检查问卷的使用、填写及结果是否有误。
4. 问卷回收
问卷回收的目的在于结果统计、数据分析,因此无论是线下还是线上,回收以后都需要整理成excel表格形式进行分析。
5. 问卷分析
问卷结果分析的目的在于通过统计用户对功能进行正面和负面评价,来对需求进行属性划分。
第一步:制作分析表
- 针对问卷中的功能点,从正面评价、负面评价列出5*5的统计表。
- 将“我很喜欢”、“它理应如此”、“无所谓”、“勉强接受”、“我很不喜欢”分别用数字1、2、3、4、5标记。
- 根据KANO需求属性原则,将该表分为6类属性:可疑(Q)、魅力(A)、期望(O)、无差异(I)、反向(R)、必备(M)。并分别以不同的背景色标注,便于统计。如下图所示:

第二步:根据分析表整理问卷结果
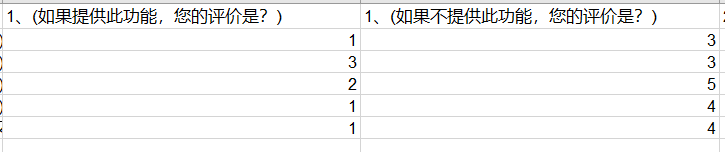
根据“我很喜欢”、“它理应如此”、“无所谓”、“勉强接受”、“我很不喜欢”的数字替换原则,分别在问卷选项结果中用数字进行替换。
例如针对第一道题:“如果提供此功能,您的评价是?”用户选择了“我很喜欢”,则替换为1。“如果不提供此功能,您的评价是?”用户选择了“无所谓”,则替换为3。那么该用户对第一道题的满意度组合即为(1,3);按照该方法,对所有问题的所有选项进行数字替换(如下图示例),并将各项组合的数量填入分析表中。
第三步:将结果代入分析表,计算better系数和worse系数绝对值
每一题各项组合的数量填入分析表中后,按照以下公式进行计算:
Q=n(1,1)+n(5,5)
A=n(1,2)+n(1,3)+n(1,4)
O=n(1,5)
I=n(2,2)+n(2,3)+n(2,4)+n(3,2)+n(3,3)+n(3,4)+n(4,2)+n(4,3)+n(2,4)
R=n(2,1)+n(3,1)+n(4,1)+n(5,1)+n(5,2)+n(5,3)+n(5,4)
M=n(2,5)+n(3,5)+n(4,5)
Better系数=(A+O)/(A+O+M+I)
Worse系数绝对值=(O+M)/(A+O+M+I)
上述公式中,n(x,y)表示数字组合为(x,y)的数量。计算之后我们就能得出better系数和worse系数绝对值用于制作象限图。

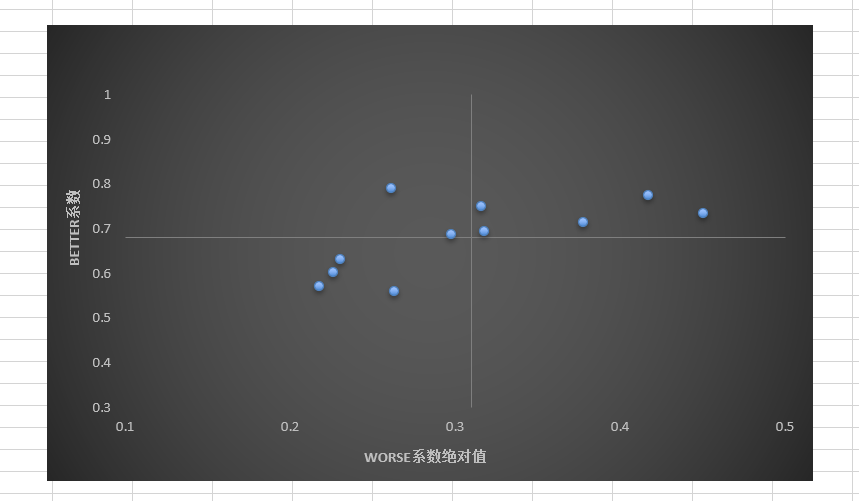
第四步:根据better系数和worse系数绝对值制作象限图
汇总各个功能点的better系数和worse系数,并计算均值,如下图所示:

在excel表中以worse系数绝对值作为x轴,以better系数作为y轴,以均值作为中心点,绘制四象限:
第五步:补充详细图中的原始选项信息,使其可视化
将象限图复制到ppt中,对四象限中每个点所代表的功能进行标注,整理成如下样式:
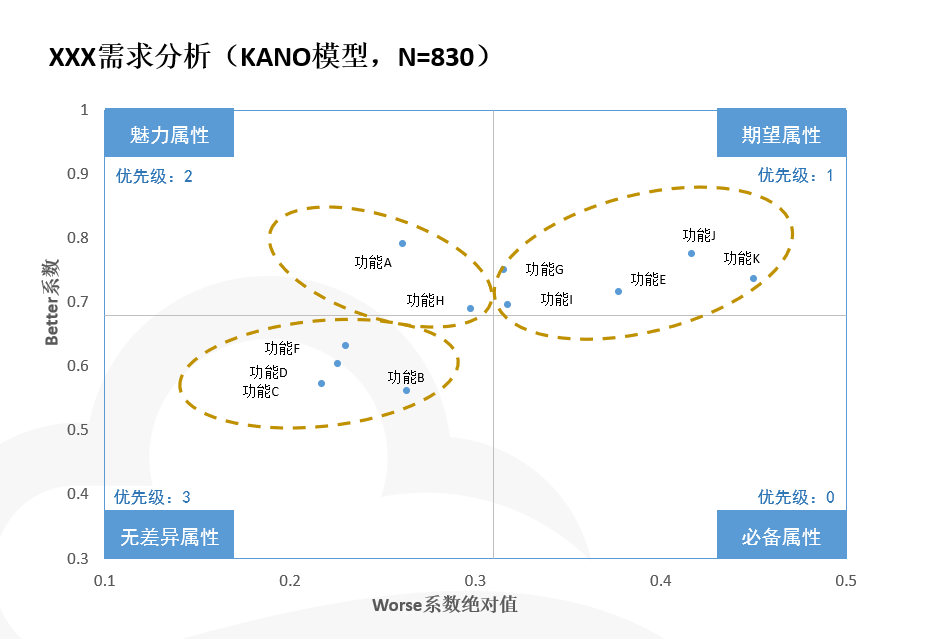
同时对四象限分别标注为魅力属性、期望属性、无差异属性、必备属性。
最后可列出个人建议的开发优先级,按0-3进行依次排序。
6.产出报告
将ppt中美化后的四象限图保存为图片,插入正式报告中,并辅以文字说明和解释,使阅读者能一目了然各项元素及其所代表的意义。
7.注意事项
在问卷回收以后,KANO分析中耗时最多一环即结果各项组合的统计。
当样本总数不超过一百时,人力统计尚可,但当样本数量成百上千乃至上万时人力便无法高效完成;此时建议产品人员寻求数据开发人员的支持,将组合数的统计以及better系数和worse系数绝对值的计算以程序的方式批量完成。
另外,四象限坐标轴里中轴线的位置未见有统一的规定;为方便比较各功能点之间的相互关系,并方便制图,个人一般采用的是取better系数和worse系数绝对值两项的均值作为定位。
如果不使用这种策略,使用其他方式,如(0,0)作为中轴线的定位,那么各功能点的属性在四象限中会发生相应的变化;这一点还需分析人员注意到,并思考最适合的形式来作图。
最后,以上内容皆为个人实操经验所得,如果不足之处还请诸位指出,共同学习讨论。
作者:王泽,微信公众号:王泽说产品
本文由 @王泽 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议